
View synthesis, integral to computer vision and graphics, enables scene re-rendering from diverse perspectives akin to human vision. It aids in tasks like object manipulation and navigation while fostering creativity. Early neural 3D representation learning primarily optimized 3D data directly, aiming to enhance view synthesis capabilities for broader applications in these fields. However, all these existing methods heavily rely on ground-truth 3D geometry, limiting their applicability to small-scale synthetic 3D data.
Early works in neural 3D representation learning focused on optimizing 3D data directly, using voxels and point clouds for explicit representation learning. Alternatively, methods mapped 3D spatial coordinates to signed distance functions or occupancies for implicit representation learning. However, these heavily relied on ground-truth 3D geometry, limiting applicability. Differentiable rendering functions improved scalability with multi-view posed images. Direct training on 3D datasets using point clouds or neural fields improved efficiency but encountered computational challenges.
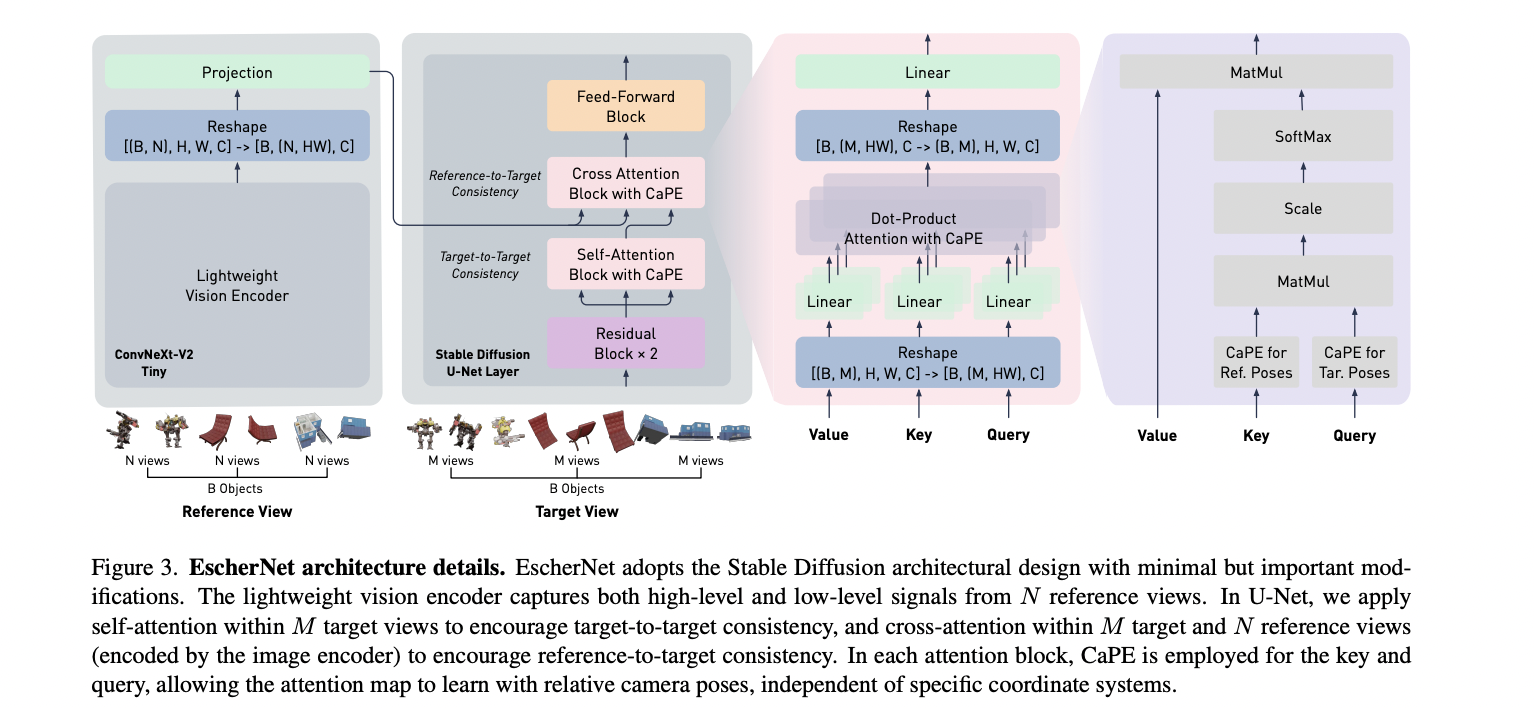
Researchers from Dyson Robotics Lab, Imperial College London, and The University of Hong Kong present EscherNet, a multi-view conditioned diffusion model that controls precise camera transformation between reference and target views. It learns implicit 3D representations with specialized camera positional encoding, offering exceptional generality and scalability in view synthesis. Despite training with a fixed number of reference views, EscherNet can generate over 100 consistent target views on a single GPU. It unifies single- and multi-image 3D reconstruction tasks.

EscherNet integrates a 2D diffusion model and camera positional encoding to handle arbitrary numbers of views for view synthesis. It utilizes Stable Diffusion v1.5 as a backbone, modifying self-attention blocks to ensure target-to-target consistency across multiple views. By incorporating Camera Positional Encoding (CaPE), EscherNet accurately encodes camera poses for each view, facilitating relative camera transformation learning. It achieves high-quality results by efficiently encoding high-level semantics and low-level texture details from reference views.
EscherNet demonstrates superior performance across various tasks in 3D vision. In novel view synthesis, it outperforms 3D diffusion models and neural rendering methods, achieving high-quality results with fewer reference views. Additionally, EscherNet excels in 3D generation, surpassing state-of-the-art models in reconstructing accurate and visually appealing 3D geometry. Its flexibility enables seamless integration into text-to-3D generation pipelines, producing consistent and realistic results from textual prompts.
To sum up, the researchers from Dyson Robotics Lab, Imperial College London, and The University of Hong Kong introduce EscherNet, a multi-view conditioned diffusion model for scalable view synthesis. By leveraging Stable Diffusion’s 2D architecture and innovative CaPE, EscherNet effectively learns implicit 3D representations from various reference views, enabling consistent 3D novel view synthesis. This approach demonstrates promising results for addressing challenges in view synthesis and offers potential for further advancements in scalable neural architectures for 3D vision.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.

