
The global phenomenon of LLM (Large Language Model) products, exemplified by the widespread adoption of ChatGPT, has gathered significant attention. A consensus has emerged among many individuals regarding the advantages of LLMs in comprehending natural language conversations and aiding humans in creative tasks. Despite this acknowledgment, the following question arises: what lies ahead in the evolution of these technologies?
A noticeable trend indicates a shift towards multi-modality, enabling models to comprehend diverse modalities such as images, videos, and audio. GPT-4, a multi-modal model with remarkable image understanding capabilities, has recently been revealed, accompanied by audio-processing capabilities.
Since the advent of deep learning, cross-modal interfaces have frequently relied on deep embeddings. These embeddings exhibit proficiency in preserving image pixels when trained as autoencoders and can also achieve semantic meaningfulness, as demonstrated by recent models like CLIP. When contemplating the relationship between speech and text, text naturally serves as an intuitive cross-modal interface, a fact often overlooked. The conversion of speech audio to text effectively preserves content, enabling the reconstruction of speech audio using mature text-to-speech techniques. Additionally, transcribed text is believed to encapsulate all the necessary semantic information. Drawing an analogy, we can similarly “transcribe” an image into text, a process commonly known as image captioning. However, typical image captions fall short in content preservation, emphasizing precision over comprehensiveness. Image captions struggle to address a wide range of visual inquiries effectively.
Despite the limitations of image captions, precise and comprehensive text, if achievable, remains a promising option, both intuitively and practically. From a practical standpoint, text serves as the native input domain for LLMs. Employing text eliminates the need for the adaptive training often associated with deep embeddings. Considering the prohibitive cost of training and adapting top-performing LLMs, text’s modular design opens up more possibilities. So, how can we achieve precise and comprehensive text representations of images? The solution lies in resorting to the classic technique of autoencoding.
In contrast to conventional autoencoders, the employed approach involves utilizing a pre-trained text-to-image diffusion model as the decoder, with text as the natural latent space. The encoder is trained to convert an input image into text, which is then input into the text-to-image diffusion model for decoding. The objective is to minimize reconstruction error, requiring the latent text to be precise and comprehensive, even if it often combines semantic concepts into a “scrambled caption” of the input image.
Recent advancements in generative text-to-image models demonstrate exceptional proficiency in transforming complex text, even comprising tens of words, into highly detailed images that closely align with given prompts. This underscores the remarkable capability of these generative models to process intricate text into visually coherent outputs. By incorporating one such generative text-to-image model as the decoder, the optimized encoder explores the expansive latent space of text, unveiling the extensive visual-language knowledge encapsulated within the generative model.
Sustained by these findings, the researchers have developed De-Diffusion, an autoencoder exploiting text as a robust cross-modal interface. The overview of its architecture is depicted below.
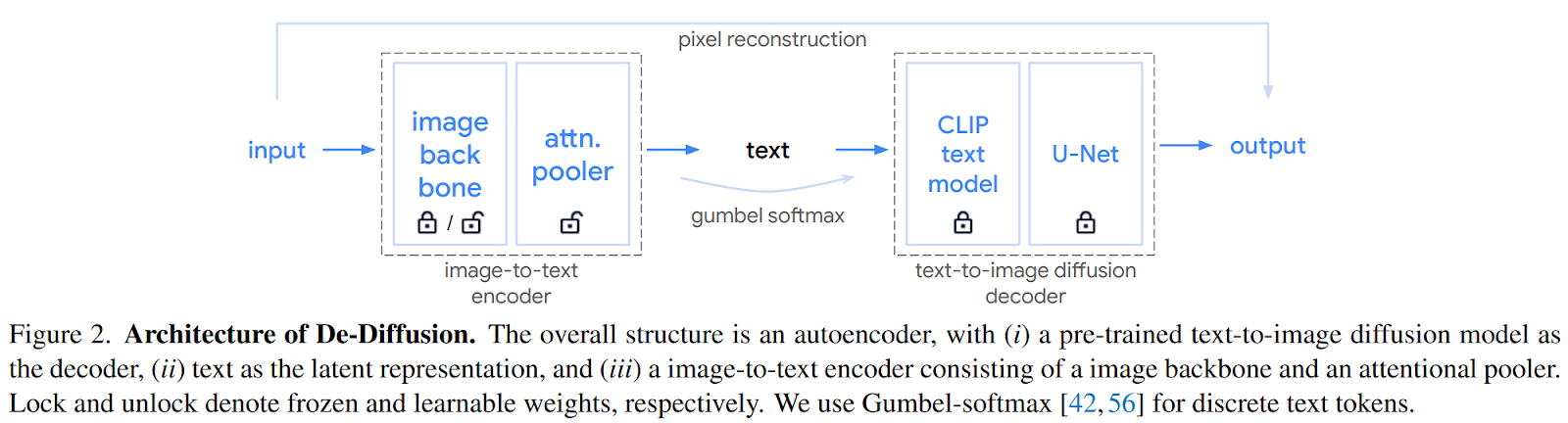
De-Diffusion comprises an encoder and a decoder. The encoder is trained to transform an input image into descriptive text, which is then fed into a fixed pre-trained text-to-image diffusion decoder to reconstruct the original input.
Experiments on the proposed method reveal that De-Diffusion-generated texts adeptly capture semantic concepts in images, enabling diverse vision-language applications when used as text prompts. De-Diffusion text demonstrates generalizability as a transferable prompt for different text-to-image tools. Quantitative evaluation using reconstruction FID indicates that De-Diffusion text significantly surpasses human-annotated captions as prompts for a third-party text-to-image model. Additionally, De-Diffusion text facilitates off-the-shelf LLMs in performing open-ended vision-language tasks by simply prompting them with few-shot task-specific examples. These results seem to demonstrate that De-Diffusion text effectively bridges human interpretations and various off-the-shelf models across domains.
This was the summary of De-Diffusion, a novel AI technique to convert an input image into a piece of information-rich text that can act as a flexible interface between different modalities, enabling diverse audio-vision-language applications. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.

