
In Multi-modal learning, large image-text foundation models have demonstrated outstanding zero-shot performance and improved stability across a wide range of downstream tasks. Models such as Contrastive Language-Image Pretraining (CLIP) show a significant improvement in Multi-modal AI because of its ability to analyze both images and text simultaneously. Recently, a wide range of architectures have proved their ability and performance in achieving vision tasks on resource constraint devices, e.g., pruning ViT architectures helps obtain smaller and faster CLIP models.
However, models like CLIP utilize large transformer-based encoders with significant memory and latency overhead, which pose challenges for deployment on mobile devices. Also, there are two problems that this paper addresses, first one is the trade-off between runtime performance and the accuracy of different architectures, which slows down the analysis of architectural designs. Further, large-scale training of CLIP models is expensive and disturbs the rapid growth and exploration of DataCompDR-12M and DataCompDR-1B. The second problem highlights the reduced capacity of smaller architectures, which leads to subpar accuracy.
Researchers from Apple introduced MobileCLIP, a new family of image-text models optimized for runtime performance through an efficient training approach, namely multi-modal reinforced training. MobileCLIP sets a new state-of-the-art system to balance speed and accuracy and retrieve tasks across multiple datasets. Moreover, the training approach utilizes knowledge transfer from an image captioning model and a collection of robust CLIP encoders to enhance the accuracy of efficient models. Additional knowledge is stored in a reinforced dataset to avoid the train-time compute overhead for this training method.
The proposed multi-modal reinforced training approach is combined with DataCompDR to solve the challenges addressed in this paper. Its accuracy is higher than the original dataset for a given compute budget. This is achieved by storing synthetic captions and teacher embeddings in the dataset, followed by a dataset reinforcement strategy, which helps to avoid extra training time. Its main components are (a) leveraging the knowledge of an image captioning model via synthetic captions and (b) knowledge distillation of image-text alignments from a collection of robust pre-trained CLIP models.
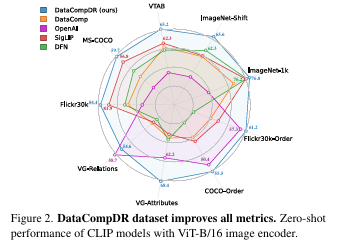
Three small variants of MobileCLIP are created with a base of 12-layer transformer, and the fastest variant, MobileCLIP-S0, is five times faster and three times smaller than the standard ViT-B/16 CLIP model. Further, multi-modal reinforced training achieves +2.9% average performance growth on 38 evaluation benchmarks by training the ViT-B/16 image backbone. Also, to avoid noisy datasets, DataComp and data filtering networks are used to enhance the quality of web-sourced datasets, and the CoCa model is used to boost the visual descriptiveness of the captions and generate multiple synthetic captions for each image.
In conclusion, the proposed model, MobileCLIP, is a new family of efficient image-text models optimized for runtime performance through an efficient training approach, i.e., multi-modal reinforced training. Researchers also introduced DataCompDR, a reinforced training dataset with knowledge from a pre-trained image captioning model and a collection of robust CLIP models. MobileCLIP models trained on DataCompDR set a new state-of-the-art to balance speed and accuracy and retrieve tasks across multiple datasets.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.

