
Generative models, such as Generative Adversarial Networks (GANs), have the capacity to generate lifelike images of objects and dressed individuals after being trained on an extensive image collection. Although the resulting output is a 2D image, numerous applications necessitate diverse and high-quality virtual 3D avatars. These avatars should allow pose and camera viewpoint control while ensuring 3D consistency. To address the demand for 3D avatars, the research community explores generative models capable of automatically generating 3D shapes of humans and clothing based on input parameters like body pose and shape. Despite considerable advancements, most existing methods overlook texture and rely on precise and clean 3D scans of humans for training. Acquiring such scans is expensive, limiting their availability and diversity.
Developing a method for learning the generation of 3D human shapes and textures from unstructured image data presents a challenging and under-constrained problem. Each training instance exhibits unique shapes and appearances, observed only once from specific viewpoints and poses. While recent progress in 3D-aware GANs has shown impressive results for rigid objects, these methods face difficulties in generating realistic humans due to the complexity of human articulation. Although some recent work demonstrates the feasibility of learning articulated humans, existing approaches struggle with limited quality, resolution, and challenges in modeling loose clothing.
The paper reported in this article introduces a novel method for 3D human generation from 2D image collections, achieving state-of-the-art image and geometry quality while effectively modeling loose clothing.
The overview of the proposed method is illustrated below.
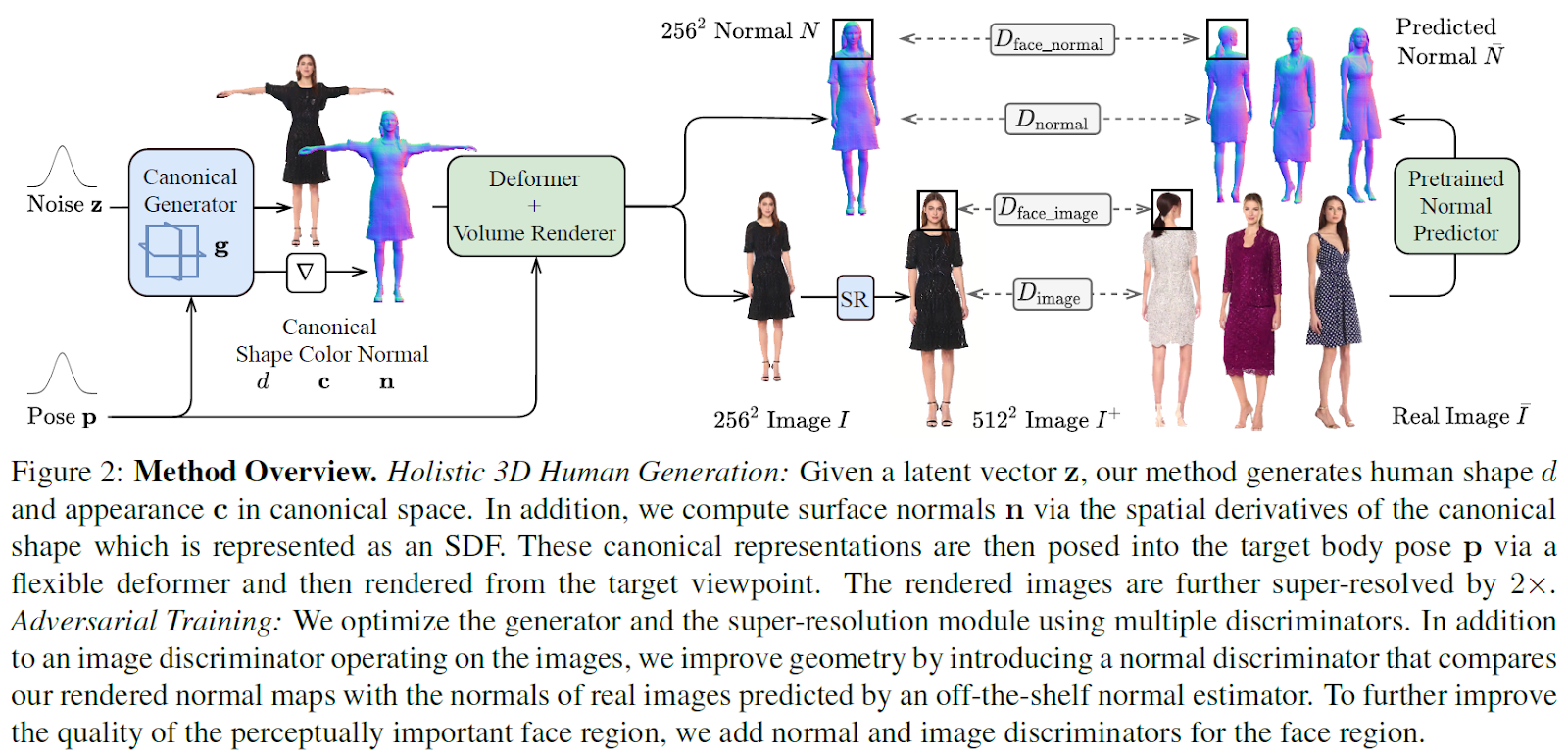
This method adopts a monolithic design capable of modeling both the human body and loose clothing, departing from the approach of representing humans with separate body parts. Multiple discriminators are incorporated to enhance geometric detail and focus on perceptually important regions.
A novel generator design is proposed to address the goal of high image quality and flexible handling of loose clothing, modeling 3D humans holistically in a canonical space. The articulation module, Fast-SNARF, is responsible for the movement and positioning of body parts and adapted to the generative setting. Additionally, the model adopts empty-space skipping, optimizing and accelerating the rendering of areas with no significant content to improve overall efficiency.
The modular 2D discriminators are guided by normal information, meaning they consider the directionality of surfaces in the 3D space. This guidance helps the model focus on regions that are perceptually important for human observers, contributing to a more accurate and visually pleasing outcome. Furthermore, the discriminators prioritize geometric details, enhancing the overall quality of the generated images. This improvement likely contributes to a more realistic and visually appealing representation of the 3D human models.

The experimental results reported above demonstrate a significant improvement of the proposed method over previous 3D- and articulation-aware methods in terms of geometry and texture quality, validated quantitatively, qualitatively, and through perceptual studies.
In summary, this contribution includes a generative model of articulated 3D humans with state-of-the-art appearance and geometry, an efficient generator for loose clothing, and specialized discriminators enhancing visual and geometric fidelity. The authors plan to release the code and models for further exploration.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.

