
Large vision language models (LVLMs) showcase powerful visual perception and understanding capabilities. These achievements have further inspired the research community to develop a variety of multi-modal benchmarks constructed to explore the powerful capabilities emerging from LVLMs and provide a comprehensive and objective platform for quantitatively comparing the continually evolving models. However, after careful evaluation, the researchers identified two primary issues:
1) Visual content is unnecessary for many samples, and
2) Unintentional data leakage exists in LLM and LVLM training.
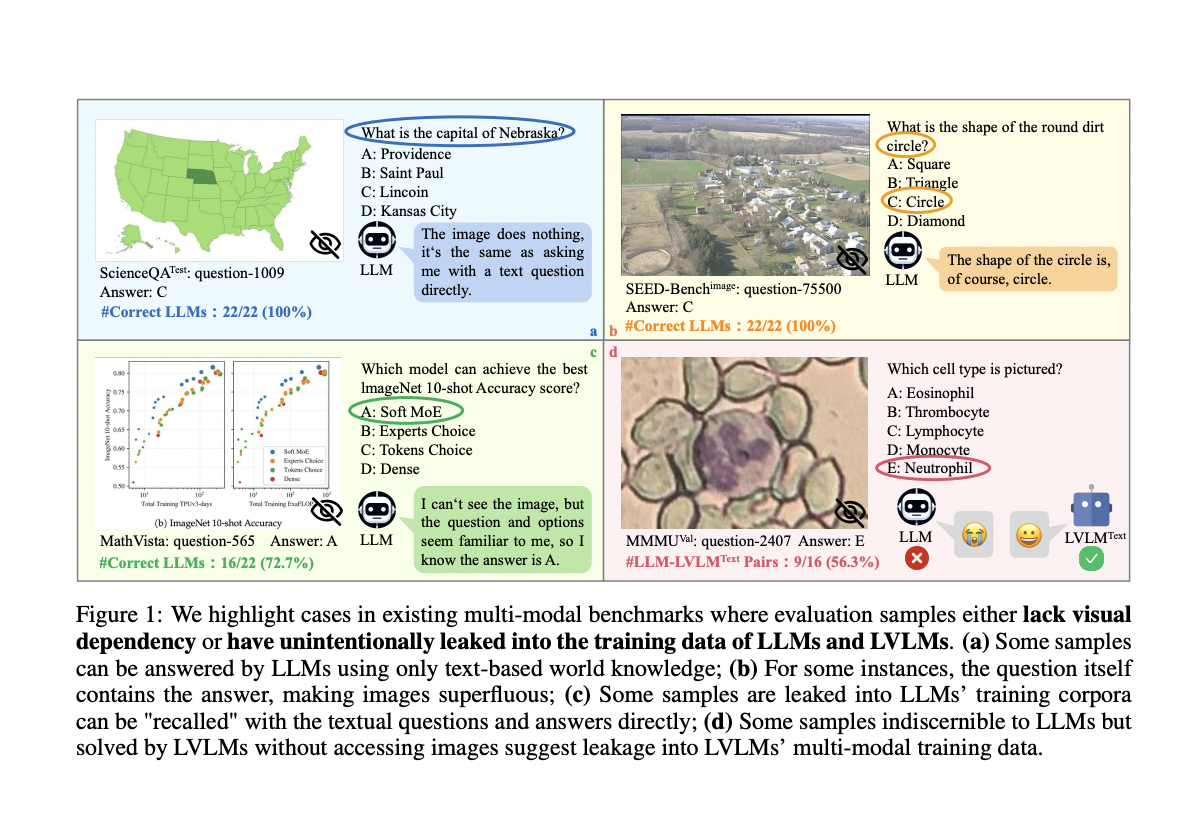
Early single-task benchmarks, such as VQA, MS-COCO, and OK-VQA, fail to holistically assess LVLMs’ general multi-modal perception and reasoning capabilities. To address this issue, comprehensive multi-modal benchmarks have been constructed. For example, SEED, MMBench, and MMMU provide competitive arenas for comprehensively comparing cutting-edge LVLMs. However, existing evaluations of LVLMs overlook some critical issues. On the one hand, they do not guarantee that all evaluation samples can not be correctly answered without the visual content. On the other hand, current evaluations consistently adhere to the process of inferring on given benchmarks and calculating scores for LVLMs, overlooking the possibility of data leakage during multi-modal training. This oversight can lead to unfair comparisons and misjudgments.
The researchers from the University of Science and Technology of China, The Chinese University of Hong Kong, and Shanghai AI Laboratory present MMStar, an elite vision-indispensable multi-modal benchmark comprising 1,500 samples meticulously selected by humans. MMStar benchmarks six core capabilities and 18 detailed axes, aiming to evaluate LVLMs’ multi-modal capacities with carefully balanced and purified samples. These samples are first roughly selected from current benchmarks with an automated pipeline; human review is then involved to ensure each curated sample exhibits visual dependency, minimal data leakage, and requires advanced multi-modal capabilities. Moreover, two metrics are developed to measure data leakage and actual performance gain in multi-modal training.
MMStar is explained in three sections:
- Data Curation Process: Criteria for data curation: The evaluation samples for constructing the MMStar benchmark should meet three fundamental criteria: 1) Visual dependency. The collected samples can be correctly answered only based on understanding the visual content; 2) Minimal data leakage. The collected samples should minimize the risk of unintentional inclusion in LLMs’ training corpus or be effectively transformed from uni-modal to multi-modal formats to prevent LLMs from “recalling” the correct answers; 3) Requiring advanced multi-modal capabilities for resolution.
