

Image by Editor
Large Language Models (LLMs) like OpenAI’s GPT-3, Google’s BERT, and Meta’s LLaMA are revolutionizing various sectors with their ability to generate a wide array of text?—?from marketing copy and data science scripts to poetry.
Even though ChatGPT’s intuitive interface has managed to be in most people’s devices today, there’s still a vast landscape of untapped potential for using LLMs in diverse software integrations.
The main problem?
Most applications require more fluid and native communication with LLMs.
And this is precisely where LangChain kicks in!
If you are interested in Generative AI and LLMs, this tutorial is tailor-made for you.
So… let’s start!
Just in case you have been living within a cave and haven’t gotten any news lately, I’ll briefly explain Large Language Models or LLMs.
An LLM is a sophisticated artificial intelligence system built to mimic human-like textual understanding and generation. By training on enormous data sets, these models discern intricate patterns, grasp linguistic subtleties, and produce coherent outputs.
If you wonder how to interact with these AI-powered models, there are two main ways to do so:
- The most common and direct way is talking or chatting with the model. It involves crafting a prompt, sending it to the AI-powered model, and getting a text-based output as a response.
- Another method is converting text into numerical arrays. This process involves composing a prompt for the AI and receiving a numerical array in return. What is commonly known as an “embedding”. It has experienced a recent surge in Vector Databases and semantic search.
And it is precisely these two main problems that LangChain tries to address. If you are interested in the main problems of interacting with LLMs, you can check this article here.
LangChain is an open-source framework built around LLMs. It brings to the table an arsenal of tools, components, and interfaces that streamline the architecture of LLM-driven applications.
With LangChain, engaging with language models, interlinking diverse components, and incorporating assets like APIs and databases become a breeze. This intuitive framework substantially simplifies the LLM application development journey.
The core idea of Long Chain is that we can connect together different components or modules, also known as chains, to create more sophisticated LLM-powered solutions.
Here are some standout features of LangChain:
- Customizable prompt templates to standardize our interactions.
- Chain link components tailored for sophisticated use cases.
- Seamless integration with leading language models, including OpenAI’s GPTs and those on HuggingFace Hub.
- Modular components for a mix-and-match approach to assess any specific problem or task.
Image by Author
LangChain is distinguished by its focus on adaptability and modular design.
The main idea behind LangChain is breaking down the natural language processing sequence into individual parts, allowing developers to customize workflows based on their requirements.
Such versatility positions LangChain as a prime choice for building AI solutions in different situations and industries.
Some of its most important components are…
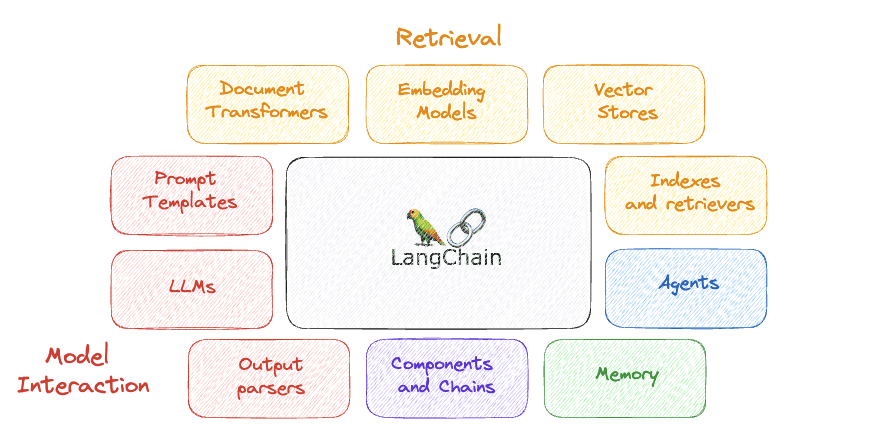
Image by Author
1. LLMs
LLMs are fundamental components that leverage vast amounts of training data to understand and generate human-like text. They are at the core of many operations within LangChain, providing the necessary language processing capabilities to analyze, interpret, and respond to text input.
Usage: Powering chatbots, generating human-like text for various applications, aiding in information retrieval, and performing other language processing
2. Prompt templates
Prompts are fundamental for interacting with LLM, and when working on specific tasks, their structure tends to be similar. Prompt templates, which are preset prompts usable across chains, allow standardization of “prompts” by adding specific values. This enhances the adaptability and customization of any LLM.
Usage: Standardizing the process of interacting with LLMs.
3. Output Parsers
Output parsers are components that take the raw output from a preceding stage in the chain and convert it into a structured format. This structured data can then be used more effectively in subsequent stages or delivered as a response to the end user.
Usage: For instance, in a chatbot, an output parser might take the raw text response from a language model, extract key pieces of information, and format them into a structured reply.
4. Components and chains
In LangChain, each component acts as a module responsible for a particular task in the language processing sequence. These components can be connected to form chains for customized workflows.
Usage: Generating sentiment detection and response generator chains in a specific chatbot.
5. Memory
Memory in LangChain refers to a component that provides a storage and retrieval mechanism for information within a workflow. This component allows for the temporary or persistent storage of data that can be accessed and manipulated by other components during the interaction with the LLM.
