
Video captioning has become increasingly important for content understanding, retrieval, and training foundation models for video-related tasks. Despite its importance, generating accurate, detailed, and descriptive video captions is challenging in fields like computer vision and natural language processing. Various key obstacles hinder progress in this area. One such example is the scarcity of high-quality data as the data from the internet are inaccurate and large datasets are very expensive. Moreover, video captioning is inherently more complex than image captioning due to temporal correlations and camera motion. The lack of established benchmarks and the critical need for correctness in safety-critical applications make this challenge more complex in this domain.
Recent advancements in visual language models have improved image captioning, however, these models face challenges with video captioning due to temporal complexities. The video-specific models like PLLaVa, Video-llava, and Video-LLama have been developed to address this challenge. Their techniques include parameter-free pooling, joint image-video training, and audio input processing. Researchers have also explored using large language models (LLMs) for summarization tasks, as shown by LLaDA and OpenAI’s re-captioning method. Despite these advancements, this field needs an established benchmark and the critical need for accuracy in safety-sensitive applications.
Researchers from NVIDIA, UC Berkeley, MIT, UT Austin, University of Toronto, and Stanford University have proposed Wolf, a WOrLd summarization Framework for accurate video captioning. Wolf uses a mixture-of-experts approach, utilizing both image and video Vision Language Models (VLMs) to capture different levels of information and efficiently summarize. The framework is developed to enhance video understanding, auto-labeling, and captioning. The researchers introduced CapScore, an LLM-based metric that evaluates the similarity and quality of generated captions compared to the ground truth. Wolf outperforms current state-of-the-art methods and commercial solutions, significantly boosting CapScore in challenging driving videos.
Wolf’s evaluation uses four datasets: 500 Nuscences Interactive Videos, 4,785 Nuscences Normal Videos, 473 general videos, and 100 robotics videos. The proposed CapScore metric evaluates caption similarity to the ground truth. The proposed method is compared with state-of-the-art methods including CogAgent, GPT-4V, VILA-1.5, and Gemini-Pro-1.5. Image-level methods like CogAgent and GPT-4V process sequential frames, while video-based methods such as VILA-1.5 and Gemini-Pro-1.5 handle full video inputs. A consistent prompt is used across all the models, focusing on expanding visual and narrative elements, especially motion behavior.
The results indicate that Wolf outperforms state-of-the-art approaches in video captioning. While GPT-4V is better in scene recognition, it struggles with temporal information. Gemini-Pro-1.5 captures some video context but lacks detail in motion description. In contrast, Wolf efficiently captures scene context and detailed motion behaviors, such as vehicles moving in different directions and responding to traffic signals. Quantitatively, Wolf outperforms current methods, like VILA1.5, CogAgent, Gemini-Pro-1.5, and GPT-4V. In challenging driving videos, Wolf improves CapScore by 55.6% in quality and 77.4% in similarity compared to GPT-4V. These results underscore Wolf’s ability to provide more comprehensive and accurate video captions.
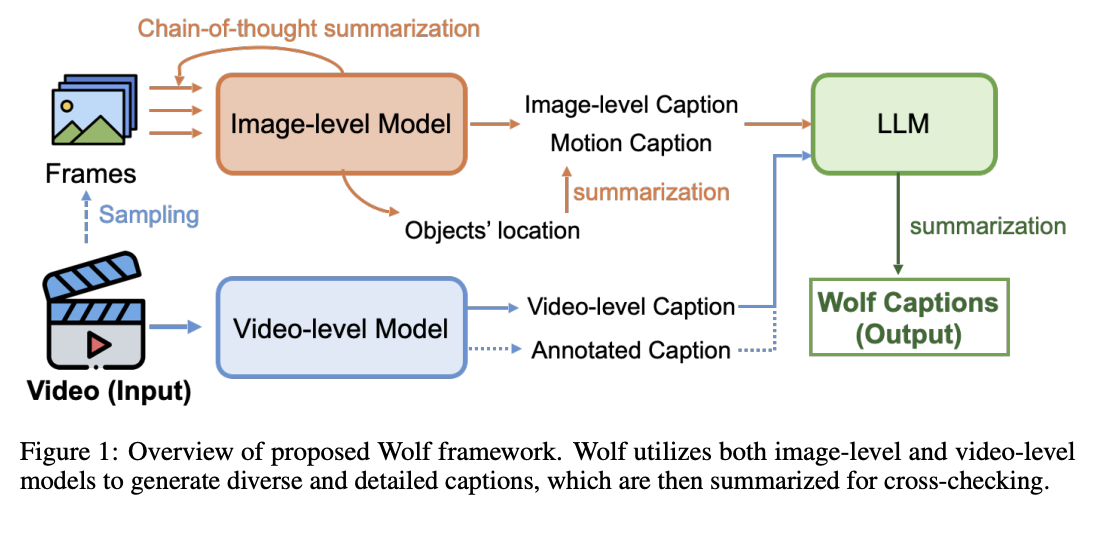
In conclusion, researchers have introduced Wolf, a WOrLd summarization Framework for accurate video captioning. Wolf represents a significant advancement in automated video captioning, combining captioning models and summarization techniques to produce detailed and correct descriptions. This approach allows for a comprehensive understanding of videos from various perspectives, particularly excelling in challenging scenarios like multiview driving videos. Researchers have established a leaderboard to encourage competition and innovation in video captioning technology. They also plan to create a comprehensive library featuring diverse video types with high-quality captions, regional information such as 2D or 3D bounding boxes and depth data, and multiple object motion details.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.