Data filter: For their sample collection, they first chose two benchmarks focused on natural images and four centered on scientific and technical knowledge. Then, they developed an automated pipeline to preliminarily filter out samples that did not meet the first two criteria. Specifically, they employ two closed-source LLMs and six open-source LLMs.
Manual review: After the coarse filtering with LLM inspectors, they further employ three experts to conduct the manual review process to ensure: 1) each sample’s answer should be based on the understanding of visual content; 2) selected samples should cover a comprehensive range of capability assessment dimensions; 3) most samples should require LVLMs to possess advanced multi-modal abilities for resolution.
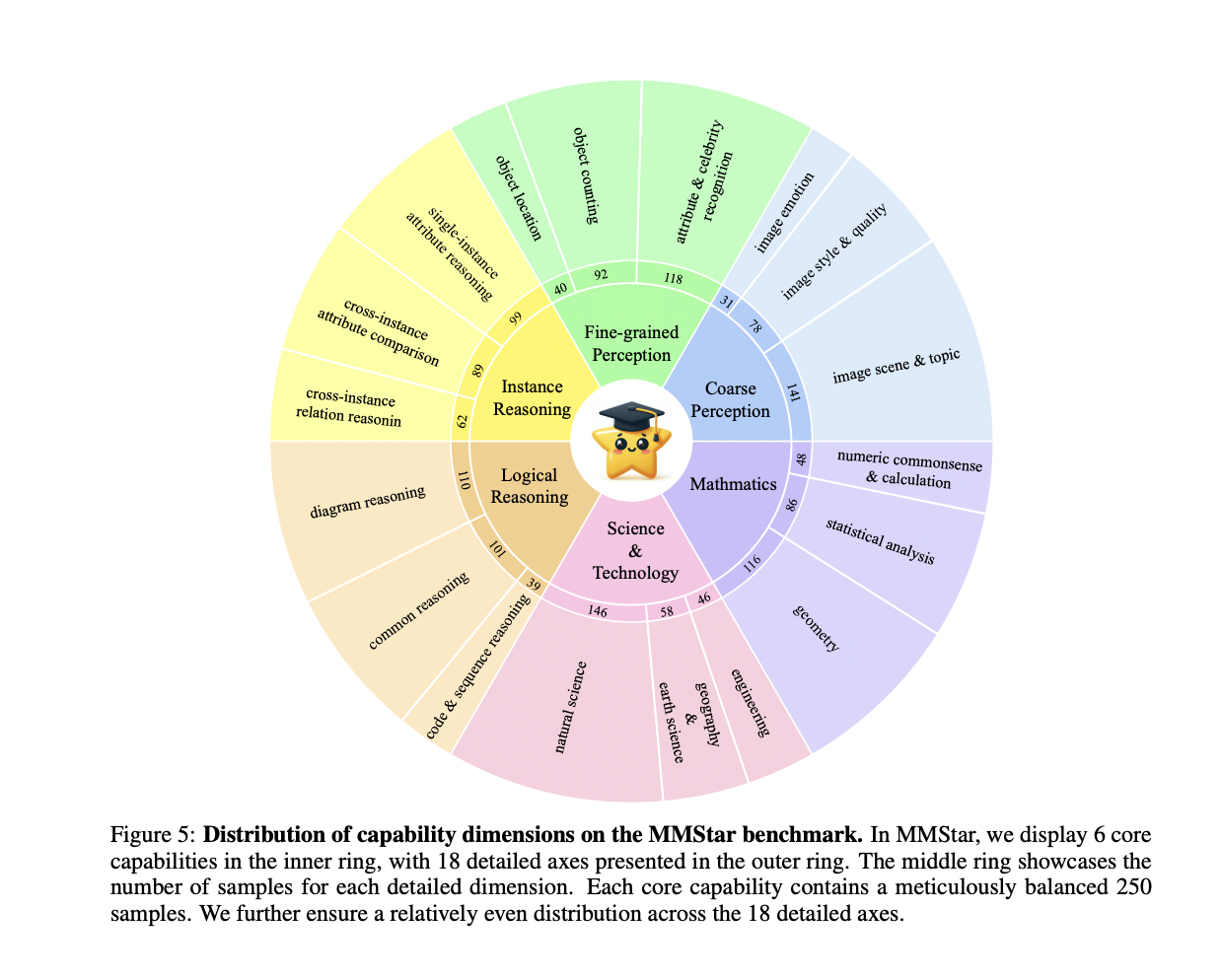
- Core Capabilities: They select and consolidate the dimensions used for assessing LVLMs’ multi-modal capabilities in existing benchmarks and identify six core capability dimensions and eighteen detailed axes.
- Multi-modal Gain/Leakage: They proposed two unique metrics to assess the degree of data leakage and actual performance gain from the multi-modal training process.
They evaluated two closed-source and 14 open-source LVLMs on MMStar, with a high-resolution setting that can achieve the best average score of 57.1% among all LVLMs. Increasing the resolution and number of image tokens can boost the average score from 46.1% to 57.1% for GPT4V. Among the open-source LVLMs, InternLMXcomposer2 achieves an impressive score of 55.4%. LLaVA-Next even surpasses GPT4V and GeminiPro-Vision in the mathematics (MA) core capability.
In conclusion, the researchers delved deeper into the evaluation work for LVLMs, and They found two key issues: 1) visual content is unnecessary for many samples, and 2) unintentional data leakage exists in LLM and LVLM training. Researchers developed an elite vision-dependent multi-modal benchmark named MMStar and proposed two metrics to measure the data leakage and actual performance gain in LVLMs’ multi-modal training. MMStar undergoes the manual review of each sample, covering six core capabilities and 18 detailed axes for an in-depth evaluation of LVLMs’ multimodal capabilities. Evaluating 16 diverse LVLMs on MMStar, even the best model scores under 60 on average.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.