Usage: This is useful in scenarios where data needs to be retained across different stages of processing, for example, storing conversation history in a chatbot to provide context-aware responses.
6. Agents
Agents are autonomous components capable of taking actions based on the data they process. They can interact with other components, external systems, or users, to perform specific tasks within a LangChain workflow.
Usage: For instance, an agent might handle user interactions, process incoming requests, and coordinate the flow of data through the chain to generate appropriate responses.
7. Indexes and Retrievers
Indexes and Retrievers play a crucial role in managing and accessing data efficiently. Indexes are data structures holding information and metadata from the model’s training data. On the other hand, retrievers are mechanisms that interact with these indexes to fetch relevant data based on specified criteria and allow the model to reply better by supplying relevant context.
Usage: They are instrumental in quickly fetching relevant data or documents from a large dataset, which is essential for tasks like information retrieval or question answering.
8. Document Transformers
In LangChain, Document Transformers are specialized components designed to process and transform documents in a way that makes them suitable for further analysis or processing. These transformations may include tasks such as text normalization, feature extraction, or the conversion of text into a different format.
Usage: Preparing text data for subsequent processing stages, such as analysis by machine learning models or indexing for efficient retrieval.
9. Embedding Models
They are used to convert text data into numerical vectors in a high-dimensional space. These models capture semantic relationships between words and phrases, enabling a machine-readable representation. They form the foundation for various downstream Natural Language Processing (NLP) tasks within the LangChain ecosystem.
Usage: Facilitating semantic searches, similarity comparisons, and other machine-learning tasks by providing a numerical representation of text.
10. Vector stores
Type of database system that specializes to store and search information via embeddings, essentially analyzing numerical representations of text-like data. VectorStore serves as a storage facility for these embeddings.
Usage: Allowing efficient search based on semantic similarity.
Installing it using PIP
The first thing we have to do is make sure we have LangChain installed in our environment.
Environment setup
Utilizing LangChain typically means integrating with diverse model providers, data stores, APIs, among other components. And as you already know, like any integration, supplying the relevant and correct API keys is crucial for LangChain’s operation.
Imagine we want to use our OpenAI API. We can easily accomplish this in two ways:
- Setting up key as an environment variable
or
import os
os.environ['OPENAI_API_KEY'] = “...”
If you choose not to establish an environment variable, you have the option to provide the key directly through the openai_api_key named parameter when initiating the OpenAI LLM class:
- Directly set up the key in the relevant class.
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
Switching between LLMs becomes straightforward
LangChain provides an LLM class that allows us to interact with different language model providers, such as OpenAI and Hugging Face.
It is quite easy to get started with any LLM, as the most basic and easiest-to-implement functionality of any LLM is just generating text.
However, asking the very same prompt to different LLMs at once is not so easy.
This is where LangChain kicks in…
Getting back to the easiest functionality of any LLM, we can easily build an application with LangChain that gets a string prompt and returns the output of our designated LLM..
Code by Author
We can simply use the same prompt and get the response of two different models within few lines of code!
Code by Author
Impressive… right?
Giving structure to our prompts with prompt templates
A common issue with Language Models (LLMs) is their inability to escalate complex applications. LangChain addresses this by offering a solution to streamline the process of creating prompts, which is often more intricate than just defining a task as it requires outlining the AI’s persona and ensuring factual accuracy. A significant part of this involves repetitive boilerplate text. LangChain alleviates this by offering prompt templates, which auto-include boilerplate text in new prompts, thus simplifying prompt creation and ensuring consistency across different tasks.
Code by Author
Getting structured responses with output parsers
In chat-based interactions, the model’s output is merely text. Yet, within software applications, having a structured output is preferable as it allows for further programming actions. For instance, when generating a dataset, receiving the response in a specific format such as CSV or JSON is desired. Assuming a prompt can be crafted to elicit a consistent and suitably formatted response from the AI, there’s a need for tools to manage this output. LangChain caters to this requirement by offering output parser tools to handle and utilize the structured output effectively.
Code by Author
You can go check the whole code on my GitHub.
Not long ago, the advanced capabilities of ChatGPT left us in awe. Yet, the technological environment is ever-changing, and now tools like LangChain are at our fingertips, allowing us to craft outstanding prototypes from our personal computers in just a few hours.
LangChain, a freely available Python platform, provides a means for users to develop applications anchored by LLMs (Language Model Models). This platform delivers a flexible interface to a variety of foundational models, streamlining prompt handling and acting as a nexus for elements like prompt templates, more LLMs, external information, and other resources via agents, as of the current documentation.
Imagine chatbots, digital assistants, language translation tools, and sentiment analysis utilities; all these LLM-enabled applications come to life with LangChain. Developers utilize this platform to craft custom-tailored language model solutions addressing distinct requirements.
As the horizon of natural language processing expands, and its adoption deepens, the realm of its applications seems boundless.
Josep Ferrer is an analytics engineer from Barcelona. He graduated in physics engineering and is currently working in the Data Science field applied to human mobility. He is a part-time content creator focused on data science and technology. You can contact him on LinkedIn, Twitter or Medium.

