

How to Tackle the Weekend Quiz Like a Bayesian
Do you know which of these is a malmsey? Can you make a good guess?A couple of weeks ago, this question came up in the Sydney Morning Herald Good Weekend quiz:What is malmsey: a mild hangover, a witch’s curse or a fortified wine?Assuming we have no inkling of the answer, is there any way to make an informed guess in this situation? I think there is.Feel free to have a think about it before reading on.A witch with a mild hangover from fortified wine, created using Gemini Imagen 3Is there really nothing we can bring to this question?Looking at this word, it feels like it could mean any of these options. The multiple choice, of course, is constructed to feel this way.But there is a rational approach we can take here, which is to recognise that each of these options have different base rates. This is to say, forgetting about what is and isn’t a malmsey for a moment, we can sense that there probably aren’t as many names for hangovers as there are for witch’s curses, and there are bound to be even more names for all the different fortified wines out there.To quantify this further:How many words for mild hangovers are there likely to be? Perhaps 1?How many words for witch’s curses are there likely to be? I am no expert but I can already think of some synonyms so perhaps 10?How many words for fortified wines are there likely to be? Again, not an expert but I can name a few (port, sherry…) and there are likely to be many more so perhaps 100?And so, with no other clues into which might be the correct answer, fortified wine would be a well reasoned guess. Based on my back-of-envelope estimates above, fortified wine would be x100 as likely to be correct as the mild hangover and x10 as likely as the witch’s curse.Even if I am off with those quantities, I feel confident at least in this order of base rates so will go ahead and lock in fortified wine as my best guess.Bingo!Base rate neglectThe reasoning may seem trivial but overlooking base rates when making judgements like this is one of the great human biases talked about by Kahneman and Tversky and many others since. Once we see it, we see it everywhere.Consider the following brain teaser from Rolf Dobelli’s The Art of Thinking Clearly:Mark is a thin man from Germany with glasses who likes to listen to Mozart. Which is more likely? That Mark is A) a truck driver or (B) a professor of literature in Frankfurt?The temptation is to go with B based on the stereotype we associate with the description, but the more reasonable guess would be A because Germany has many, many more truck drivers than Frankfurt has literature professors.The puzzle is a riff on Kahneman and Tversky’s librarian-farmer character portrait (see Judgment under Uncertainty) which also provides the framing for the great 3B1B explainer on Bayes’ Theorem where this kind of thinking process is mapped to the conditional and marginal probabilities (base rates) of the Bayes’ formula.Seeing the thinking trapsThe Bayesian framework helps us to more clearly see two common traps in probabilistic reasoning. In Kahneman and Tversky’s language, we could say it provides a tool for System II (‘slow’) thinking to override our impulsive and error-prone System I (‘fast’) thinking.The first insight is that conditional probability of one thing given another p(A|B) is not the same as the probability of the reverse p(B|A), though in day-to-day life we are often tempted to make judgments as if they are the same.In the Dobelli example, this is the difference of:P(????|????????) — Probability that ????) Mark is a thin man from Germany with glasses who likes to listen to Mozart given that ????????) Mark is a literature professor in FrankfurtP(????????|????) — Probability that ????????) Mark is a literature professor in Frankfurt given that ????) Mark is a thin man from Germany with glasses who likes to listen to MozartIf stereotypes are to be believed, the P(????|????????) above seems quite likely, whereas p(????????|????) is unlikely because we would expect there to be many other people in Germany who fit the same description but aren’t literature professors.The second insight is that these two conditional probabilities are related to each other, so knowing one can lead us to the other. What we need in order to connect the two are the individual base rates of A and B, and the scaling factor is in fact a simple ratio of the two base rates as follows:Image created by authorThis is the Bayes’ formula.Bayesian Reasoning — step by stepSo how does this help us?Outside of textbooks and toy examples, we wouldn’t expect to have all the numbers available to us to plug into Bayes’ formula but still it provides a useful framework for organising our knowns and unknowns and formalising a reasoned guess.For example, for the Dobelli scenario, we might start with the following guesstimates:% of professors who wear glasses and fit the description: 25% (1 in every 4)% of people in Germany who are literature professors in Frankfurt: 0.0002% (1
Do you know which of these is a malmsey? Can you make a good guess?
A couple of weeks ago, this question came up in the Sydney Morning Herald Good Weekend quiz:
What is malmsey: a mild hangover, a witch’s curse or a fortified wine?
Assuming we have no inkling of the answer, is there any way to make an informed guess in this situation? I think there is.
Feel free to have a think about it before reading on.

