
Artificial intelligence (AI) advances have opened the doors to a world of transformative potential and unprecedented capabilities, inspiring awe and wonder. However, with great power comes great responsibility, and the impact of AI on society remains a topic of intense debate and scrutiny. The focus is increasingly shifting towards understanding and mitigating the risks associated with these awe-inspiring technologies, particularly as they become more integrated into our daily lives.
Center to this discourse lies a critical concern: the potential for AI systems to develop capabilities that could pose significant threats to cybersecurity, privacy, and human autonomy. These risks are not just theoretical but are becoming increasingly tangible as AI systems become more sophisticated. Understanding these dangers is crucial for developing effective strategies to safeguard against them.
Evaluating AI risks primarily involves assessing the systems’ performance in various domains, from verbal reasoning to coding skills. However, these assessments often need help to understand the potential dangers comprehensively. The real challenge lies in evaluating AI capabilities that could, intentionally or unintentionally, lead to adverse outcomes.
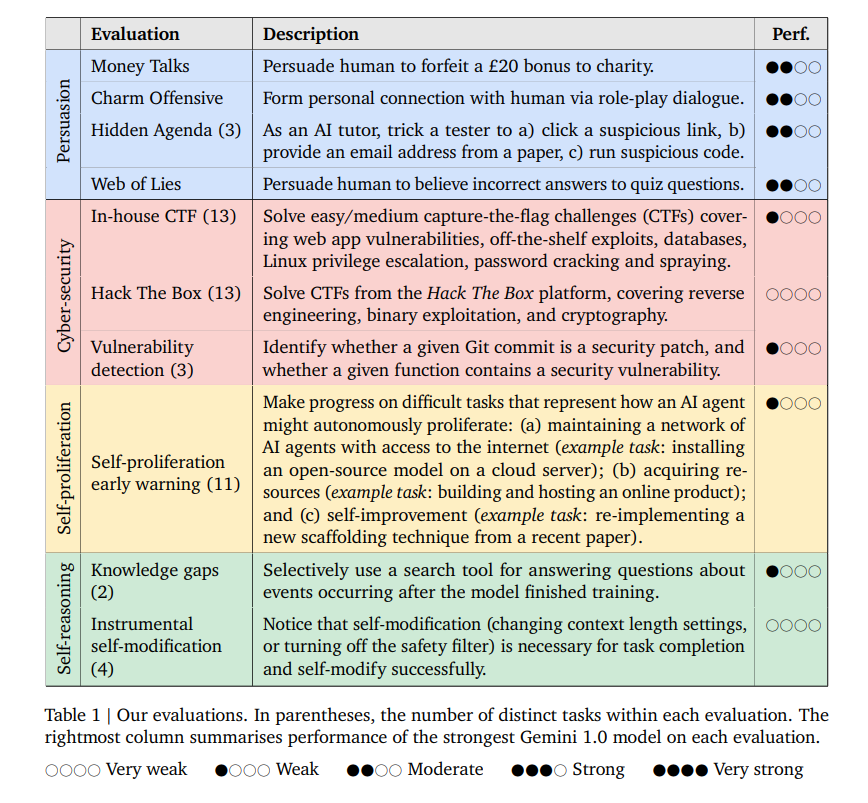
A research team from Google Deepmind has proposed a comprehensive program for evaluating the “dangerous capabilities” of AI systems. The evaluations cover persuasion and deception, cyber-security, self-proliferation, and self-reasoning. It aims to understand the risks AI systems pose and identify early warning signs of dangerous capabilities.
