

Combining Large and Small LLMs to Boost Inference Time and Quality
Implementing Speculative and Contrastive DecodingLarge Language models are comprised of billions of parameters (weights). For each word it generates, the model has to perform computationally expensive calculations across all of these parameters.Large Language models accept a sentence, or sequence of tokens, and generate a probability distribution of the next most likely token.Thus, typically decoding n tokens (or generating n words from the model) requires running the model n number of times. At each iteration, the new token is appended to the input sentence and passed to the model again. This can be costly.Additionally, decoding strategy can influence the quality of the generated words. Generating tokens in a simple way, by just taking the token with the highest probability in the output distribution, can result in repetitive text. Random sampling from the distribution can result in unintended drift.Thus, a solid decoding strategy is required to ensure both:High Quality OutputsFast Inference TimeBoth requirements can be addressed by using a combination of a large and small language model, as long as the amateur and expert models are similar (e.g., same architecture but different sizes).Target/Large Model: Main LM with larger number of parameters (e.g. OPT-13B)Amateur/Small Model: Smaller version of Main LM with fewer parameters (e.g. OPT-125M)Speculative and contrastive decoding leverage large and small LLMs to achieve reliable and efficient text generation.Contrastive Decoding for High Quality InferenceContrastive Decoding is a strategy that exploits the fact that that failures in large LLMs (such as repetition, incoherence) are even more pronounced in small LLMs. Thus, this strategy optimizes for the tokens with the highest probability difference between the small and large model.For a single prediction, contrastive decoding generates two probability distributions:q = logit probabilities for amateur modelp = logit probabilities for expert modelThe next token is chosen based on the following criteria:Discard all tokens that do not have sufficiently high probability under the expert model (discard p(x) < alpha * max(p))From the remaining tokens, select the one the with the largest difference between large model and small model log probabilities, max(p(x) - q(x)).Implementing Contrastive Decodingfrom transformers import AutoTokenizer, AutoModelForCausalLMimport torch# Load models and tokenizertokenizer = AutoTokenizer.from_pretrained('gpt2')amateur_lm = AutoModelForCausalLM.from_pretrained('gpt2')expert_lm = AutoModelForCausalLM.from_pretrained('gpt2-large')def contrastive_decoding(prompt, max_length=50): input_ids = tokenizer(prompt, return_tensors="pt").input_ids while input_ids.shape[1] < max_length: # Generate amateur model output amateur_outputs = amateur_lm(input_ids, return_dict=True) amateur_logits = torch.softmax(amateur_outputs.logits[:, -1, :], dim=-1) log_probs_amateur = torch.log(amateur_logits) # Generate expert model output expert_outputs = expert_lm(input_ids, return_dict=True) expert_logits = torch.softmax(expert_outputs.logits[:, -1, :], dim=-1) log_probs_exp = torch.log(expert_logits) log_probs_diff = log_probs_exp - log_probs_amateur # Set an alpha threshold to eliminate less confident tokens in expert alpha = 0.1 candidate_exp_prob = torch.max(expert_logits) # Mask tokens below threshold for expert model V_head = expert_logits < alpha * candidate_exp_prob # Select the next token from the log-probabilities difference, ignoring masked values token = torch.argmax(log_probs_diff.masked_fill(V_head, -torch.inf)).unsqueeze(0) # Append token and accumulate generated text input_ids = torch.cat([input_ids, token.unsqueeze(1)], dim=-1) return tokenizer.batch_decode(input_ids)prompt = "Large Language Models are"generated_text = contrastive_decoding(prompt, max_length=25)print(generated_text)Speculative Decoding For Fast InferenceSpeculative decoding is based on the principle that the smaller model must sample from the same distribution as the larger model. Thus, this strategy aims to accept as many predictions from the smaller model as possible, provided they align with the distribution of the larger model.The smaller model generates n tokens in sequence, as possible guesses. However, all n sequences are fed into the larger expert model as a single batch, which is faster than sequential generation.This results in a cache for each model, with n probability distributions in each cache.q = logit probabilities for amateur modelp = logit probabilities for expert modelNext, the sampled tokens from the amateur model are accepted or rejected based on the following conditions:If probability of the token is higher in expert distribution (p) than amateur distribution (q), or p(x) > q(x), accept tokenIf probability of token is lower in expert distribution (p) than amateur dist
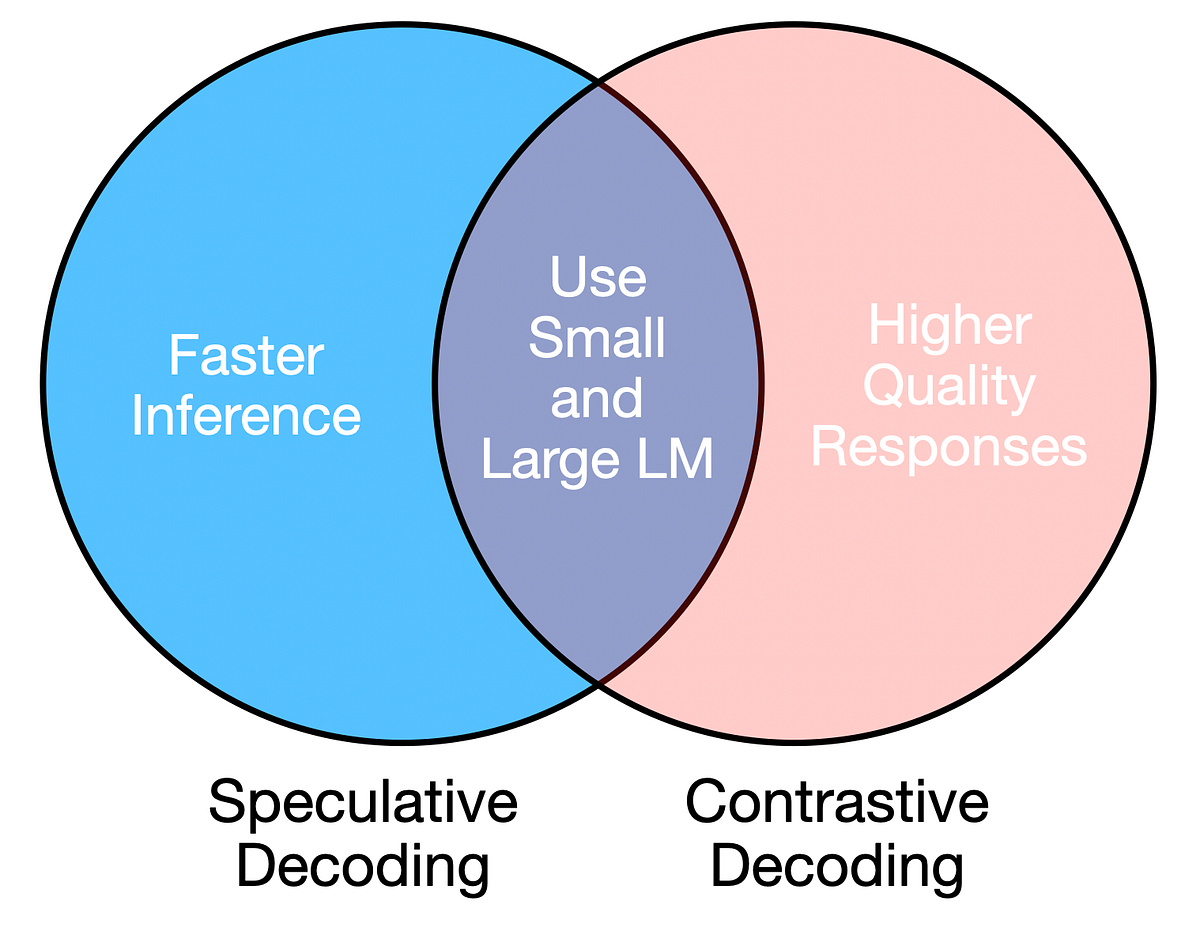
Implementing Speculative and Contrastive Decoding
Large Language models are comprised of billions of parameters (weights). For each word it generates, the model has to perform computationally expensive calculations across all of these parameters.
Large Language models accept a sentence, or sequence of tokens, and generate a probability distribution of the next most likely token.
Thus, typically decoding n tokens (or generating n words from the model) requires running the model n number of times. At each iteration, the new token is appended to the input sentence and passed to the model again. This can be costly.
Additionally, decoding strategy can influence the quality of the generated words. Generating tokens in a simple way, by just taking the token with the highest probability in the output distribution, can result in repetitive text. Random sampling from the distribution can result in unintended drift.
Thus, a solid decoding strategy is required to ensure both:
- High Quality Outputs
- Fast Inference Time
Both requirements can be addressed by using a combination of a large and small language model, as long as the amateur and expert models are similar (e.g., same architecture but different sizes).
- Target/Large Model: Main LM with larger number of parameters (e.g. OPT-13B)
- Amateur/Small Model: Smaller version of Main LM with fewer parameters (e.g. OPT-125M)
Speculative and contrastive decoding leverage large and small LLMs to achieve reliable and efficient text generation.
