
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. Training these models, however, is challenging. The computational intensity required and the potential for various failures during extensive training periods necessitate innovative solutions for efficient management and recovery.
A key challenge in the field is the management of the training and recovery processes of LLMs. These models, often trained on expansive GPU clusters, face a range of failures, from hardware malfunctions to software glitches. While diverse in approach, traditional methods need to address the complexity of these failures comprehensively. Techniques like checkpointing, designed to save the training state periodically, and strategies including elastic training and redundant computation, mainly address individual aspects of LLM training failures. However, they need an integrated approach for holistic failure management.
Meet ‘Unicron,’ a novel system that Alibaba Group and Nanjing University researchers developed to enhance and streamline the LLM training process. Integrated with NVIDIA’s Megatron, known for its robust transformer architecture and high-performance training capabilities, Unicron introduces innovative features aimed at comprehensive failure recovery. This integration not only leverages Megatron’s advanced optimizations but also adds new dimensions to the training resilience of LLMs.
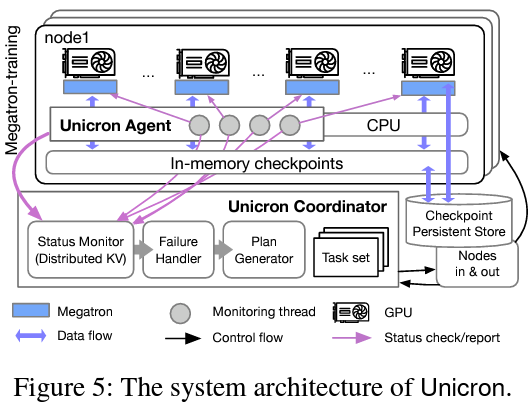
Unicron’s methodology is an embodiment of innovation in LLM training resilience. It adopts an all-encompassing approach to failure management, characterized by in-band error detection, dynamic plan generation, and a rapid transition strategy. The system’s error detection mechanism is designed to identify and categorize failures during execution promptly. Once a failure is detected, Unicron initiates a series of corrective actions tailored to the specific nature of the failure. A key feature of Unicron is its cost-aware plan generation mechanism, which aids in configuring the most optimal recovery plan. This is informed by a model considering the variety of tasks within a cluster, ensuring economic efficiency in resource utilization. Furthermore, the system’s transition strategy is built to minimize the duration of system transitions by leveraging partial results from ongoing training iterations, thus enhancing overall training continuity.
In terms of performance and results, Unicron demonstrates a remarkable increase in training efficiency. The system consistently outperforms traditional solutions like Megatron, Bamboo, Oobleck, and Varuna. Performance gains up to 1.9 times compared to state-of-the-art solutions were observed, underlining Unicron’s superiority in diverse training scenarios. Unicron’s ability to reconfigure tasks dynamically in response to failures is particularly noteworthy, a feature that sets it apart from its counterparts. This reconfiguration capability, coupled with the system’s self-healing features, enables Unicron to manage multiple tasks within a cluster efficiently, thereby maximizing resource utilization and training efficiency.
In conclusion, the development of Unicron marks a significant milestone in LLM training and recovery. Unicron paves the way for more efficient and reliable AI model development by addressing the critical need for resilient training systems. Its comprehensive approach to failure management, combining rapid error detection, cost-effective resource planning, and efficient transition strategies, positions it as a transformative solution in large-scale language model training. As LLMs grow in complexity and size, systems like Unicron will play an increasingly vital role in harnessing their full potential, driving the frontiers of AI and NLP research forward.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, Twitter, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.

