The challenge of training large and sophisticated models is significant, primarily due to the extensive computational resources and time these processes require. This is particularly evident in training large-scale Generative AI models, which are prone to frequent instabilities manifesting as disruptive loss spikes during extended training sessions. Such instabilities often lead to costly interruptions that necessitate pausing and restarting the training process, a challenge noted in models as expansive as the LLaMA2’s 70-billion parameter model, which required over 1.7 million GPU hours.
The root of these instabilities is often traced back to numeric deviations—small, cumulative errors in the computation process that can lead to significant deviations from expected training outcomes. Researchers have explored various optimization methods, including the Flash Attention technique, which aims to reduce the computational overhead in transformer models, a widely recognized bottleneck.
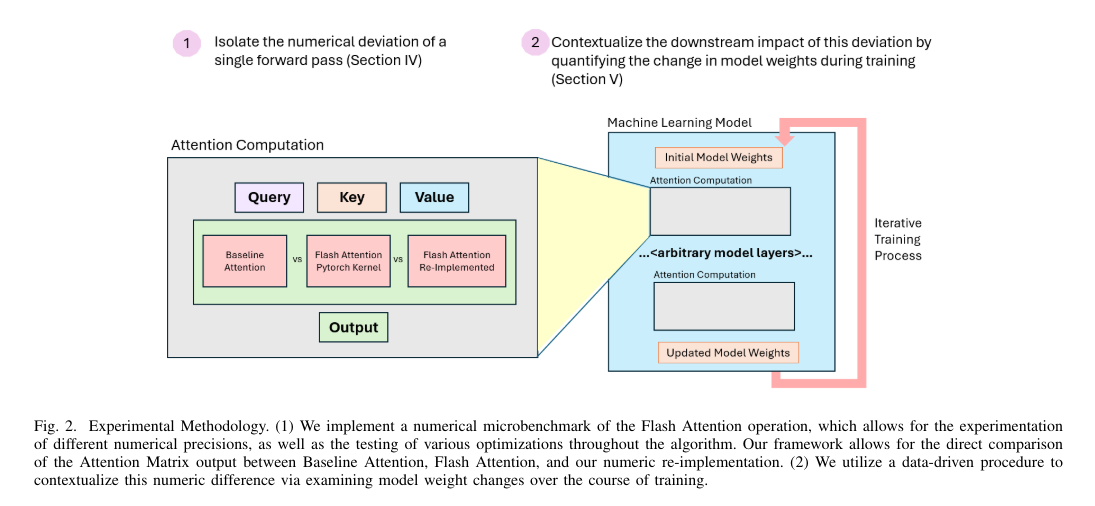
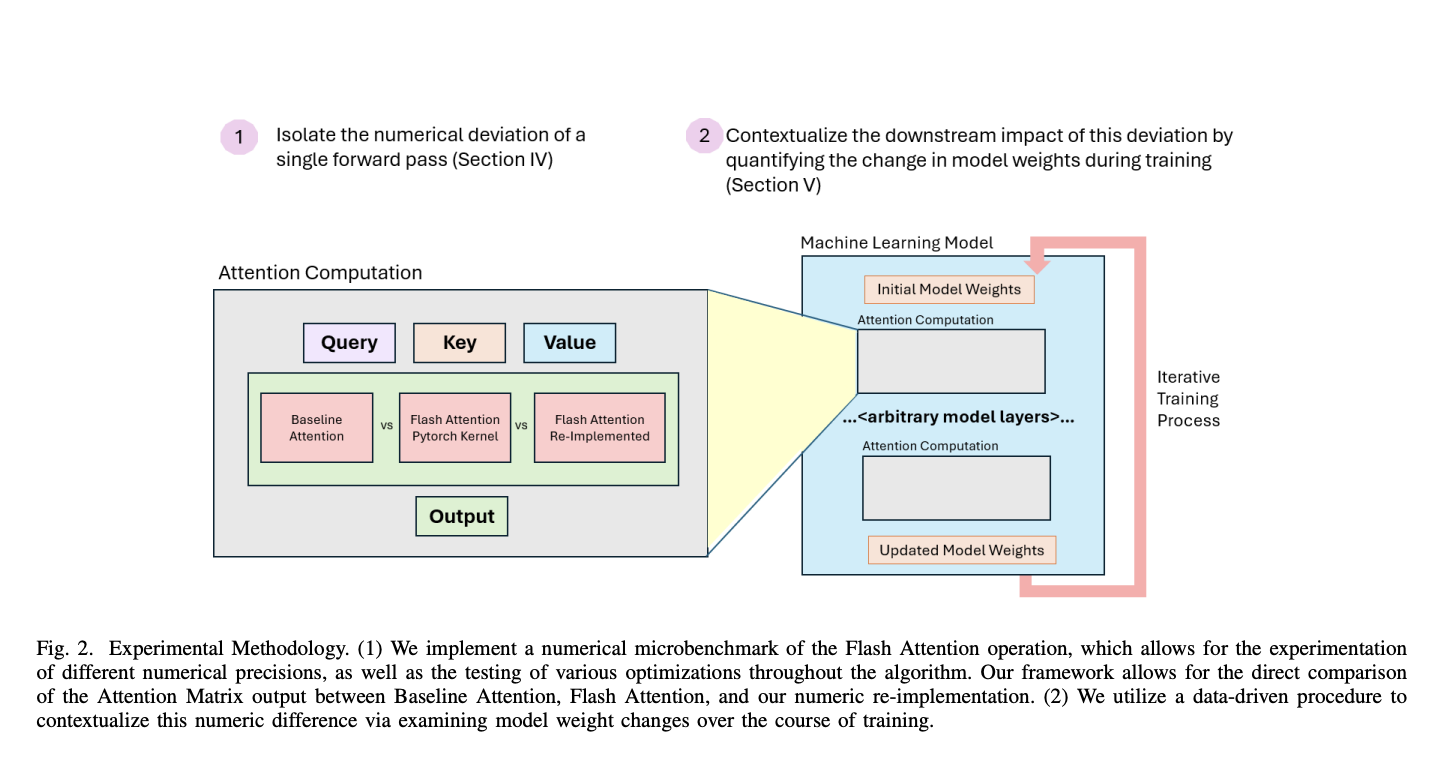
Flash Attention, a technique analyzed for its utility and efficiency, particularly targets the efficiency of the attention mechanism, a crucial component of transformer models. This technique leverages a system of tiling and recomputation to process the attention mechanism’s large matrices more efficiently, minimizing the extensive memory usage that traditional methods incur. For instance, in specific implementations, Flash Attention has demonstrated a 14% increase in speed for both forward and backward processing passes in text-to-image models, highlighting its potential for enhancing training efficiency.