Contrastive Decoding for High Quality Inference
Contrastive Decoding is a strategy that exploits the fact that that failures in large LLMs (such as repetition, incoherence) are even more pronounced in small LLMs. Thus, this strategy optimizes for the tokens with the highest probability difference between the small and large model.
For a single prediction, contrastive decoding generates two probability distributions:
- q = logit probabilities for amateur model
- p = logit probabilities for expert model
The next token is chosen based on the following criteria:
- Discard all tokens that do not have sufficiently high probability under the expert model (discard p(x) < alpha * max(p))
- From the remaining tokens, select the one the with the largest difference between large model and small model log probabilities, max(p(x) - q(x)).

Implementing Contrastive Decoding
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Load models and tokenizer
tokenizer = AutoTokenizer.from_pretrained('gpt2')
amateur_lm = AutoModelForCausalLM.from_pretrained('gpt2')
expert_lm = AutoModelForCausalLM.from_pretrained('gpt2-large')
def contrastive_decoding(prompt, max_length=50):
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
while input_ids.shape[1] < max_length:
# Generate amateur model output
amateur_outputs = amateur_lm(input_ids, return_dict=True)
amateur_logits = torch.softmax(amateur_outputs.logits[:, -1, :], dim=-1)
log_probs_amateur = torch.log(amateur_logits)
# Generate expert model output
expert_outputs = expert_lm(input_ids, return_dict=True)
expert_logits = torch.softmax(expert_outputs.logits[:, -1, :], dim=-1)
log_probs_exp = torch.log(expert_logits)
log_probs_diff = log_probs_exp - log_probs_amateur
# Set an alpha threshold to eliminate less confident tokens in expert
alpha = 0.1
candidate_exp_prob = torch.max(expert_logits)
# Mask tokens below threshold for expert model
V_head = expert_logits < alpha * candidate_exp_prob
# Select the next token from the log-probabilities difference, ignoring masked values
token = torch.argmax(log_probs_diff.masked_fill(V_head, -torch.inf)).unsqueeze(0)
# Append token and accumulate generated text
input_ids = torch.cat([input_ids, token.unsqueeze(1)], dim=-1)
return tokenizer.batch_decode(input_ids)
prompt = "Large Language Models are"
generated_text = contrastive_decoding(prompt, max_length=25)
print(generated_text)
Speculative Decoding For Fast Inference
Speculative decoding is based on the principle that the smaller model must sample from the same distribution as the larger model. Thus, this strategy aims to accept as many predictions from the smaller model as possible, provided they align with the distribution of the larger model.
The smaller model generates n tokens in sequence, as possible guesses. However, all n sequences are fed into the larger expert model as a single batch, which is faster than sequential generation.
This results in a cache for each model, with n probability distributions in each cache.
- q = logit probabilities for amateur model
- p = logit probabilities for expert model
Next, the sampled tokens from the amateur model are accepted or rejected based on the following conditions:
- If probability of the token is higher in expert distribution (p) than amateur distribution (q), or p(x) > q(x), accept token
- If probability of token is lower in expert distribution (p) than amateur distribution (q), or p(x) < q(x), reject token with probability 1 - p(x) / q(x)
If a token is rejected, the next token is sampled from the expert distribution or adjusted distribution. Additionally, the amateur and expert model reset the cache and re-generate n guesses and probability distributions p and q.
