

Image created by Author with DALL•E 3
Key Takeaways
- Chain of Code (CoC) is a novel approach to interacting with language models, enhancing reasoning abilities through a blend of code writing and selective code emulation.
- CoC extends the capabilities of language models in logic, arithmetic, and linguistic tasks, especially those requiring a combination of these skills.
- With CoC, language models write code and also emulate parts of it that cannot be compiled, offering a unique approach to solving complex problems.
- CoC shows effectiveness for both large and small LMs.
The key idea is to encourage LMs to format linguistic sub-tasks in a program as flexible pseudocode that the compiler can explicitly catch undefined behaviors and hand off to simulate with an LM (as an ‘LMulator’).
New language model (LM) prompting, communication, and training techniques keep emerging to enhance the LM reasoning and performance capabilities. One such emergence is the development of the Chain of Code (CoC), a method intended to advance code-driven reasoning in LMs. This technique is a fusion of traditional coding and the innovative emulation of LM code execution, which creates a powerful tool for tackling complex linguistic and arithmetic reasoning tasks.
CoC is differentiated by its ability to handle intricate problems that blend logic, arithmetic, and language processing, which, as has been known to LM users for quite some time, has long been a challenging feat for standard LMs. CoC’s effectiveness is not limited to large models but extends across various sizes, demonstrating versatility and broad applicability in AI reasoning.
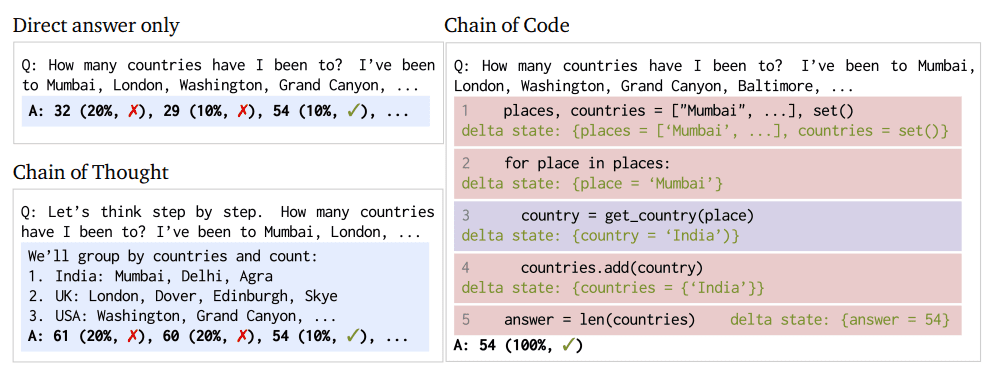
Figure 1: Chain of Code approach and process comparison (Image from paper)
CoC is a paradigm shift in LM functionality; this is not a simple prompting tactic to increase the chance of eliciting the desired response from an LM. Instead, CoC redefines the the LM’s approach to the aforementioned reasoning tasks.
At its core, CoC enables LMs to not only write code but also to emulate parts of it, especially those aspects that are not directly executable. This duality allows LMs to handle a broader range of tasks, combining linguistic nuances with logical and arithmetic problem-solving. CoC is able to format linguistic tasks as pseudocode, and effectively bridge the gap between traditional coding and AI reasoning. This bridging allows for a flexible and more capable system for complex problem-solving. The LMulator, a main component of CoC’s increased capabilities, enables the simulation and interpretation of code execution output that would otherwise not be directly available to the LM.
CoC has shown remarkable success across different benchmarks, significantly outperforming existing approaches like Chain of Thought, particularly in scenarios that require a mix of linguistic and computational reasoning.
Experiments demonstrate that Chain of Code outperforms Chain of Thought and other baselines across a variety of benchmarks; on BIG-Bench Hard, Chain of Code achieves 84%, a gain of 12% over Chain of Thought.

Figure 2: Chain of Code performance comparison (Image from paper)
The implementation of CoC involves a distinctive approach to reasoning tasks, integrating coding and emulation processes. CoC encourages LMs to format complex reasoning tasks as pseudocode, which is then interpreted and solved. This process comprises multiple steps:
- Identifying Reasoning Tasks: Determine the linguistic or arithmetic task that requires reasoning
- Code Writing: The LM writes pseudocode or flexible code snippets to outline a solution
- Emulation of Code: For parts of the code that are not directly executable, the LM emulates the expected outcome, effectively simulating the code execution
- Combining Outputs: The LM combines the results from both actual code execution and its emulation to form a comprehensive solution to the problem
These steps allow LMs to tackle a broader range of reasoning questions by “thinking in code,” thereby enhancing their problem-solving capabilities.
The LMulator, as part of the CoC framework, can significantly aid in refining both code and reasoning in a few specific ways:
- Error Identification and Simulation: When a language model writes code that contains errors or non-executable parts, the LMulator can simulate how this code might behave if it were to run, revaling logical errors, infinite loops, or edge cases, and guiding the LM to rethink and adjust the code logic.
- Handling Undefined Behaviors: In cases where the code involves undefined or ambiguous behavior that a standard interpreter cannot execute, the LMulator uses the language model’s understanding of context and intent to infer what the output or behavior should be, providing a reasoned, simulated output where traditional execution would fail.
- Improving Reasoning in Code: When a mix of linguistic and computational reasoning is required, the LMulator allows the language model to iterate over its own code generation, simulating the results of various approaches, effectively ‘reasoning’ through code, leading to more accurate and efficient solutions.
- Edge Case Exploration: The LMulator can explore and test how code handles edge cases by simulating different inputs, which is particularly useful in ensuring that the code is robust and can handle a variety of scenarios.
- Feedback Loop for Learning: As the LMulator simulates and identifies issues or potential improvements in the code, this feedback can be used by the language model to learn and refine its approach to coding and problem-solving, which is an ongoing learning process that improves the model’s coding and reasoning capabilities over time.
The LMulator enhances the language model’s ability to write, test, and refine code by providing a platform for simulation and iterative improvement.
The CoC technique is an advancement in enhancing the reasoning abilities of LMs. CoC broadens the scope of problems LMs can tackle by integrating code writing with selective code emulation. This approach demonstrates the potential for AI to handle more complex, real-world tasks that require nuanced thinking. Importantly, CoC has proven to excel in both small and large LMs, enabling a pathway for the increasing array of smaller models to potentially improve their reasoning capabilities and bring their effectiveness closer to that of larger models.
For a more in-depth understanding, refer to the full paper here.
Matthew Mayo (@mattmayo13) holds a Master’s degree in computer science and a graduate diploma in data mining. As Editor-in-Chief of KDnuggets, Matthew aims to make complex data science concepts accessible. His professional interests include natural language processing, machine learning algorithms, and exploring emerging AI. He is driven by a mission to democratize knowledge in the data science community. Matthew has been coding since he was 6 years old.

