

Discover What Every Neuron in the Llama Model Does
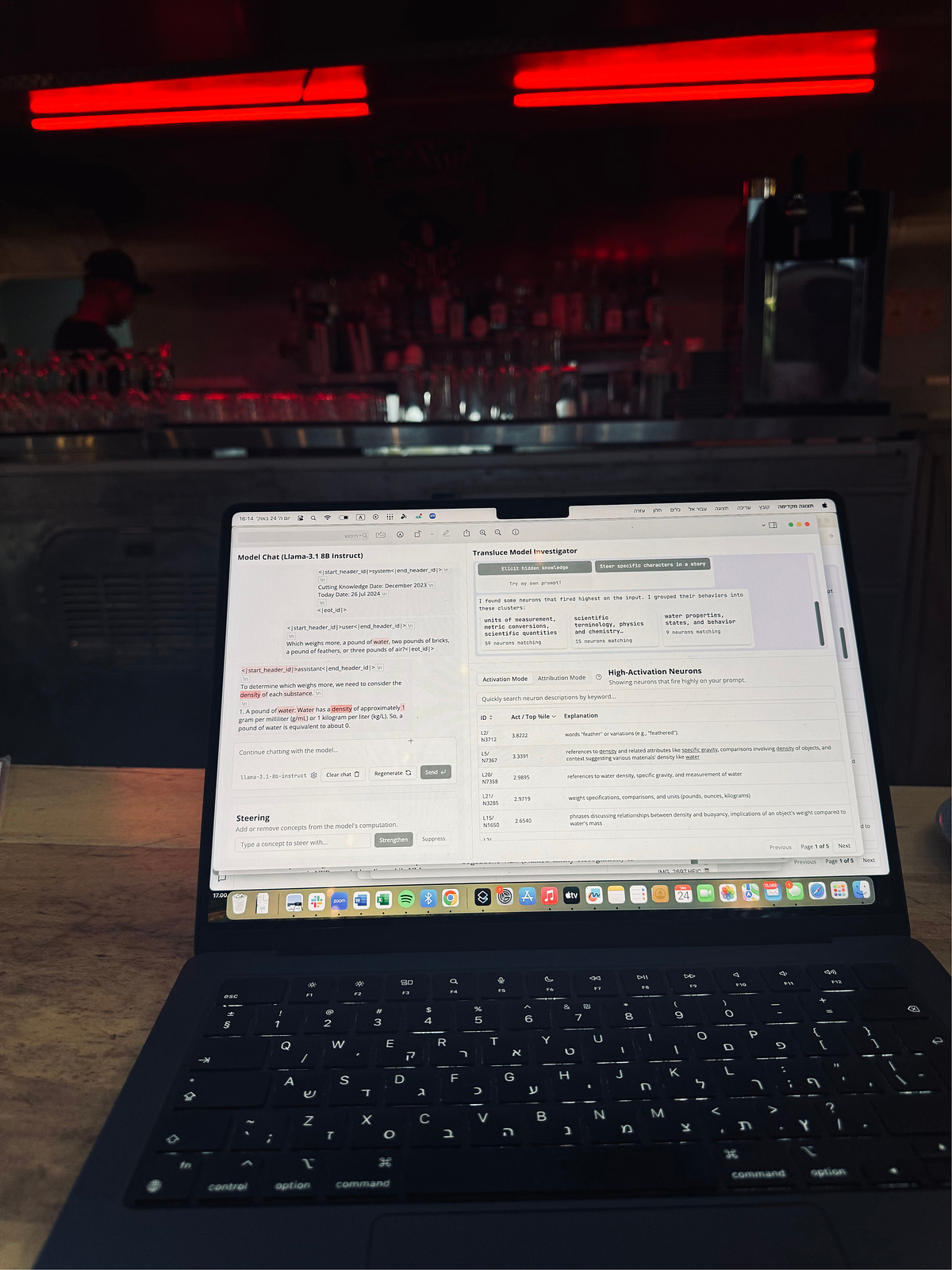
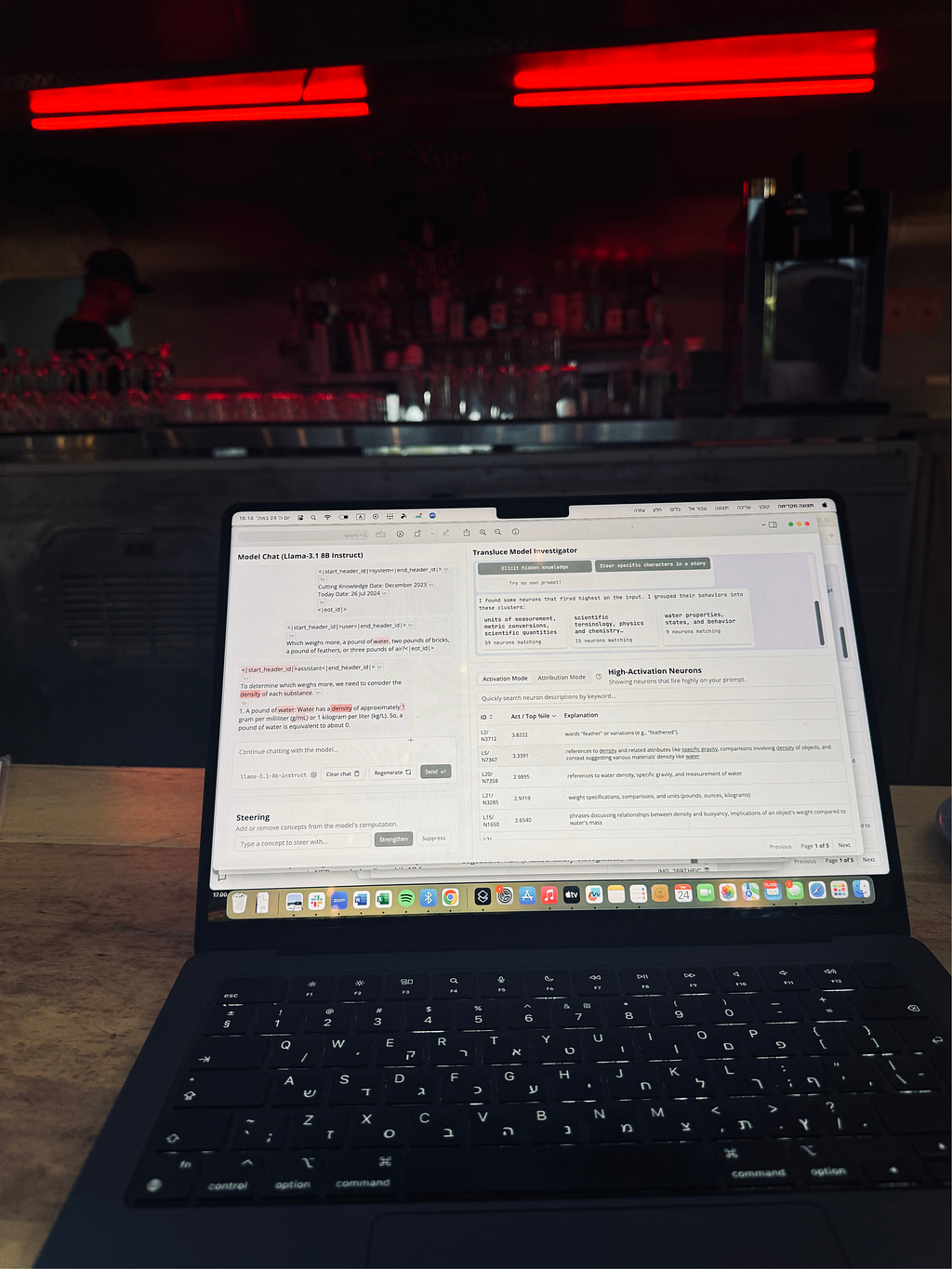
Transluce’s new tool is changing the game for AI transparency — a test case and some food for thoughtImage by the author — caught in the act of playing with the new tool!Transluce, a new non-profit research lab with an inspiring mission, has just released (23.10.24) a fascinating tool that provides insights into neuron behavior in LLMs. Or in their own words:When an AI system behaves unexpectedly, we’d like to understand the “thought process” that explains why the behavior occurred. This lets us predict and fix problems with AI models , surface hidden knowledge, and uncover learned biases and spurious correlations.To fulfill their mission, they have launched an observability interface where you can input your own prompts, receive responses, and see which neurons are activated. You can then explore the activated neurons and their attribution to the model’s output, all enabled by their novel approach to automatically producing high-quality descriptions of neurons inside language models.If you want to test the tool, go here. They also offer some helpful tutorials. In this article, I will try to provide another use case and share my own experience.There are probably many things to know (depending on your background), but I’ll focus on two key features: Activation and Attribution.Activation measures the (normalized) activation value of the neuron. Llama uses gated MLPs, meaning that activations can be either positive or negative. We normalize by the value of the 10–5 quantile of the neuron across a large dataset of examples.Attribution measures how much the neuron affects the model’s output. Attribution must be conditioned on a specific output token, and is equal to the gradient of that output token’s probability with respect to the