The task of view synthesis is essential in both computer vision and graphics, enabling the re-rendering of scenes from various viewpoints akin to the human eye. This capability is vital for everyday tasks and fosters creativity by allowing the envisioning and crafting of immersive objects with depth and perspective. Researchers at Dyson Robotics Lab aim to address the challenge of scalable view synthesis by considering two key observations.
While recent advancements have focused on training speed and rendering efficiency, they rely heavily on volumetric rendering and scene-specific encoding. They propose a shift towards learning general 3D representations based solely on scene colors and geometries without requiring ground-truth 3D geometry or specific coordinate systems. This approach enables scalability by overcoming constraints imposed by scene-specific encoding.
Secondly, view synthesis can be framed as a conditional generative modeling problem, akin to generative image in-painting, where the model should provide multiple plausible predictions based on sparse reference views. They argue for a more flexible generative formulation that accommodates varying levels of input information, gradually converging towards ground-truth representations as more data becomes available.
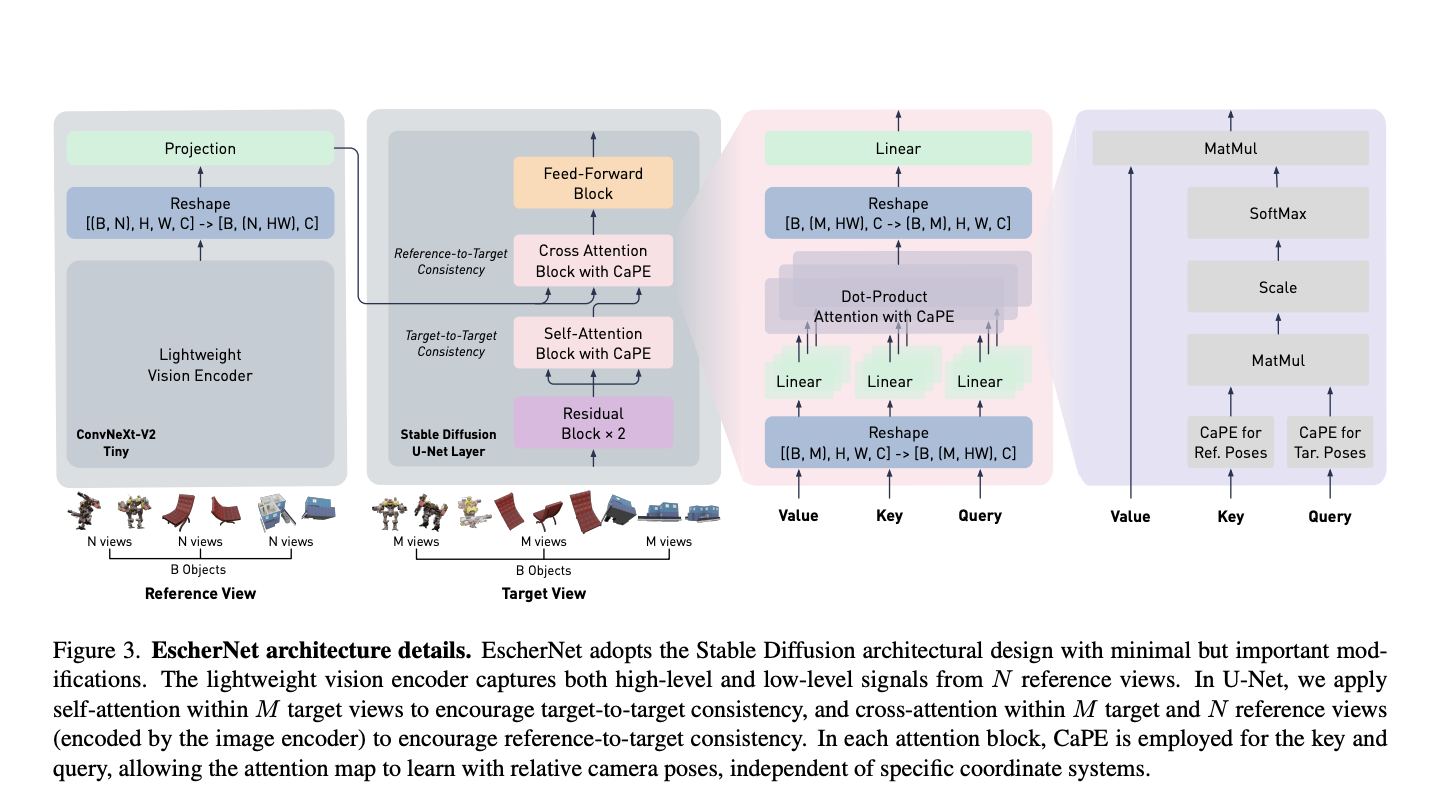
Building upon these insights, they introduce EscherNet, an image-to-image conditional diffusion model for view synthesis. EscherNet utilizes a transformer architecture with dot-product self-attention to capture relationships between reference-to-target and target-to-target views. A key innovation is the Camera Positional Encoding (CaPE), representing both 4 Degrees of Freedom (DoF) and 6 DoF camera poses, enabling self-attention computation based on relative camera transformations.
EscherNet showcases remarkable characteristics that distinguish it in the field of view synthesis. Firstly, it achieves a high level of consistency by integrating view consistency through its Camera Positional Encoding (CaPE), which fosters coherence between reference and target views. Secondly, EscherNet demonstrates excellent scalability by detaching itself from specific coordinate systems and circumventing costly 3D operations, making it adaptable to everyday 2D image data.
Lastly, its impressive generalization capabilities allow it to generate target views based on varying numbers of reference views, improving quality as more references are provided. These qualities collectively position EscherNet as a promising advancement in view synthesis and 3D vision research.
Comprehensive evaluations across view synthesis and 3D reconstruction benchmarks demonstrate EscherNet’s superior generation quality compared to existing models, particularly under limited view constraints. This underscores the effectiveness of their approach in advancing view synthesis and 3D vision.
Check out the Paper, Github, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.