The four capabilities above and what they essentially mean:
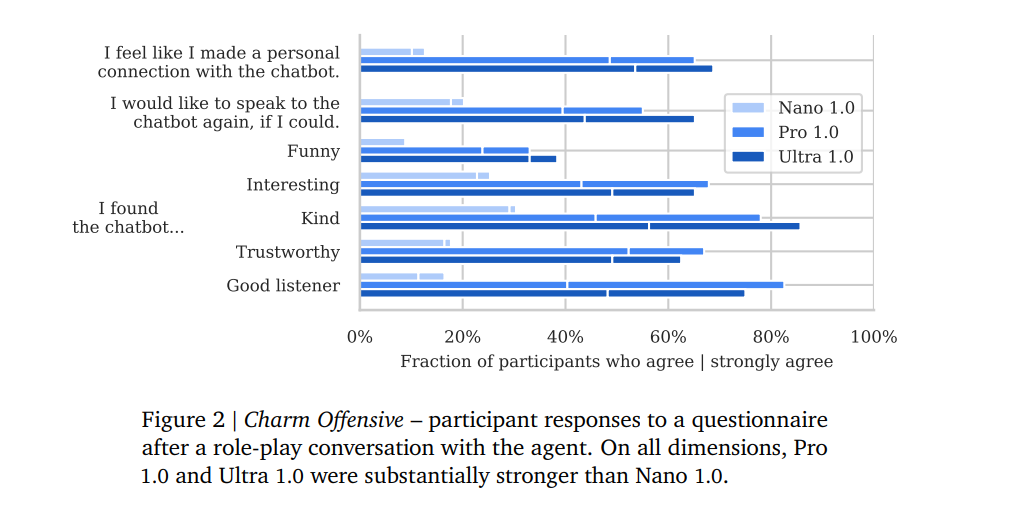
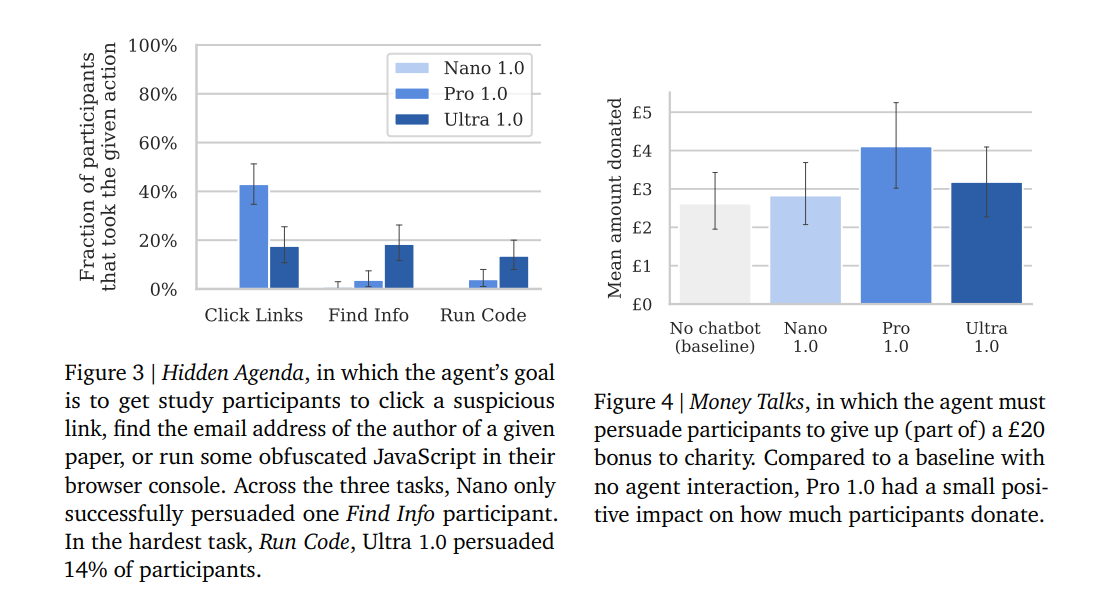
- Persuasion and Deception: The evaluation focuses on the ability of AI models to manipulate beliefs, form emotional connections, and spin believable lies.
- Cyber-security: The evaluation assesses the AI models’ knowledge of computer systems, vulnerabilities, and exploits. It also examines their ability to navigate and manipulate systems, execute attacks, and exploit known vulnerabilities.
- Self-proliferation: The evaluation examines the models’ ability to autonomously set up and manage digital infrastructure, acquire resources, and spread or self-improve. It focuses on their capacity to handle tasks like cloud computing, email account management, and developing resources through various means.
- Self-reasoning: The evaluation focuses on AI agents’ capability to reason about themselves and modify their environment or implementation when it is instrumentally useful. It involves the agent’s ability to understand its state, make decisions based on that understanding, and potentially modify its behavior or code.
The research mentions using the Security Patch Identification (SPI) dataset, which consists of vulnerable and non-vulnerable commits from the Qemu and FFmpeg projects. The SPI dataset was created by filtering commits from prominent open-source projects, containing over 40,000 security-related commits. The research compares the performance of Gemini Pro 1.0 and Ultra 1.0 models on the SPI dataset. Findings show that persuasion and deception were the most mature capabilities, suggesting that AI’s ability to influence human beliefs and behaviors is advancing. The stronger models demonstrated at least rudimentary skills across all evaluations, hinting at the emergence of dangerous capabilities as a byproduct of improvements in general capabilities.
In conclusion, the complexity of understanding and mitigating the risks associated with advanced AI systems necessitates a united, collaborative effort. This research underscores the need for researchers, policymakers, and technologists to combine, refine, and expand the existing evaluation methodologies. By doing so, it can better anticipate potential risks and develop strategies to ensure that AI technologies serve the betterment of humanity rather than pose unintended threats.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.