neuron’s activation, times the activation value of the neuron. Attribution values are not normalized, and are reported as absolute values.Using these two features you can explore the model’s behavior, the neurons behavior and even notice for patterns (or as they call it “clusters”) of neurons’ behavior phenomena.If the model output isn’t what you expect, or if the model gets it wrong, the tool allows you to steer neurons and ‘fix’ the issue by either strengthening or suppressing concept-related neurons (There are great work on how to steer based on concepts — one of them is this great work).So, curious enough, I tested this with my own prompt.I took a simple logic question that most models today fail to solve.Q: “???????????????????? ???????????? ???? ???????????????????????????????? ???????????? ???? ????????????????????????????. ???????????? ???????????????? ???????????????????????????? ???????????????? ????????????????????’???? ???????????????????????????? ?????????????????”Homepage. Image via monitor.transluce.orgAnd voila….Llama gets it wrong. Image via monitor.transluce.orgOr not.On the left side, you can see the prompt and the output. On the right side, you can see the neurons that “fire” the most and observe the main clusters these neurons group into.If you hover over the tokens on the left, you can see the top probabilities. If you click on one of the tokens, you can find out which neurons contributed to predicting that token.Hover over “in.” We can see tokens with the top probabilities. Image via monitor.transluce.orgAs you can see, both the logic and the answer are wrong.“Since Alice has 4 brothers, we need to find out how many sisters they have in common” >>> Ugh! You already know that.And of course, if Alice has two sisters (which is given in the input), it doesn’t mean Alice’s brother has 2 sisters :(So, let’s try to fix this. After examining the neurons, I