
Safety tuning is important for ensuring that advanced Large Language Models (LLMs) are aligned with human values and safe to deploy. Current LLMs, including those tuned for safety and alignment, are susceptible to jailbreaking. Existing guardrails are shown to be fragile. Even customizing models through fine-tuning with benign data, free of harmful content, could trigger degradation in safety for previously aligned models.
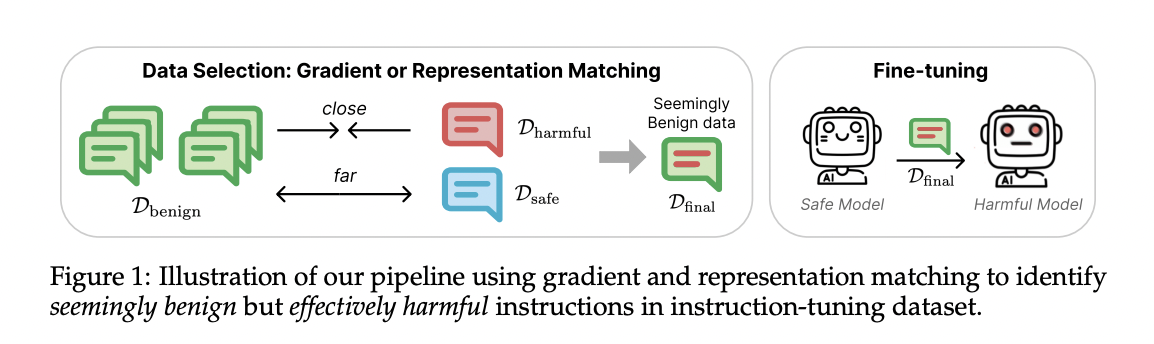
Researchers from Princeton Language and Intelligence (PLI), Princeton University, present a thorough research on why benign-finetuning inadvertently leads to jailbreaking. They represent fine-tuning data through two lenses: representation and gradient spaces. They also proposed a bi-directional anchoring method that prioritizes data points close to harmful examples and distant from benign ones. Their approach effectively identifies subsets of benign data that are more likely to degrade the model’s safety after fine-tuning.
They considered finetuning a safety-aligned language model with a dataset of instruction completion pairs without explicit harmful information. Researchers proposed two model-aware approaches to identify data that can lead to model jailbreaking: representation matching and gradient matching. For representation matching, they hypothesized that examples positioned near harmful examples would have similar optimization pathways as actual harmful examples, making them more prone to degrading safety guardrails during fine-tuning even if they don’t explicitly include harmful content. They explicitly considered the directions in which samples update the model for gradient matching. The intuition is that samples more likely to lead to a loss decrease in harmful examples are more likely to lead to jailbreaking.
On comparing fine-tuning data selected by their approaches and random selection, They demonstrated that their representation matching and gradient matching techniques effectively identify the implicitly harmful subsets of benign data. Incorporating safety anchors, the ASR for top-selected examples significantly increases from 46.6% to 66.5% on ALPACA and from 4.9% to 53.3% on DOLLY. Moreover, selecting the lowest-ranked examples leads to a substantially reduced ASR of 3.8% on ALPACA. They fine-tuned LLAMA-2-13B-CHAT using the same hyperparameters and the same sets of data selected with either representation or gradient-based method, using LLAMA-2-7BCHAT as the base model. Then, the same evaluation suite on the fine-tuned 13B models showed that the selection was effective on the bigger model, boosting the model’s harmfulness after fine-tuning.
In this work, the researchers provide a study on benign fine-tuning breaking model safety and alignment from a data-centric perspective. They introduced representation and gradient-based methods that effectively select a subset of benign data that jailbreaks models after finetuning. GPT-3.5 ASR increases from less than 20% to more than 70% after fine-tuning on their selected dataset, exceeding ASR after fine-tuning on an explicitly harmful dataset of the same size. This work provides an initial step into understanding which benign data will more likely degrade safety after fine-tuning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.

