Basic information about gene and cell function is revealed by the expression response of a cell to a genetic disturbance. Using a readout of the expression response to a perturbation using single-cell RNA seq (scRNA-seq), perturb-seq is a new method for pooled genetic screens. Perturb-seq allows for the engineering of cells to a certain state, sheds light on the gene regulation system, and aids in identifying target genes for therapeutic intervention.
The efficiency, scalability, and breadth of Perturb-Seq have all been augmented by recent technological developments. The number of tests needed to evaluate various perturbations multiplies exponentially due to the wide variety of biological contexts, cell types, states, and stimuli. This is because non-additive genetic interactions are a possibility. Executing all of the experiments directly becomes impractical when there are billions of possible configurations.
According to recent research, the results of perturbations can be predicted using machine learning models. They use pre-existing Perturb-seq datasets to train their algorithms, forecasting the expression results of unseen perturbations, individual genes, or combinations of genes. Although these models show promise, they are flawed due to a selection bias introduced by the original experiment’s design, which affected the biological circumstances and perturbations chosen for training.
Genentech and Stanford University researchers introduce a new way of thinking about running a series of perturb-seq experiments to investigate a perturbation space. In this paradigm, the Perturb-seq assay is carried out in a wet-lab environment, and the machine learning model is implemented using an interleaving sequential optimal design approach. Data acquisition and re-training of the machine learning model occurs at each process stage. To ensure that the model can accurately forecast unprofiled perturbations, the researchers next use an optimal design technique to choose a set of perturbation experiments. To intelligently sample the perturbation space, one must consider the most informative and representative perturbations to the model while allowing for diversity. This approach allows the creation of a model that has adequately explored the perturbation space with minimal perturbation experiments done.
Active learning is based on this principle, which has been extensively researched in machine learning. Document classification, medical imaging, and speech recognition are examples of the many areas that have put active learning into practice. The findings demonstrate that active learning methods that work require a large initial set of labeled examples—profiled perturbations in this case—along with several batches that add up to tens of thousands of labeled data points. The team also performed an economic analysis that shows such conditions are not feasible due to the time and money constraints of iterative Perturb-seq in the lab.
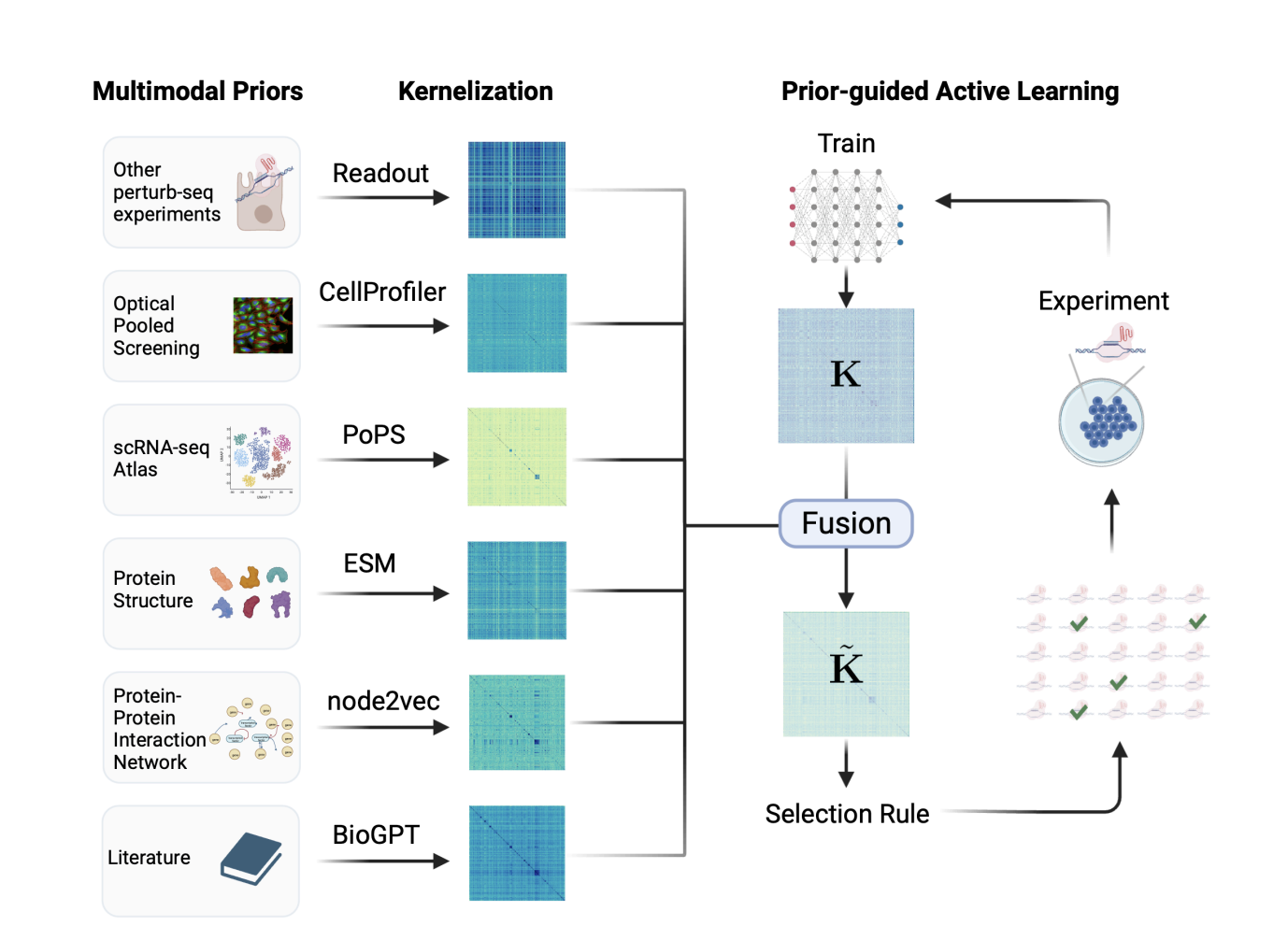
To address the issue of active learning in a budget context for Perturb-seq data, the team provides a novel approach termed ITERPERT (ITERative PERTurb-seq). Inspired by data-driven research, this work’s main takeaway is that it might be useful to supplement data evidence with publically available prior knowledge sources, particularly in the early stages and when funds are tight. Data on physical molecular interactions, such as protein complexes, Perturb-seq information from comparable systems, and large-scale genetic screens using other modalities, such as genome-scale optical pooling screens, are examples of such prior knowledge. The prior knowledge encompasses several forms of representation, including networks, text, images, and three-dimensional structures, which could be difficult to utilize when engaging in active learning. To get around this, the team defines replicating kernel Hilbert spaces on all modalities and uses a kernel fusion approach to merge data from different sources.
They performed an intensive empirical investigation using a large-scale single-gene CRISPRi Perturb-seq dataset obtained in a cancer cell line (K562 cells). They benchmarked eight recent active learning methodologies to compare ITERPERT to other regularly used approaches. ITERPERT obtained accuracy levels comparable to the top active learning technique while using training data containing three times fewer perturbations. When considering batch effects throughout iterations, ITERPERT demonstrated strong performance in critical gene and genome-scale screens.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.

