[ad_1]
Grokking is a newly developed phenomenon where a model starts to generalize well long after it has overfitted to the training data. It was first seen in a two-layer Transformer trained on a simple dataset. In grokking, generalization occurs only after many more training iterations than overfitting. This requires high computational resources, making it less practical for most machine learning practitioners with limited resources. To fully understand this unusual behavior, there is a need for faster generalization in these overfitting systems. The main aim is to speed up the grokking phenomenon.
An existing method, grokking is a newly discovered phenomenon that shows that overparameterized neural networks can generalize and reason beyond just memorizing the dataset. Most research focuses on understanding this mechanism, linking grokking to the double descent phenomenon, where validation error first increases and then decreases as model parameters grow. Apart from this method, optimization techniques are used in which a model’s generalization patterns vary significantly with different optimization methods like mini-batch training, choice of optimizer, weight decay, noise injection, dropout, and learning rate all affect the model’s grokking pattern.
Researchers from the Seoul National University, Korea introduced GROKFAST, an algorithm that accelerated grokking by amplifying slow gradients. Researchers proved through experiments that GROKFAST algorithms have the potential to solve a wide variety of tasks that contain images, languages, and graphs. This makes the unique artifact of immediate generalization practically useful. Further, the parameter trajectories under gradient descent are split into two components: the fast-varying, overfitting-yielding component and the slow-varying, generalization-inducing component. This analysis helps the grokking method to become 50 times faster with only a few lines of code.
During the experiment, the idea of the algorithmic dataset used in the first report on grokking is shown, where the network is a two-layer decoder-only transformer trained to predict the answer of a modular binary multiplication operation. Comparing the time to reach an accuracy of 0.95, the validation accuracy keeps improving longer. It reaches its peak 97.3 times later than the training accuracy, which quickly reaches its maximum and starts overfitting. Further, hyperparameters are selected from a simple grid search, and found that the filter works best when λ(scalar factor) = 5 and w(window size) = 100. Also, there is a reduction of 13.57 times in the number of iterations to reach the validation accuracy of 0.95, which is a good result.
The proposed method is based on the idea that slow gradients (low-pass filtered gradient updates) help in generalization. The training dynamics of a model are interpreted under grokking as a state transition, where the model goes through three stages:
- Initialized, where both the training and validation losses are not saturated
- Overfitted, where the training loss is completely saturated but validation loss is not saturated
- Generalized, where both losses are saturated.
Moreover, research suggests that the weight decay hyperparameter significantly plays a critical role in the grokking phenomenon.
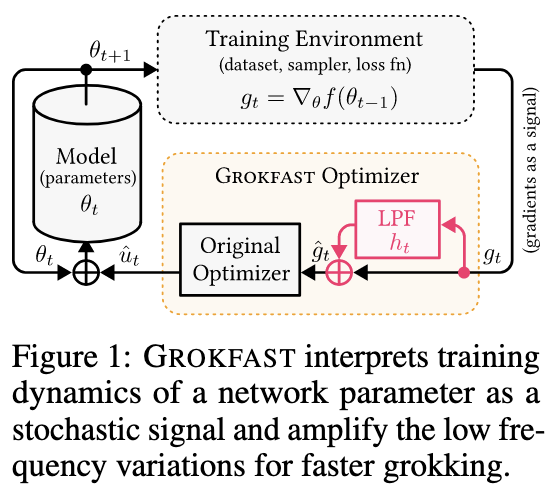
In conclusion, researchers from the Seoul National University, Korea have proposed an algorithm, GROKFAST, that accelerated grokking phenomenon by amplifying slow gradients. The analysis of how each model parameter changes into a random signal during training iteration helps to separate gradient updates into fast-varying and slow-varying components. Despite showing outstanding results, there is a limit in the utilization by GROKFAST that needs w times more memory to store all the previous gradients. Also replication of the model parameters also makes the training slower.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
[ad_2]
Source link