
Modern self-driving systems frequently use Large-scale manually annotated datasets to train object detectors to recognize the traffic participants in the picture. Auto-labeling methods that automatically produce sensor data labels have recently gained more attention. Auto-labeling may provide far bigger datasets at a fraction of the expense of human annotation if its computational cost is less than that of human annotation and the labels it produces are of comparable quality. More precise perception models may then be trained using these auto-labeled datasets. Since LiDAR is the main sensor used on many self-driving platforms, they use it as input after that. Furthermore, they concentrate on the supervised scenario in which the auto-labeler may be trained using a collection of ground-truth labels.
This issue setting is also known as offboard perception, which does not have real-time limitations and, in contrast to onboard perception, has access to future observations. As seen in Fig. 1, the most popular model addresses the offboard perception problem in two steps, drawing inspiration from the human annotation procedure. Using a “detect-then-track” framework, objects and their coarse bounding box trajectories are first acquired, and each object track is then refined independently. Tracking as many objects in the scene as possible is the primary objective of the first stage, which aims to obtain high recall. On the other hand, the second stage concentrates on track refining to generate higher-quality bounding boxes. They call the second step “trajectory refinement,” which is the subject of this study.
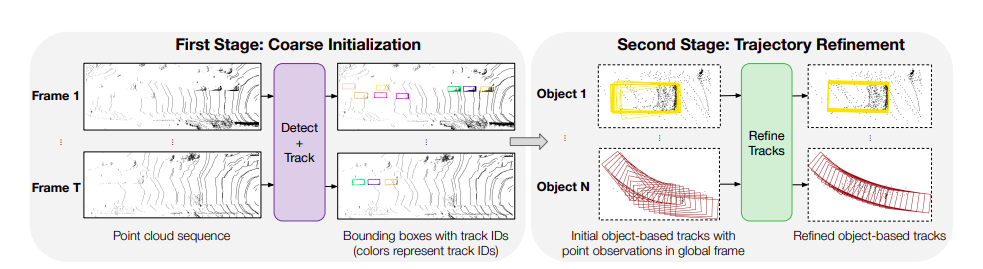
Figure 1: Auto-labelling paradigm in two stages. The detect-then-track paradigm is used in the first step to collect trajectories of coarse objects. Every trajectory is separately refined in the second step.
Managing object occlusions, sparsity of observations as the range grows, and objects’ various sizes and motion patterns make this work difficult. To address these issues, a model that can efficiently and effectively utilize the temporal context of the complete object trajectory must be designed. Nevertheless, current techniques are inadequate as they are intended to handle dynamic object trajectories in a suboptimal sliding window manner, applying a neural network individually at every time step within a restricted temporal context to extract characteristics. This could be more efficient since features are repeatedly retrieved from the same frame for several overlapping windows. Consequently, the structures take advantage of relatively little temporal context to stay inside the computational budget.
Moreover, earlier efforts used complex pipelines with several distinct networks (e.g., to accommodate differing handling of static and dynamic objects), which are difficult to construct, debug, and maintain. Using a different strategy, researchers from Waabi and University of Toronto provide LabelFormer in this paper a straightforward, effective, and economical trajectory refining technique. It produces more precise bounding boxes by utilizing the entire time environment. Furthermore, their solution outperforms the current window-based approaches regarding computing efficiency, providing auto-labelling with a distinct edge over human annotation. To do this, they create a transformer-based architecture using self-attention blocks to take advantage of dependencies over time after individually encoding the initial bounding box parameters and the LiDAR observations at each time step.
Their approach eliminates superfluous computing by refining the complete trajectory in a single shot, so it only has to be used once for each item tracked during inference. Their design is also far simpler than previous methods and handles static and dynamic objects easily. Their comprehensive experimental assessment of highway and urban datasets demonstrates that their method is quicker than window-based methods and produces higher performance. They also show how LabelFormer can auto-label a bigger dataset to train downstream item detectors. This leads to more accurate detections than when preparing human data alone or with other auto-labelers.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.

