
Contrastive pre-training using large, noisy image-text datasets has become popular for building general vision representations. These models align global image and text features in a shared space through similar and dissimilar pairs, excelling in tasks like image classification and retrieval. However, they need help with fine-grained tasks such as localization and spatial relationships. Recent efforts incorporate losses between image patches and text tokens to capture finer details, improving performance in fine-grained retrieval, image classification, object detection, and segmentation. Despite these advancements, challenges like computational expense and reliance on pretrained models persist.
Researchers from Google DeepMind have developed SPARse Fine-grained Contrastive Alignment (SPARC), a method for pretraining fine-grained multimodal representations from image-text pairs. SPARC focuses on learning groups of image patches corresponding to individual words in captions. It utilizes a sparse similarity metric to compute language-grouped vision embeddings for each token, allowing detailed information capture in a computationally efficient manner. SPARC combines fine-grained sequence-wise loss with a contrastive loss, enhancing performance in coarse-grained tasks like classification and fine-grained tasks like retrieval, object detection, and segmentation. The method also improves model faithfulness and captioning in foundational vision-language models.
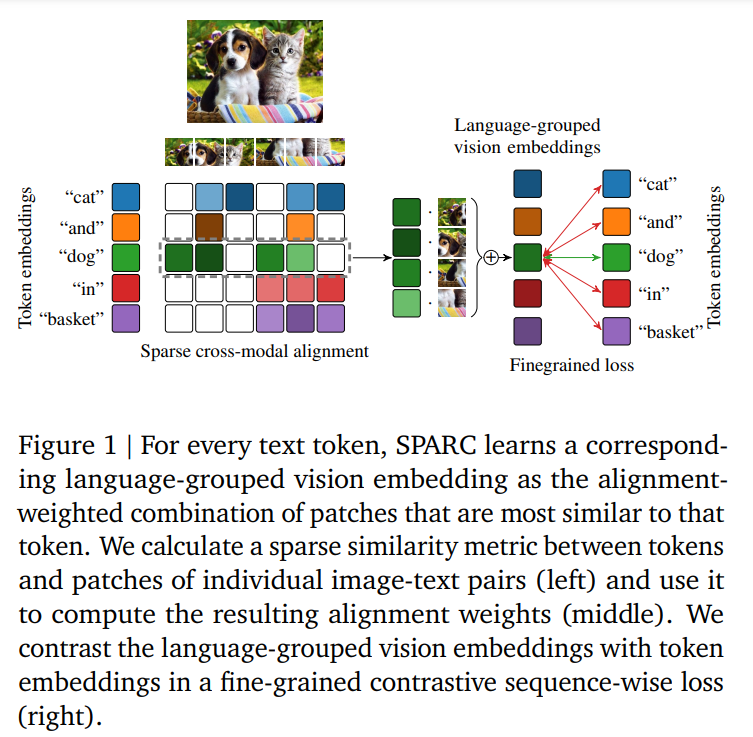
Contrastive image-text pre-training methods like CLIP and ALIGN have popularized learning general visual representations by leveraging textual supervision from large-scale data scraped from the internet.FILIP proposes a cross-modal late interaction mechanism to optimize the token-wise maximum similarity between image and text tokens, addressing the problem of coarse visual representation in global matching. PACL starts from CLIP-pre-trained vision and text encoders and trains an adapter through a contrastive objective to improve fine-grained understanding. GLoRIA builds localized visual representations by contrasting attention-weighted patch embeddings with text tokens, but it becomes computationally intensive for large batch sizes.
SPARC is a method for pretraining fine-grained multimodal representations from image-text pairs. It uses a sparse similarity metric between image patches and language tokens to learn a grouping of image patches for each token in the caption. The token and language-grouped vision embeddings are then contrasted through a fine-grained sequence-wise loss that only depends on individual samples, enabling detailed information to be learned computationally inexpensively. SPARC combines this fine-grained loss with a contrastive loss between global image and text embeddings to encode global and local information simultaneously.
The SPARC study assesses its performance across image-level tasks like classification and region-level tasks such as retrieval, object detection, and segmentation. It outperforms other methods in both task types and enhances model faithfulness and captioning in foundational vision-language models. In the evaluation, zero-shot segmentation is conducted by computing patch embeddings and determining class matches through cosine similarity with text embeddings of ground-truth classes. Intersection over Union (IoU) is then calculated to measure the accuracy of predicted and ground-truth segmentations for each class.
SPARC improves performance over competing approaches in image-level tasks (classification) and region-level tasks (retrieval, object detection, and segmentation). SPARC achieves improved model faithfulness and captioning in foundational vision-language models. The evaluation of SPARC includes zero-shot segmentation, where patch embeddings of an image are compared to text embeddings of ground-truth classes. The matching class for each patch is assigned based on maximum cosine similarity, and IoU is calculated for each class. The study mentions using Flamingo’s Perceiver Resampler in training SPARC, which suggests incorporating this method in the experimental setup.

In conclusion, SPARC is a method that helps pretrain fine-grained multimodal representations from image-text pairs. To achieve this, it uses fine-grained contrastive alignment and a contrastive loss between global image and text embeddings. SPARC outperforms competing approaches in image-level tasks such as classification and region-level tasks such as retrieval, object detection, and segmentation. SPARC improves model faithfulness and captioning in foundational vision-language models. To evaluate SPARC, zero-shot segmentation is used where patch embeddings of an image are compared to text embeddings of ground-truth classes. The study suggests using Flamingo’s Perceiver Resampler in training SPARC and recommends incorporating it in the experimental setup.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.