Is there really nothing we can bring to this question?
Looking at this word, it feels like it could mean any of these options. The multiple choice, of course, is constructed to feel this way.
But there is a rational approach we can take here, which is to recognise that each of these options have different base rates. This is to say, forgetting about what is and isn’t a malmsey for a moment, we can sense that there probably aren’t as many names for hangovers as there are for witch’s curses, and there are bound to be even more names for all the different fortified wines out there.
To quantify this further:
- How many words for mild hangovers are there likely to be? Perhaps 1?
- How many words for witch’s curses are there likely to be? I am no expert but I can already think of some synonyms so perhaps 10?
- How many words for fortified wines are there likely to be? Again, not an expert but I can name a few (port, sherry…) and there are likely to be many more so perhaps 100?
And so, with no other clues into which might be the correct answer, fortified wine would be a well reasoned guess. Based on my back-of-envelope estimates above, fortified wine would be x100 as likely to be correct as the mild hangover and x10 as likely as the witch’s curse.
Even if I am off with those quantities, I feel confident at least in this order of base rates so will go ahead and lock in fortified wine as my best guess.
Base rate neglect
The reasoning may seem trivial but overlooking base rates when making judgements like this is one of the great human biases talked about by Kahneman and Tversky and many others since. Once we see it, we see it everywhere.
Consider the following brain teaser from Rolf Dobelli’s The Art of Thinking Clearly:
Mark is a thin man from Germany with glasses who likes to listen to Mozart. Which is more likely? That Mark is A) a truck driver or (B) a professor of literature in Frankfurt?
The temptation is to go with B based on the stereotype we associate with the description, but the more reasonable guess would be A because Germany has many, many more truck drivers than Frankfurt has literature professors.
The puzzle is a riff on Kahneman and Tversky’s librarian-farmer character portrait (see Judgment under Uncertainty) which also provides the framing for the great 3B1B explainer on Bayes’ Theorem where this kind of thinking process is mapped to the conditional and marginal probabilities (base rates) of the Bayes’ formula.
Seeing the thinking traps
The Bayesian framework helps us to more clearly see two common traps in probabilistic reasoning. In Kahneman and Tversky’s language, we could say it provides a tool for System II (‘slow’) thinking to override our impulsive and error-prone System I (‘fast’) thinking.
The first insight is that conditional probability of one thing given another p(A|B) is not the same as the probability of the reverse p(B|A), though in day-to-day life we are often tempted to make judgments as if they are the same.
In the Dobelli example, this is the difference of:
- P(????|????????) — Probability that ????) Mark is a thin man from Germany with glasses who likes to listen to Mozart given that ????????) Mark is a literature professor in Frankfurt
- P(????????|????) — Probability that ????????) Mark is a literature professor in Frankfurt given that ????) Mark is a thin man from Germany with glasses who likes to listen to Mozart
If stereotypes are to be believed, the P(????|????????) above seems quite likely, whereas p(????????|????) is unlikely because we would expect there to be many other people in Germany who fit the same description but aren’t literature professors.
The second insight is that these two conditional probabilities are related to each other, so knowing one can lead us to the other. What we need in order to connect the two are the individual base rates of A and B, and the scaling factor is in fact a simple ratio of the two base rates as follows:
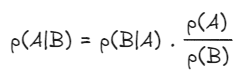
This is the Bayes’ formula.
Bayesian Reasoning — step by step
So how does this help us?
Outside of textbooks and toy examples, we wouldn’t expect to have all the numbers available to us to plug into Bayes’ formula but still it provides a useful framework for organising our knowns and unknowns and formalising a reasoned guess.
For example, for the Dobelli scenario, we might start with the following guesstimates:
- % of professors who wear glasses and fit the description: 25% (1 in every 4)
- % of people in Germany who are literature professors in Frankfurt: 0.0002% (1 in every 500,000)
- % of truck driver who wear glasses and fit the description: 0.2% (1 in every 500)
- % of people in Germany who are truck drivers: 0.1% (1 in every 1,000)
- % of the general population who wear glasses and fit the description: 0.2% (1 in every 500)
- Population of Germany: ~85m
All these parameters are my estimates based on my personal worldview. Only the population of Germany is a data point I could look up, but these will help me to reason rationally about the Dobelli question.
The next step is to frame these in contingency tables, which show the relative frequencies of each of the events occurring, both together and individually. By starting with the total population and applying our percentage estimates, we can start to fill out two tables for the Frankfurt professors and truck drivers each fitting the description (for this section, feel free to also follow along in this spreadsheet):