noticed that the “diversity” concept was overly active (perhaps it was confused about Alice’s identity?). So, I tried steering these neurons.Steering window. Image via monitor.transluce.orgI suppressed the neurons related to this concept and tried again:Adjusted model after steering. Image via monitor.transluce.orgAs you can see, it still output wrong answer. But if you look closely at the output, the logic has changed and its seems quite better — it catches that we need to “shift” to “one of her brothers perspective”. And also, it understood that Alice is a sister (Finally!).The final answer is though still incorrect.I decided to strengthen the “gender roles” concept, thinking it would help the model better understand the roles of the brother and sister in this question, while maintaining its understanding of Alice’s relationship to her siblings.Another adjustment. Image via monitor.transluce.orgOk, the answer was still incorrect, but it seemed that the reasoning thought process improved slightly. The model stated that “Alice’s 2 sisters are being referred to.” The first half of the sentence indicated some understanding (Yes, this is also in the input. And no, I’m not arguing that the model or any model can truly understand — but that’s a discussion for another time) that Alice has two sisters. It also still recogni
Transluce’s new tool is changing the game for AI transparency — a test case and some food for thought
Transluce, a new non-profit research lab with an inspiring mission, has just released (23.10.24) a fascinating tool that provides insights into neuron behavior in LLMs. Or in their own words:
When an AI system behaves unexpectedly, we’d like to understand the “thought process” that explains why the behavior occurred. This lets us predict and fix problems with AI models , surface hidden knowledge, and uncover learned biases and spurious correlations.
