
The emergence of Large Vision-Language Models (LVLMs) characterizes the intersection of visual perception and language processing. These models, which interpret visual data and generate corresponding textual descriptions, represent a significant leap towards enabling machines to see and describe the world around us with nuanced understanding akin to human perception. A notable challenge that impedes their broader application is the phenomenon of hallucination instances where there’s a disconnect between the visual data and the text generated by the model. This issue raises concerns about the reliability and accuracy of LVLMs in critical applications.
Researchers from the IT Innovation and Research Center at Huawei Technologies explore the intricacies of LVLMs’ tendency to produce hallucinatory content where the text does not accurately reflect the visual input. This misalignment often results from limitations in the models’ design and training data, which can bias the models’ output or hinder their ability to grasp the full context of the visual information.
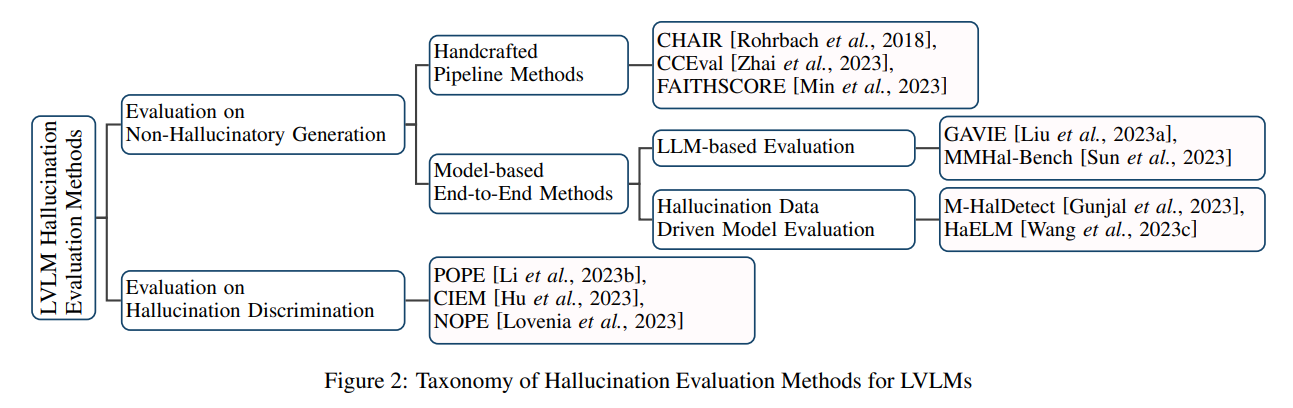
The research team proposes various innovative strategies to refine the core components of LVLMs. These include developing advanced data processing techniques that enhance the quality and relevance of training data, thus providing a more solid foundation for the models’ learning processes. Moreover, the researchers introduce novel architectural improvements, such as optimizing the visual encoders and modality alignment mechanisms. These enhancements ensure that the models can more effectively integrate and process the visual and textual information, significantly reducing hallucinatory outputs.
The researchers’ methodology encompasses evaluating LVLMs across various benchmarks designed to measure the prevalence of hallucinations in model outputs specifically. Through these evaluations, the team identifies key factors contributing to hallucination, including the visual encoders’ quality, the modality alignment’s effectiveness, and the models’ ability to maintain context awareness throughout the generation process. The researchers develop targeted interventions that significantly improve the models’ performance by addressing these factors.
In assessing the performance of LVLMs post-implementation of the proposed solutions, the researchers report a marked improvement in the accuracy and reliability of the generated text. The models demonstrate an enhanced ability to produce descriptions that closely mirror the factual content of images, thereby reducing instances of hallucination. These results highlight the potential of LVLMs to transform various sectors, from automated content creation to assistive technologies, by providing more accurate and trustworthy machine-generated descriptions.

The research team offers a critical analysis of the current state of LVLMs, acknowledging the progress made and pointing towards areas requiring further exploration. The study concludes by emphasizing the importance of continued innovation in data processing, model architecture, and training methodologies to realize the full potential of LVLMs. This comprehensive approach advances the field of artificial intelligence. It lays the groundwork for developing LVLMs that can reliably interpret and narrate the visual world, bringing us closer to creating machines with a deep, human-like understanding of visual and textual data.
This exploration into the realm of LVLMs and the challenge of hallucination reflects a significant step by meticulously addressing the roots of the problem and proposing effective solutions, the research opens up new avenues for the practical application of LVLMs, paving the way for advancements that could revolutionize how machines interact with the visual world. The commitment to overcoming the challenge of hallucination not only enhances the reliability of LVLMs but also signals a promising direction for future research in artificial intelligence, with the potential to unlock even more sophisticated and nuanced interactions between machines and the visual environment.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.