The four white boxes represent the four ways in which the two events can occur:
- A and B
- A but not B
- B but not A
- Neither A nor B
The margins, shaded in grey, represent the total frequencies of each event regardless of overlap, which is just the sum of the rows and columns. Base rates come from these margins, which is why they are often referred to as marginal probabilities.
Next, we can fill in the blanks like a sudoku by making all the rows and columns add up:
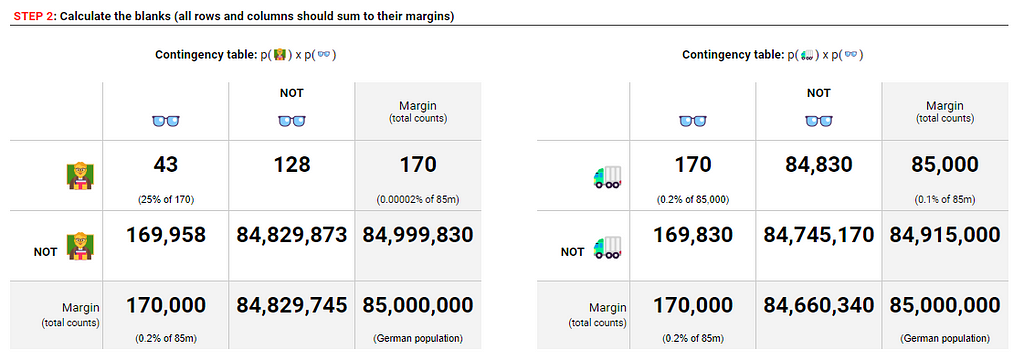
And now, with our contingency tables complete, we have a full picture of our estimates around base rates and the likelihoods of the profiles matching the descriptions. All the conditional and marginal probabilities from the Bayes formula are now represented here and can be calculated as follows:

Back to the original question, the probability we are interested in is the third in the list above: the probability that they are a professor/truck driver given the description.
And, based on our parameter estimates, we see that truck drivers are x4 more likely to fit the bill than our professors (0.001 / 0.00025). This is in contrast to the reverse conditional where the description is more likely to fit the professor than a truck driver by a factor of x125 (0.25 / 0.002)!
Back to Malmsey
Now, looping back around to where we started with the malmsey example, hopefully the intuition is bedding in and the role of the base rates in making a guess is clear.
In terms of mapping the thinking to the Bayes formula, essentially, the thinking process would be to compare our degrees of belief of the following three scenarios:
- Probability (A the answer is mild hangover | B the word is malmsey)
- Probability (A the answer is witch’s curse | B the word is malmsey)
- Probability (A the answer is fortified wine | B the word is malmsey)
Because in this case we have no inkling as to what malmsey could correspond to (this would be different if we had some etymological suspicions for example), we could say that B is uninformative and so to make any sort of reasoned guess, all we have to go by are the probabilities of A. In terms of the Bayes formula, we can see that the probability we are interested in scales with the base rate of A:

For completeness, here is what it might look like to tabulate our degrees of belief in the style of the contingency tables from the Dobelli example. Because B is uninformative, we give 50:50 odds for the word malmsey matching any other word or concept. This is overkill and hardly necessary once we recognise that we can simply scale our belief in the answer with the base rates, but it’s there to show the Bayesian framework still fits together for this more abstract problem.
Base rate neglect in Hypothesis (A/B) Testing
I previously wrote on the topic of the prosecutor’s fallacy (a form of base rate neglect) which gives other examples on base rate neglect and implications for analytics practitioners.
It is worth making the connection again here that in conventional A/B testing methods, people often confuse the probability they get of seeing the test results with the probability of the hypothesis itself being true. Much has been written about p-values and their pitfalls (see, for example, A Dirty Dozen: Twelve P-Value Misconceptions), but this is another place where the Bayesian mindset helps to clarify our reasoning and where it helps to be alert to the concept of base rate neglect, which in this case is our confidence in the hypothesis being true in the first place (our priors).
I encourage you to read the article to get a better intuition for this.
Takeaways
- Concepts covered: base rate neglect, conditional vs marginal probabilities, Bayes’ formula, contingency tables.
- Be careful not to equate p(A|B) with p(B|A) in day-to-day judgement of likelihoods.
- Consider base rates when making a judgement of whether a new observation validates your hypothesis.
- TIL: Malmsey is a fortified wine from the island of Madeira. In Shakespeare’s Richard III, George Plantagenet the Duke of Clarence drowns in a vat of malmsey.
Further reading
- The Art of Thinking Clearly by Rolf Dobelli where this article takes the professor-truck driver puzzle from provides a great, readable collection of thinking traps in day-to-day life. Alongside the chapter on base rate neglect (ch 28), I enjoyed the framings used for regression to the mean (ch 19), exponential growth (ch 34), false causality (ch 37) and many more. Each chapter is succinct at 2–3 pages and the book works well as an ongoing reference manual for common biases and fallacies.
- The Undoing Project by Michael Lewis (author of The Big Short) is the story of Kahneman, Tversky and the development of behavioural economics. It has all the best bits from Thinking Fast and Slow and is a page turner that could easily become a movie adaptation.
- The Art of Statistics by David Spiegelhalter has great, layman-friendly chapters on Bayesian statistics.
- How to Intuit the Prosecutor’s Fallacy (and run better hypothesis tests) is a previous article I wrote on a similar topic when I was grappling with the proper definition of p values.
- For getting an intuition for the Bayes formula, I recommend watching the Stat Quest videos on 1. Conditional Probability and 2. Bayes’ Theorem.
How to Tackle the Weekend Quiz Like a Bayesian was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.