To fulfill their mission, they have launched an observability interface where you can input your own prompts, receive responses, and see which neurons are activated. You can then explore the activated neurons and their attribution to the model’s output, all enabled by their novel approach to automatically producing high-quality descriptions of neurons inside language models.
If you want to test the tool, go here. They also offer some helpful tutorials. In this article, I will try to provide another use case and share my own experience.
There are probably many things to know (depending on your background), but I’ll focus on two key features: Activation and Attribution.
Activation measures the (normalized) activation value of the neuron. Llama uses gated MLPs, meaning that activations can be either positive or negative. We normalize by the value of the 10–5 quantile of the neuron across a large dataset of examples.
Attribution measures how much the neuron affects the model’s output. Attribution must be conditioned on a specific output token, and is equal to the gradient of that output token’s probability with respect to the neuron’s activation, times the activation value of the neuron. Attribution values are not normalized, and are reported as absolute values.
Using these two features you can explore the model’s behavior, the neurons behavior and even notice for patterns (or as they call it “clusters”) of neurons’ behavior phenomena.
If the model output isn’t what you expect, or if the model gets it wrong, the tool allows you to steer neurons and ‘fix’ the issue by either strengthening or suppressing concept-related neurons (There are great work on how to steer based on concepts — one of them is this great work).
So, curious enough, I tested this with my own prompt.
I took a simple logic question that most models today fail to solve.
Q: “???????????????????? ???????????? ???? ???????????????????????????????? ???????????? ???? ????????????????????????????. ???????????? ???????????????? ???????????????????????????? ???????????????? ????????????????????’???? ???????????????????????????? ?????????????????”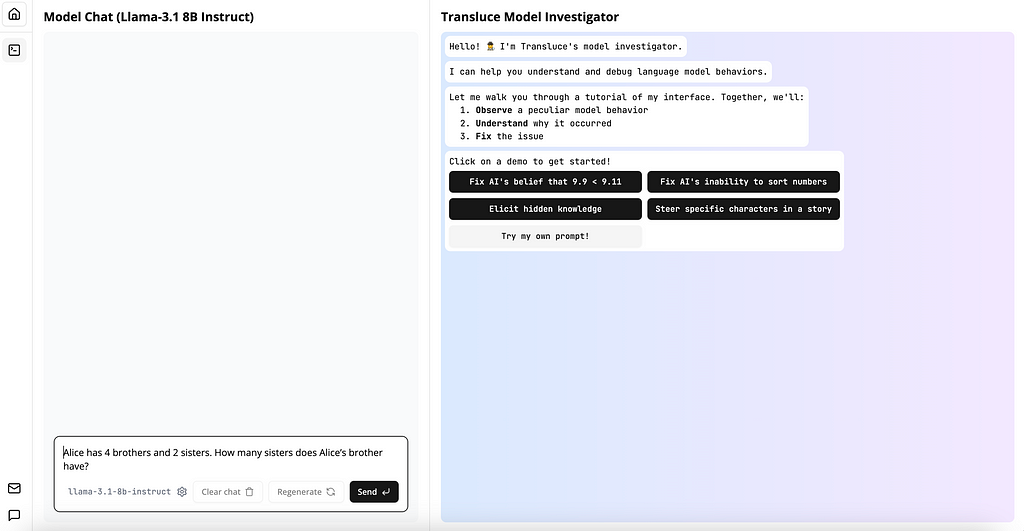
And voila….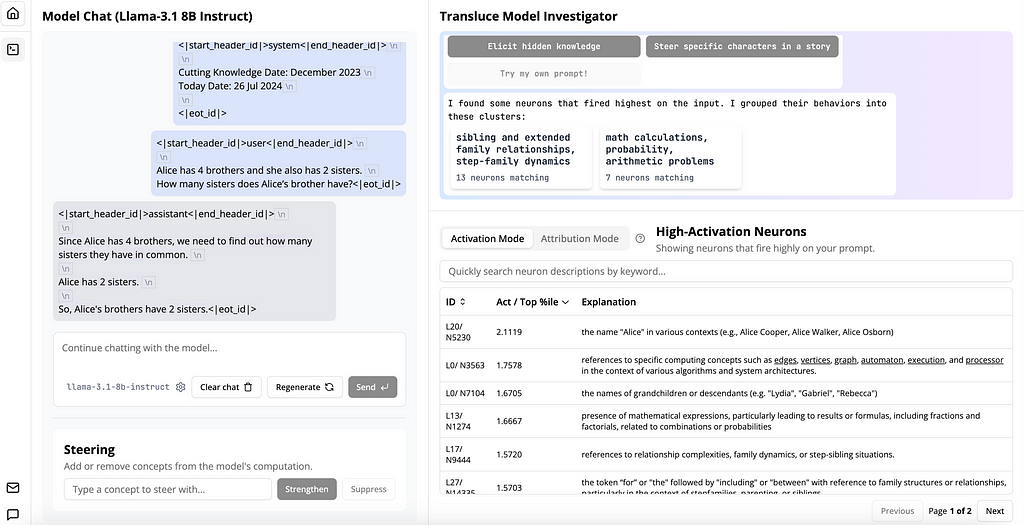
Or not.