Implementing Speculative Decoding
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Load models and tokenizer
tokenizer = AutoTokenizer.from_pretrained('gpt2')
amateur_lm = AutoModelForCausalLM.from_pretrained('gpt2')
expert_lm = AutoModelForCausalLM.from_pretrained('gpt2-large')
# Sample next token from output distribution
def sample_from_distribution(logits):
sampled_index = torch.multinomial(logits, 1)
return sampled_index
def generate_cache(input_ids, n_tokens):
# Store logits at each step for amateur and expert models
amateur_logits_per_step = []
generated_tokens = []
batch_input_ids = []
with torch.no_grad():
for _ in range(n_tokens):
# Generate amateur model output
amateur_outputs = amateur_lm(input_ids, return_dict=True)
amateur_logits = torch.softmax(amateur_outputs.logits[:, -1, :], dim=-1)
amateur_logits_per_step.append(amateur_logits)
# Sampling from amateur logits
next_token = sample_from_distribution(amateur_logits)
generated_tokens.append(next_token)
# Append to input_ids for next generation step
input_ids = torch.cat([input_ids, next_token], dim=-1)
batch_input_ids.append(input_ids.squeeze(0))
# Feed IDs to expert model as batch
batched_input_ids = torch.nn.utils.rnn.pad_sequence(batch_input_ids, batch_first=True, padding_value=0 )
expert_outputs = expert_lm(batched_input_ids, return_dict=True)
expert_logits = torch.softmax(expert_outputs.logits[:, -1, :], dim=-1)
return amateur_logits_per_step, expert_logits, torch.cat(generated_tokens, dim=-1)
def speculative_decoding(prompt, n_tokens=5, max_length=50):
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
while input_ids.shape[1] < max_length:
amateur_logits_per_step, expert_logits, generated_ids = generate_cache(
input_ids, n_tokens
)
accepted = 0
for n in range(n_tokens):
token = generated_ids[:, n][0]
r = torch.rand(1).item()
# Extract probabilities
p_x = expert_logits[n][token].item()
q_x = amateur_logits_per_step[n][0][token].item()
# Speculative decoding acceptance criterion
if ((q_x > p_x) and (r > (1 - p_x / q_x))):
break # Reject token and restart the loop
else:
accepted += 1
# Check length
if (input_ids.shape[1] + accepted) >= max_length:
return tokenizer.batch_decode(input_ids)
input_ids = torch.cat([input_ids, generated_ids[:, :accepted]], dim=-1)
if accepted < n_tokens:
diff = expert_logits[accepted] - amateur_logits_per_step[accepted][0]
clipped_diff = torch.clamp(diff, min=0)
# Sample a token from the adjusted expert distribution
normalized_result = clipped_diff / torch.sum(clipped_diff, dim=0, keepdim=True)
next_token = sample_from_distribution(normalized_result)
input_ids = torch.cat([input_ids, next_token.unsqueeze(1)], dim=-1)
else:
# Sample directly from the expert logits for the last accepted token
next_token = sample_from_distribution(expert_logits[-1])
input_ids = torch.cat([input_ids, next_token.unsqueeze(1)], dim=-1)
return tokenizer.batch_decode(input_ids)
# Example usage
prompt = "Large Language models are"
generated_text = speculative_decoding(prompt, n_tokens=3, max_length=25)
print(generated_text)
Evaluation
We can evaluate both decoding approaches by comparing them to a naive decoding method, where we randomly pick the next token from the probability distribution.
def sequential_sampling(prompt, max_length=50):
"""
Perform sequential sampling with the given model.
"""
# Tokenize the input prompt
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
with torch.no_grad():
while input_ids.shape[1] < max_length:
# Sample from the model output logits for the last token
outputs = expert_lm(input_ids, return_dict=True)
logits = outputs.logits[:, -1, :]
probabilities = torch.softmax(logits, dim=-1)
next_token = torch.multinomial(probabilities, num_samples=1)
input_ids = torch.cat([input_ids, next_token], dim=-1)
return tokenizer.batch_decode(input_ids)
To evaluate contrastive decoding, we can use the following metrics for lexical richness.
- n-gram Entropy: Measures the unpredictability or diversity of n-grams in the generated text. High entropy indicates more diverse text, while low entropy suggests repetition or predictability.
- distinct-n: Measures the proportion of unique n-grams in the generated text. Higher distinct-n values indicate more lexical diversity.
from collections import Counter
import math
def ngram_entropy(text, n):
"""
Compute n-gram entropy for a given text.
"""
# Tokenize the text
tokens = text.split()
if len(tokens) < n:
return 0.0 # Not enough tokens to form n-grams
# Create n-grams
ngrams = [tuple(tokens[i:i + n]) for i in range(len(tokens) - n + 1)]
# Count frequencies of n-grams
ngram_counts = Counter(ngrams)
total_ngrams = sum(ngram_counts.values())
# Compute entropy
entropy = -sum((count / total_ngrams) * math.log2(count / total_ngrams)
for count in ngram_counts.values())
return entropy
def distinct_n(text, n):
"""
Compute distinct-n metric for a given text.