The method introduces certain computational nuances, such as rescaling factors necessary for managing data blocks within the model’s memory constraints. While beneficial for memory management, these rescaling factors introduce an additional layer of numeric deviation. Researchers from FAIR at Meta, Harvard University, and Meta have quantified this deviation, finding that Flash Attention introduces roughly ten times more numeric deviation than Baseline Attention at BF16 numerical precision. However, a more comprehensive analysis, like one utilizing the Wasserstein Distance, shows that this deviation is still 2-5 times less impactful than deviations from low-precision training.

Despite the improvements in computational efficiency and memory usage, the numeric deviations associated with Flash Attention could still pose risks to model training stability. Analyzing these deviations is critical, allowing a deeper understanding of how they can impact long-term training stability. As such, while Flash Attention offers considerable advantages in terms of efficiency and speed, its broader implications on training stability require careful evaluation.
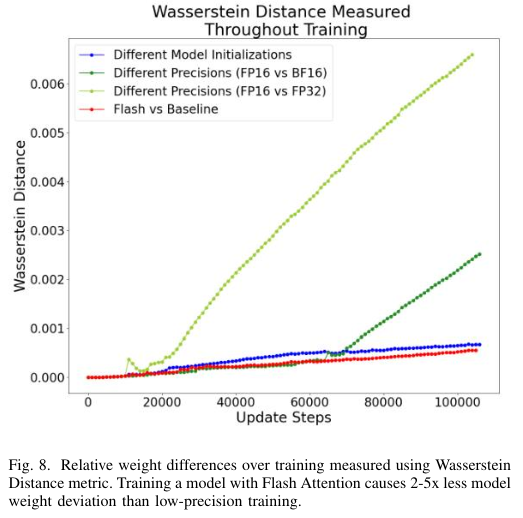
In conclusion, Flash Attention advances in optimizing attention mechanisms within large-scale machine learning models. Efficiently managing the computational demands and reducing memory usage marks a step forward in addressing the enduring challenge of training instabilities. However, the introduction of numeric deviations by the method underscores the need for ongoing analysis and potential refinement to ensure that these efficiencies do not inadvertently compromise the overall stability of model training. Thus, while Flash Attention provides a promising avenue for improving training processes, its implications on stability are yet to be fully realized and warrant further investigation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.