On the left side, you can see the prompt and the output. On the right side, you can see the neurons that “fire” the most and observe the main clusters these neurons group into.
If you hover over the tokens on the left, you can see the top probabilities. If you click on one of the tokens, you can find out which neurons contributed to predicting that token.
As you can see, both the logic and the answer are wrong.
“Since Alice has 4 brothers, we need to find out how many sisters they have in common” >>> Ugh! You already know that.
And of course, if Alice has two sisters (which is given in the input), it doesn’t mean Alice’s brother has 2 sisters :(
So, let’s try to fix this. After examining the neurons, I noticed that the “diversity” concept was overly active (perhaps it was confused about Alice’s identity?). So, I tried steering these neurons.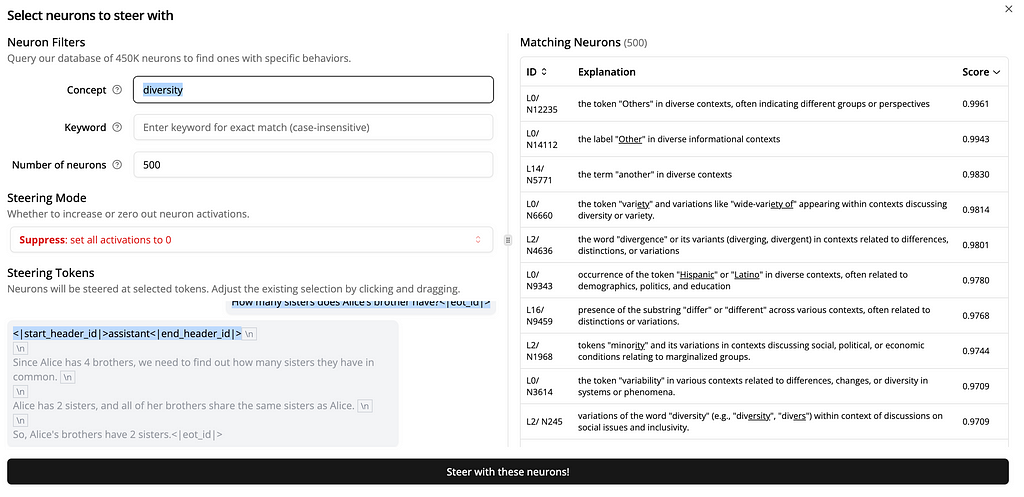
I suppressed the neurons related to this concept and tried again: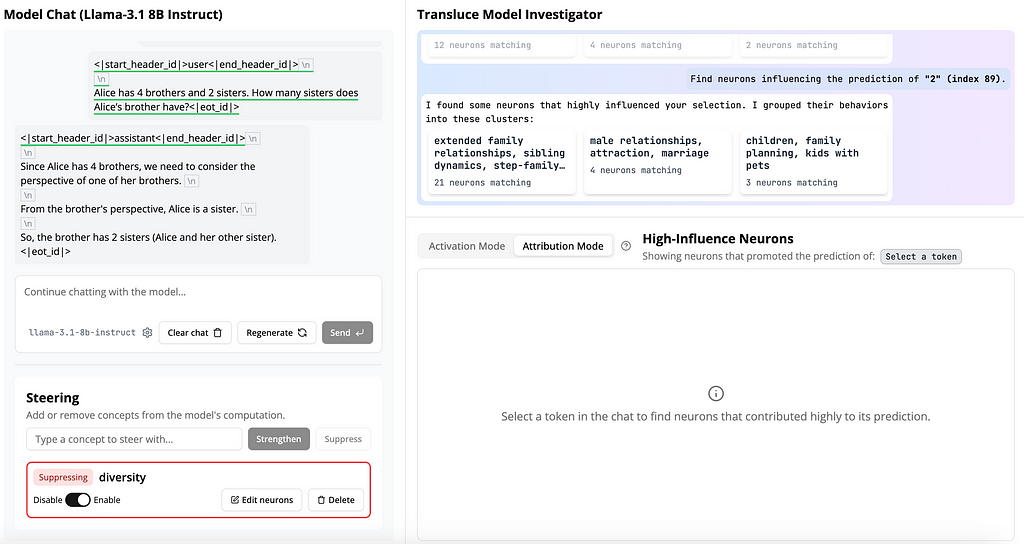
As you can see, it still output wrong answer. But if you look closely at the output, the logic has changed and its seems quite better — it catches that we need to “shift” to “one of her brothers perspective”. And also, it understood that Alice is a sister (Finally!).