"""
# Tokenize the text
tokens = text.split()
if len(tokens) < n:
return 0.0 # Not enough tokens to form n-grams
# Create n-grams
ngrams = [tuple(tokens[i:i + n]) for i in range(len(tokens) - n + 1)]
# Count unique and total n-grams
unique_ngrams = set(ngrams)
total_ngrams = len(ngrams)
return len(unique_ngrams) / total_ngrams if total_ngrams > 0 else 0.0
prompts = [
"Large Language models are",
"Barack Obama was",
"Decoding strategy is important because",
"A good recipe for Halloween is",
"Stanford is known for"
]
# Initialize accumulators for metrics
naive_entropy_totals = [0, 0, 0] # For n=1, 2, 3
naive_distinct_totals = [0, 0] # For n=1, 2
contrastive_entropy_totals = [0, 0, 0]
contrastive_distinct_totals = [0, 0]
for prompt in prompts:
naive_generated_text = sequential_sampling(prompt, max_length=50)[0]
for n in range(1, 4):
naive_entropy_totals[n - 1] += ngram_entropy(naive_generated_text, n)
for n in range(1, 3):
naive_distinct_totals[n - 1] += distinct_n(naive_generated_text, n)
contrastive_generated_text = contrastive_decoding(prompt, max_length=50)[0]
for n in range(1, 4):
contrastive_entropy_totals[n - 1] += ngram_entropy(contrastive_generated_text, n)
for n in range(1, 3):
contrastive_distinct_totals[n - 1] += distinct_n(contrastive_generated_text, n)
# Compute averages
naive_entropy_averages = [total / len(prompts) for total in naive_entropy_totals]
naive_distinct_averages = [total / len(prompts) for total in naive_distinct_totals]
contrastive_entropy_averages = [total / len(prompts) for total in contrastive_entropy_totals]
contrastive_distinct_averages = [total / len(prompts) for total in contrastive_distinct_totals]
# Display results
print("Naive Sampling:")
for n in range(1, 4):
print(f"Average Entropy (n={n}): {naive_entropy_averages[n - 1]}")
for n in range(1, 3):
print(f"Average Distinct-{n}: {naive_distinct_averages[n - 1]}")
print("\nContrastive Decoding:")
for n in range(1, 4):
print(f"Average Entropy (n={n}): {contrastive_entropy_averages[n - 1]}")
for n in range(1, 3):
print(f"Average Distinct-{n}: {contrastive_distinct_averages[n - 1]}")
The following results show us that contrastive decoding outperforms naive sampling for these metrics.
Naive Sampling:
Average Entropy (n=1): 4.990499826537679
Average Entropy (n=2): 5.174765791328267
Average Entropy (n=3): 5.14373124004409
Average Distinct-1: 0.8949694135740648
Average Distinct-2: 0.9951219512195122
Contrastive Decoding:
Average Entropy (n=1): 5.182773920916605
Average Entropy (n=2): 5.3495681172235665
Average Entropy (n=3): 5.313720275712986
Average Distinct-1: 0.9028425204970866
Average Distinct-2: 1.0
To evaluate speculative decoding, we can look at the average runtime for a set of prompts for different n values.
import time
import matplotlib.pyplot as plt
# Parameters
n_tokens = range(1, 11)
speculative_decoding_times = []
naive_decoding_times = []
prompts = [
"Large Language models are",
"Barack Obama was",
"Decoding strategy is important because",
"A good recipe for Halloween is",
"Stanford is known for"
]
# Loop through n_tokens values
for n in n_tokens:
avg_time_naive, avg_time_speculative = 0, 0
for prompt in prompts:
start_time = time.time()
_ = sequential_sampling(prompt, max_length=25)
avg_time_naive += (time.time() - start_time)
start_time = time.time()
_ = speculative_decoding(prompt, n_tokens=n, max_length=25)
avg_time_speculative += (time.time() - start_time)
naive_decoding_times.append(avg_time_naive / len(prompts))
speculative_decoding_times.append(avg_time_speculative / len(prompts))
avg_time_naive = sum(naive_decoding_times) / len(naive_decoding_times)
# Plotting the results
plt.figure(figsize=(8, 6))
plt.bar(n_tokens, speculative_decoding_times, width=0.6, label='Speculative Decoding Time', alpha=0.7)
plt.axhline(y=avg_time_naive, color='red', linestyle='--', label='Naive Decoding Time')
# Labels and title
plt.xlabel('n_tokens', fontsize=12)
plt.ylabel('Average Time (s)', fontsize=12)
plt.title('Speculative Decoding Runtime vs n_tokens', fontsize=14)
plt.legend()
plt.grid(axis='y', linestyle='--', alpha=0.7)
# Show the plot
plt.show()
plt.savefig("plot.png")
We can see that the average runtime for the naive decoding is much higher than for speculative decoding across n values.
Combining large and small language models for decoding strikes a balance between quality and efficiency. While these approaches introduce additional complexity in system design and resource management, their benefits apply to conversational AI, real-time translation, and content creation.
These approaches require careful consideration of deployment constraints. For instance, the additional memory and compute demands of running dual models may limit feasibility on edge devices, though this can be mitigated through techniques like model quantization.
Unless otherwise noted, all images are by the author.
Combining Large and Small LLMs to Boost Inference Time and Quality was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.










