
LLMs, pretrained on extensive textual data, exhibit impressive capabilities in generative and discriminative tasks. Recent interest focuses on employing LLMs for multimodal tasks, integrating them with visual encoders for tasks like captioning, question answering, classification, and segmentation. However, prior multimodal models face limitations in handling video inputs due to the context length restriction of LLMs and GPU memory constraints. For instance, while models like LLaMA have a context limit of 2048, others like LLaVA and BLIP-2 process only 256 and 32 tokens per image, respectively. This restricts their practicality for longer video durations such as movies or TV shows.
A simple solution like average pooling along the temporal axis, as used in VideoChatGPT, leads to inferior performance due to the absence of explicit temporal modeling. Another approach, as seen in Video-LLaMA, involves adding a video modeling component, such as an extra video querying transformer (Q-Former), to capture temporal dynamics and obtain video-level representation. However, this method increases model complexity, adds training parameters, and is unsuitable for online video analysis.
Researchers from the University of Maryland, Meta, and Central Florida propose a Memory-Augmented Large Multimodal Model (MA-LMM) for efficient long-term video modeling. It follows the structure of existing multimodal models, featuring a visual encoder, a querying transformer, and a large language model. Unlike previous methods, MA-LMM adopts an online processing approach, sequentially processing video frames and storing features in a long-term memory bank. This strategy significantly reduces GPU memory usage for long video sequences and effectively addresses context length limitations in LLMs. MA-LMM offers advantages over prior approaches, which consume substantial GPU memory and input text tokens.
