
Integrating multimodal data such as text, images, audio, and video is a burgeoning field in AI, propelling advancements far beyond traditional single-mode models. Traditional AI has thrived in unimodal contexts, yet the complexity of real-world data often intertwines these modes, presenting a substantial challenge. This complexity demands a model capable of processing and seamlessly integrating multiple data types for a more holistic understanding.
Addressing this, the recent “Unified-IO 2” development by researchers from the Allen Institute for AI, the University of Illinois Urbana-Champaign, and the University of Washington signifies a monumental leap in AI capabilities. Unlike its predecessors, which were limited in handling dual modalities, Unified-IO 2 is an autoregressive multimodal model capable of interpreting and generating a wide array of data types, including text, images, audio, and video. It is the first of its kind, trained from scratch on a diverse range of multimodal data. Its architecture is built upon a single encoder-decoder transformer model, uniquely designed to convert varied inputs into a unified semantic space. This innovative approach enables the model to process different data types in tandem, overcoming the limitations of previous models.
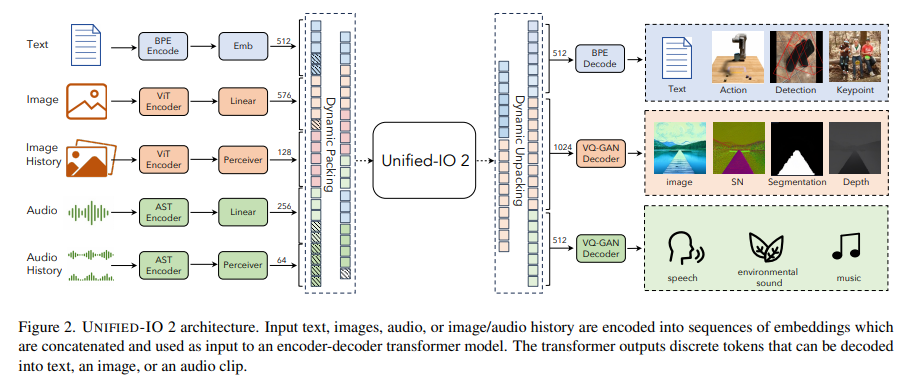
The methodology behind Unified-IO 2 is as intricate as it is groundbreaking. It employs a shared representation space for encoding various inputs and outputs – a feat achieved by using byte-pair encoding for text and special tokens for encoding sparse structures like bounding boxes and key points. Images are encoded with a pre-trained Vision Transformer, and a linear layer transforms these features into embeddings suitable for the transformer input. Audio data follows a similar path, processed into spectrograms and encoded using an Audio Spectrogram Transformer. The model also includes dynamic packing and a multimodal mixture of denoisers’ objectives, enhancing its efficiency and effectiveness in handling multimodal signals.
Unified-IO 2’s performance is as impressive as its design. Evaluated across over 35 datasets, it sets a new benchmark in the GRIT evaluation, excelling in tasks like keypoint estimation and surface normal estimation. It matches or outperforms many recently proposed Vision-Language Models in vision and language tasks. Particularly notable is its capability in image generation, where it outperforms its closest competitors in terms of faithfulness to prompts. The model also effectively generates audio from images or text, showcasing versatility despite its broad capability range.
The conclusion drawn from Unified-IO 2’s development and application is profound. It represents a significant advancement in AI’s ability to process and integrate multimodal data and opens up new possibilities for AI applications. Its success in understanding and generating multimodal outputs highlights the potential of AI to interpret complex, real-world scenarios more effectively. This development marks a pivotal moment in AI, paving the way for more nuanced and comprehensive models in the future.

In essence, Unified-IO 2 serves as a beacon of the potential inherent in AI, symbolizing a shift towards more integrative, versatile, and capable systems. Its success in navigating the complexities of multimodal data integration sets a precedent for future AI models, pointing towards a future where AI can more accurately reflect and interact with the multifaceted nature of human experience.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.