The final answer is though still incorrect.
I decided to strengthen the “gender roles” concept, thinking it would help the model better understand the roles of the brother and sister in this question, while maintaining its understanding of Alice’s relationship to her siblings.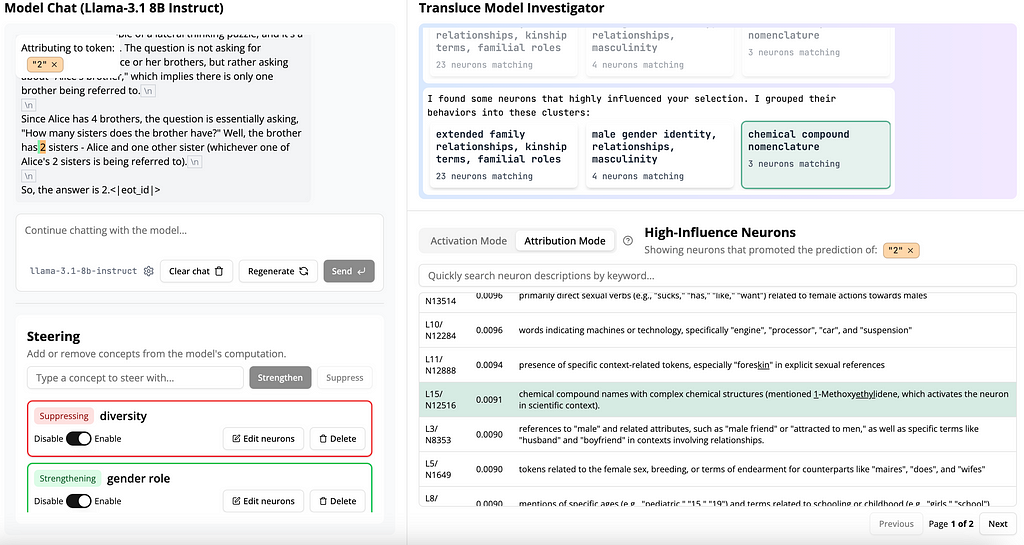
Ok, the answer was still incorrect, but it seemed that the reasoning thought process improved slightly. The model stated that “Alice’s 2 sisters are being referred to.” The first half of the sentence indicated some understanding (Yes, this is also in the input. And no, I’m not arguing that the model or any model can truly understand — but that’s a discussion for another time) that Alice has two sisters. It also still recognized that Alice is a sister herself (“…the brother has 2 sisters — Alice and one other sister…”). But still, the answer was wrong. So close…
Now that we’re close, I noticed an unrelated concept (“chemical compounds and reactions”) influencing the "2" token (highlighted in orange on the left side). I’m not sure why this concept had high influence, but I decided it was irrelevant to the question and suppressed it.