The MA-LLM model architecture comprises three main components: (1) visual feature extraction using a frozen visual encoder, (2) long-term temporal modeling employing a trainable querying transformer (Q-Former) to align visual and text embeddings, and (3) text decoding with a frozen large language model. Frames are processed sequentially, associating new inputs with historical data in a long-term memory bank to retain discriminative information efficiently. The querying transformer integrates visual and textual information, while a compression technique reduces memory bank size without losing discriminative features. Finally, the model decodes text using the Q-Former output, addressing context length limitations and reducing GPU memory requirements during training.
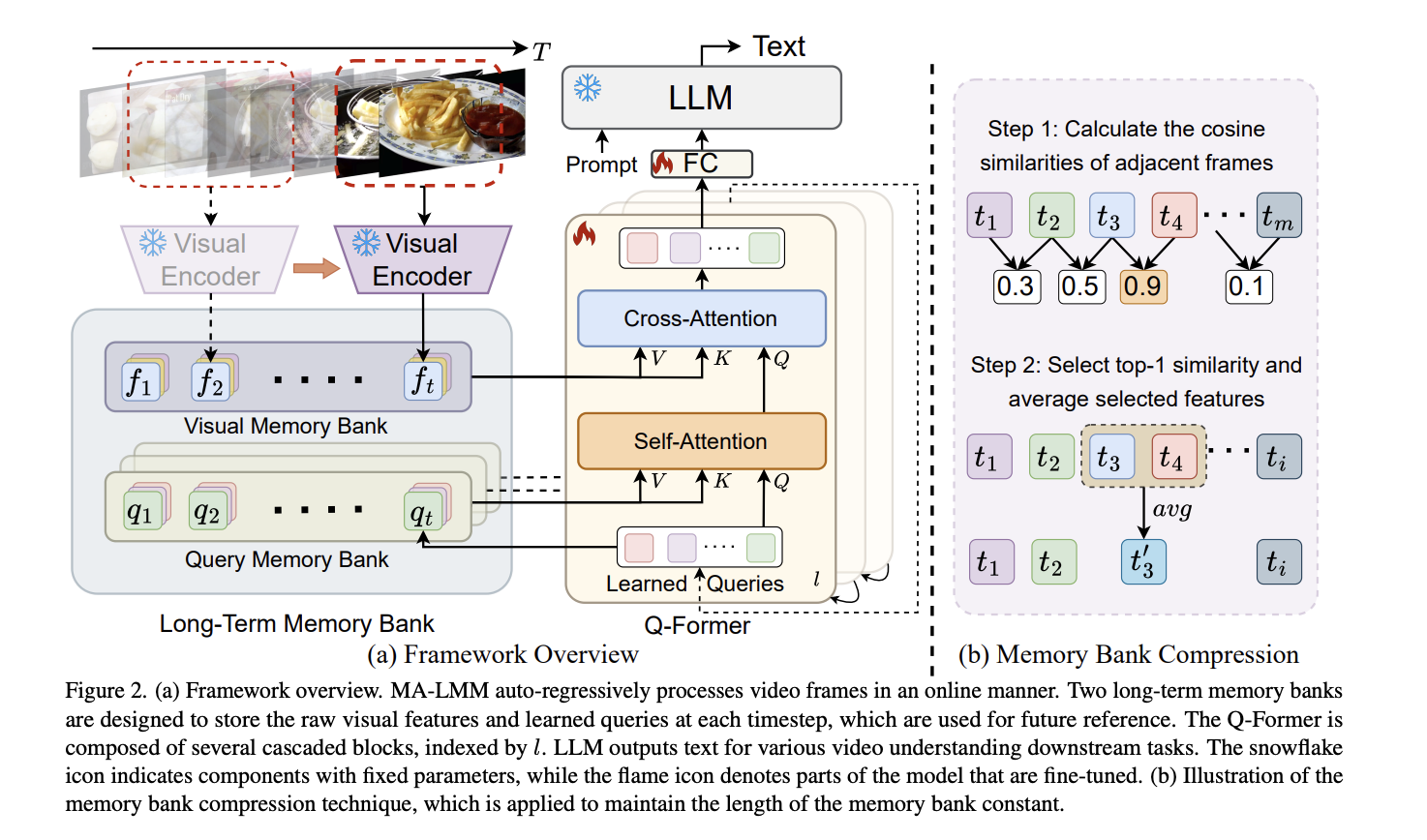
MA-LMM demonstrates superior performance across various tasks compared to previous state-of-the-art methods. It outperforms existing models in long-term video understanding, video question answering, video captioning, and online action prediction tasks. MA-LMM’s innovative design, utilizing a long-term memory bank and sequential processing, enables efficient handling of long video sequences and achieves remarkable results even in challenging scenarios. These findings prove the effectiveness and versatility of MA-LMM in multimodal video understanding applications.
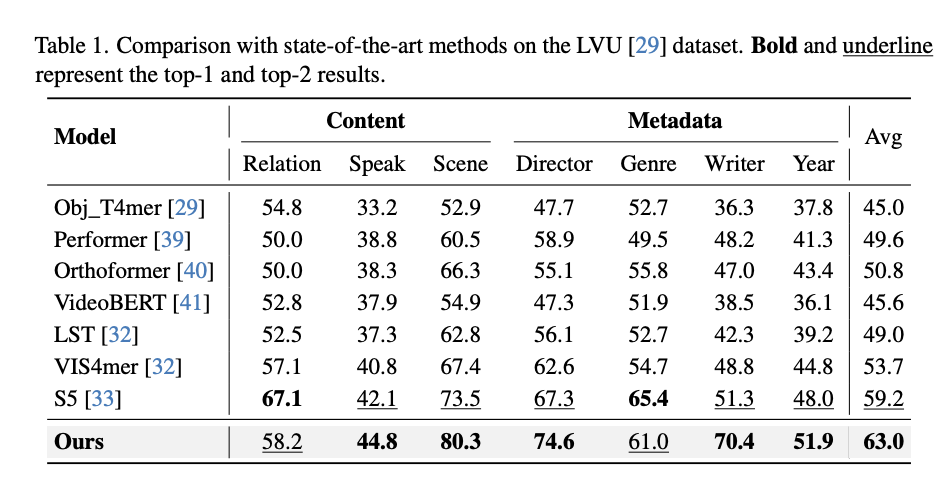
To conclude, this research introduces a long-term memory bank to enhance existing large multimodal models, MA-LLM, for effectively modeling long video sequences. This approach addresses context length limitations and GPU memory constraints inherent in LLMs by processing video frames sequentially and storing historical data. As demonstrated in experiments, the long-term memory bank is easily integrated into existing models and shows superior advantages across various tasks.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.

