
The emergence of Multimodality Large Language Models (MLLMs), such as GPT-4 and Gemini, has sparked significant interest in combining language understanding with various modalities like vision. This fusion offers potential for diverse applications, from embodied intelligence to GUI agents. Despite the rapid development of open-source MLLMs like BLIP and LLaMA-Adapter, their performance could be improved by more training data and model parameters. While some excel in natural image understanding, they need help with tasks requiring specialized knowledge. Moreover, the current model sizes may not be suitable for mobile deployment, necessitating the exploration of smaller and more parameter-rich architectures for broader adoption and improved performance.
Researchers from Shanghai AI Laboratory, MMLab, CUHK, Rutgers University, and the University of California, Los Angeles, have developed SPHINX-X, an advanced MLLM series built upon the SPHINX framework. Enhancements include streamlining architecture by removing redundant visual encoders, optimizing training efficiency with skip tokens for fully padded sub-images, and transitioning to a one-stage training paradigm. SPHINX-X leverages a diverse multimodal dataset, augmented with curated OCR and Set-of-Mark data, and is trained across various base LLMs, offering a range of parameter sizes and multilingual capabilities. Benchmarked results underscore SPHINX-X’s superior generalization across tasks, addressing previous MLLM limitations while optimizing for efficient, large-scale multimodal training.

Recent advancements in LLMs have leveraged Transformer architectures, notably exemplified by GPT-3’s 175B parameters. Other models like PaLM, OPT, BLOOM, and LLaMA have followed suit, with innovations like Mistral’s window attention and Mixtral’s sparse MoE layers. Concurrently, bilingual LLMs like Qwen and Baichuan have emerged, while TinyLlama and Phi-2 focus on parameter reduction for edge deployment. Meanwhile, MLLMs integrate non-text encoders for visual understanding, with models like BLIP, Flamingo, and LLaMA-Adapter series pushing the boundaries of vision-language fusion. Fine-grained MLLMs like Shikra and VisionLLM excel in specific tasks, while others extend LLMs to diverse modalities.
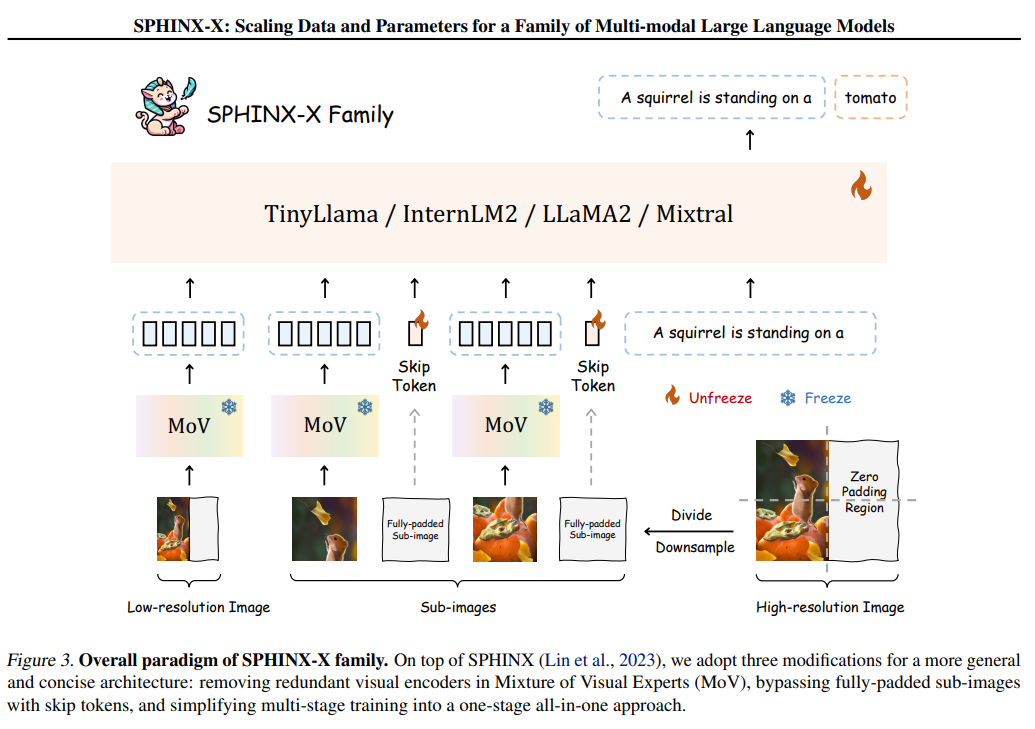
The study revisits the design principles of SPHINX. It proposes three improvements to SPHINX-X, including the brevity of visual encoders, learnable skip tokens for useless optical signals, and simplified one-stage training. The researchers assemble a large-scale multi-modality dataset covering language, vision, and vision-language tasks and enrich it with curated OCR intensive and Set-of-Mark datasets. The SPHINX-X family of MLLMs is trained over different base LLMs, including TinyLlama-1.1B, InternLM2-7B, LLaMA2-13B, and Mixtral-8×7B, to obtain a spectrum of MLLMs with varying parameter sizes and multilingual capabilities.
The SPHINX-X MLLMs demonstrate state-of-the-art performance across various multi-modal tasks, including mathematical reasoning, complex scene understanding, low-level vision tasks, visual quality assessment, and resilience when facing illusions. Comprehensive benchmarking reveals a strong correlation between the multi-modal performance of the MLLMs and the scales of data and parameters used in training. The study presents the performance of SPHINX-X on curated benchmarks such as HallusionBench, AesBench, ScreenSpot, and MMVP, showcasing its capabilities in language hallucination, visual illusion, aesthetic perception, GUI element localization, and visual understanding.
In conclusion, SPHINX-X significantly advances MLLMs, building upon the SPHINX framework. Through enhancements in architecture, training efficiency, and dataset enrichment, SPHINX-X exhibits superior performance and generalization compared to the original model. Scaling up parameters further amplifies its multi-modal understanding capabilities. The release of code and models on GitHub fosters replication and further research. With improvements including streamlined architecture and a comprehensive dataset, SPHINX-X offers a robust platform for multi-purpose, multi-modal instruction tuning across a range of parameter scales, shedding light on future MLLM research endeavors.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.

