
Reinforcement Learning from Human Feedback (RLHF) enhances the alignment of Pretrained Large Language Models (LLMs) with human values, improving their applicability and reliability. However, aligning LLMs through RLHF faces significant hurdles, primarily due to the process’s computational intensity and resource demands. Training LLMs with RLHF is a complex, resource-intensive task that limits its widespread adoption.
Different techniques like RLHF, RLAIF, and LoRA have been developed to overcome the existing limitations. RLHF works by fitting a reward model on preferred outputs and training a policy using reinforcement learning algorithms like PPO. Labeling examples for training reward models can be costly, so some works have replaced human feedback with AI feedback. Parameter Efficient Fine-Tuning (PEFT) methods reduce the number of trainable parameters in PLMs while maintaining performance. LoRA, an example of a PEFT method, factorizes weight updates into trainable low-rank matrices, allowing training of only a small fraction of the total parameters.
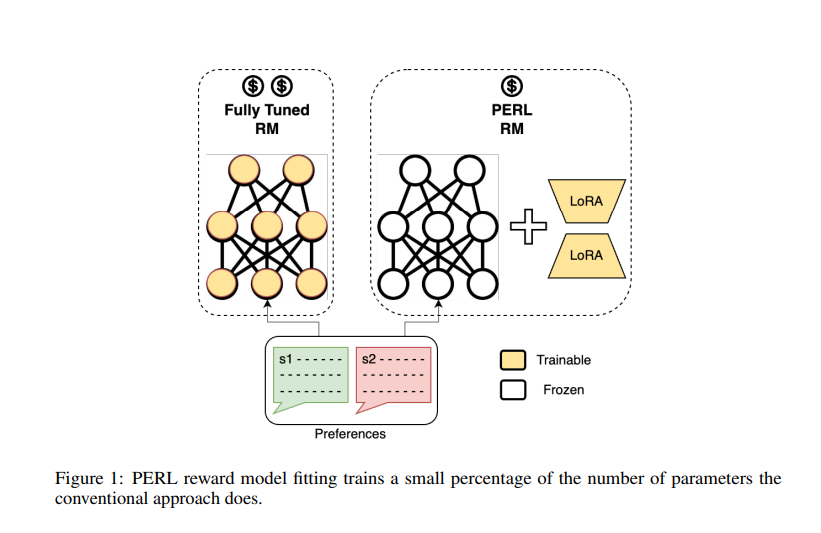
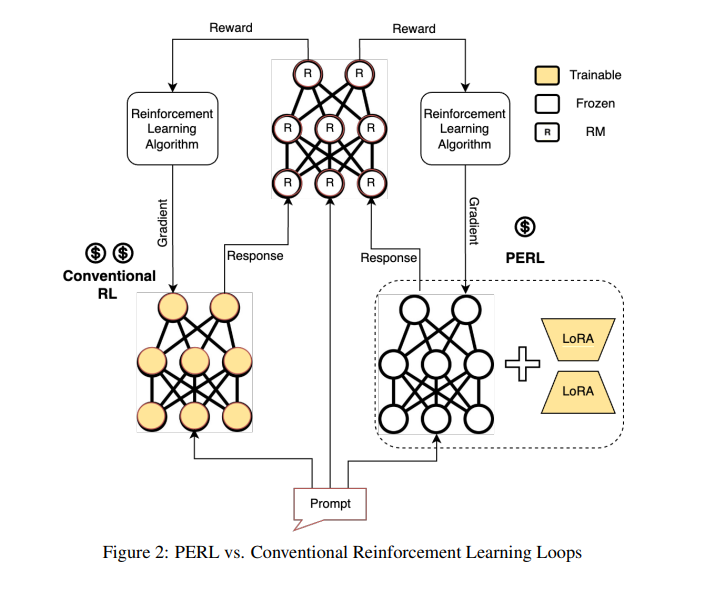
Google’s team of researchers introduces a revolutionary methodology, Parameter-Efficient Reinforcement Learning (PERL). This innovative approach harnesses LoRA to refine models more efficiently, maintaining the performance of traditional RLHF methods while significantly reducing computational and memory requirements. PERL allows selective training of these adapters while preserving the core model, drastically reducing the memory footprint and computational load required for training without compromising the model’s performance.
PERL revolutionizes the training of RLHF models by implementing LoRA for enhanced parameter efficiency across a wide range of datasets. It leverages diverse data, including text summarization from Reddit TL;DR and BOLT English SMS/Chat, harmless response preference modeling, helpfulness metrics from the Stanford Human Preferences Dataset, and UI Automation tasks derived from human demonstrations. PERL utilizes crowdsourced Taskmaster datasets, focusing on conversational interactions in coffee ordering and ticketing scenarios, to refine model responses.
The research reveals PERL’s efficiency in aligning with conventional RLHF outcomes, significantly reducing memory usage by about 50% and accelerating Reward Model training by up to 90%. LoRA-enhanced models match the accuracy of fully trained counterparts with half the peak HBM usage and 40% faster training. Qualitatively, PERL maintains RLHF’s high performance with reduced computational demands, offering a promising avenue for employing ensemble models like Mixture-of-LoRA for robust, cross-domain generalization and employing weight-averaged adapters to lower reward hacking risks at reduced computational costs.
In conclusion, Google’s PERL method marks a significant leap forward in aligning AI with human values and preferences. By mitigating the computational challenges associated with RLHF, PERL enhances the efficiency and applicability of LLMs and sets a new benchmark for future research in AI alignment. The innovation of PERL is a vivid illustration of how parameter-efficient methods can revolutionize the landscape of artificial intelligence, making it more accessible, efficient, and aligned with human values.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.