The result?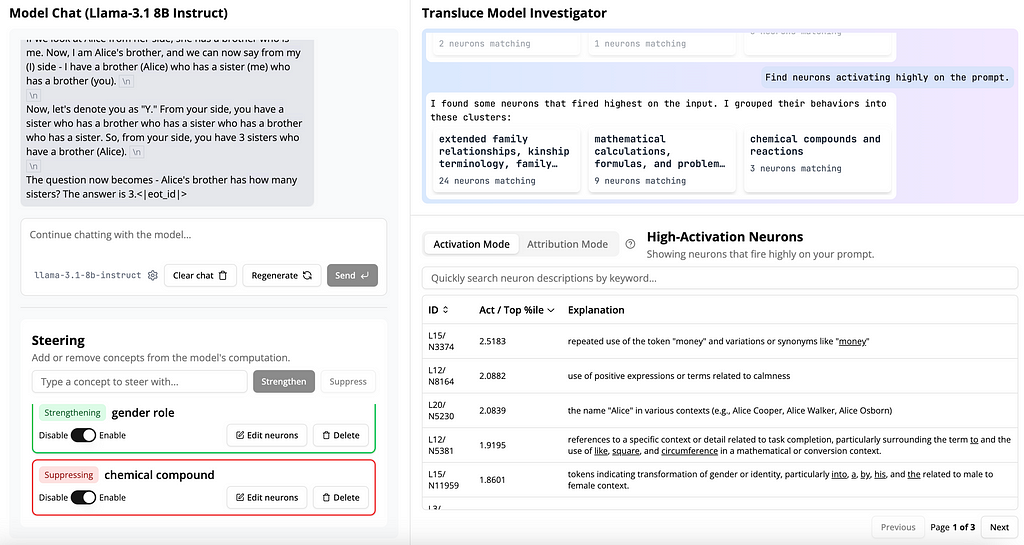
Success!! (ish)
As you can see above, it finally got the answer right.
But…how was the reasoning?
well…
It followed a strange logical process with some role-playing confusion, but it still ended up with the correct answer (if you can explain it, please share).
So, after some trial and error, I got there — almost. After adjusting the neurons related to gender and chemical compounds, the model produced the correct answer, but the reasoning wasn’t quite there. I’m not sure, maybe with more tweaks and adjustments (and maybe better choices of concepts and neurons), I would get both the right answer and the correct logic. I challenge you to try.
This is still experimental and I didn’t use any systematic approach, but to be honest, I’m impressed and think it’s incredibly promising. Why? Because the ability to observe and get descriptions of every neuron, understand (even partially) their influence, and steer behavior (without retraining or prompting) in real time is impressive — and yes, also a bit addictive, so be careful!
Another thought I have: if the descriptions are accurate (reflecting actual behavior), and if we can experiment with different setups manually, why not try building a model based on neuron activations and attribution values? Transluce team, if you're reading this…what do you think?
All in all, great job. I highly recommend diving deeper into this. The ease of use and the ability to observe neuron behavior is compelling, and I believe we’ll see more tools embracing these techniques to help us better understand our models.
I’m now going to test this on some of our most challenging legal reasoning use cases — to see how it captures more complex logical structures.
What does this mean for AI? We’ll have to wait and see… but just like GPT was embraced so quickly and naturally, I think this release opens a new chapter in LLM interpretability. More importantly, it moves us closer to building tools that are better aligned and more responsible.
Now that their work is open source, it’s up to the community to challenge it, improve it, or build on it.
So, give it a try.
In the meantime, what do you think?
Some limitations (very briefly):
- The tool was just released yesterday, and I haven’t had the chance to fully review the entire documentation.
- I tried simple questions successfully, but when I asked similar questions with different attributes, the logic still failed. Generalization is key here — trying to “capture” some generalization within the observability tool would take it to the next level.
- It’s not always reproducible, even with low or zero temperature settings.
- There is no single path to both a correct answer and logical reasoning.
- It involves quite a bit of trial and error. After a few iterations, I got a “feel” for it, but it felt similar to the early days of using GPT — exciting when it worked, but often leaving you wondering, “What really happened here?” So there’s still work to be done.
Discover What Every Neuron in the Llama Model Does was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.










