
Image Quality Assessment (IQA) is a method that standardizes the evaluation criteria for analyzing different aspects of images, including structural information, visual content, etc. To improve this method, various subjective studies have adopted comparative settings. In recent studies, researchers have explored large multimodal models (LMMs) to expand IQA from giving a scalar score to open-ended scenarios that allow evaluations to respond to open-range questions and provide detailed reasoning beyond an overall score.
LMMs can capture a more nuanced, comprehensive understanding of the input data, resulting in better performance and accurate predictions across various tasks. Adding modalities to LLMs creates LMMs. Some examples of LMMs are ChatGPT and Gemini. However, it lacks ambiguity in absolute evaluations.
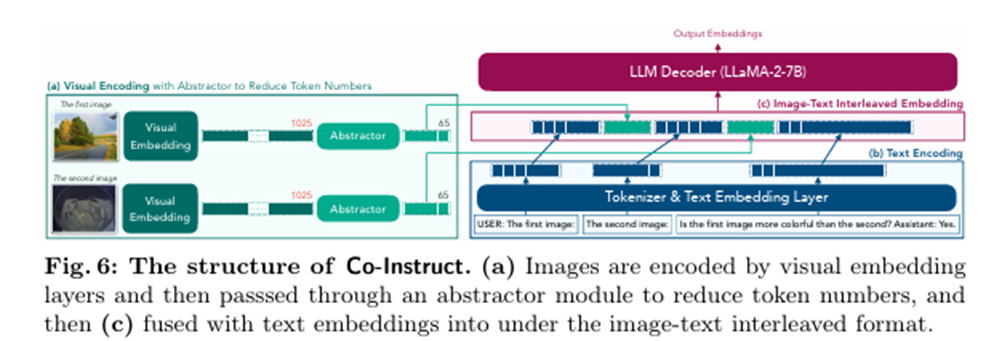
Researchers from Nanyang Technological University, City University of Hong Kong, Shanghai Jiao Tong University, and SenseTime Research proposed Co-Instruct. Q-Instruct-200K, Merge2Compare, and Teach2Compare are integrated to construct Co-Instruct. This is the first instruction tuning dataset designed for open-ended multi-image quality comparison. Also, five open-source LMMs that support multi-image inputs are chosen as baseline models. These models are LLaVA-v1.5-13B, InternLM-XComposer2, BakLLaVA, EMU2-Chat, and mPLUG-Owl2. There is a comparison with three well-recognized close-source models: Qwen-VL-Max, Gemini-Pro, and GPT-4V.
Open-source LMMs are usually only fine-tuned with single-image instruction tuning datasets and have been proven to lack enough capability even on two-image comparison settings. While these gaps have indicated the need for a specific instruction-tuning dataset for visual quality comparison, it is too expensive to collect such a dataset from humans. To solve this problem, Co-instruct has been constructed with up to 86% improvements to its baseline and 61% better than the open-source LMM. Even though it learned from GPT-4V alongside other sources, the model outperforms the GPT-4V teacher in numerous multiple-choice question benchmarks. It demonstrates comparable proficiency to GPT-4V in tasks demanding detailed language reasoning.
Co-Instruct achieves 30% higher accuracy than open-source LMMs and outperforms GPT-4V on existing related benchmarks and the proposed MICBench. Two non-perfect supervisors used under Co-Instruct are Merge2Compare: They originated from single-image human quality descriptions of 19K images in Q-Pathway and were randomly matched into 100K groups. Then, a single-modal LLM is prompted to compare multiple human descriptions in a group and merge them into a 100K pseudo comparison, similar to the construction of LLaVA-150K. Teach2Compare: Observing that GPT-4V has especially high accuracy on pairwise settings among existing LMMs, we need to leverage GPT-4V responses to expand our dataset further. For this, 9K unlabeled images are collected and randomly matched into 30K image groups, and GPT-4V responses are obtained on both caption-like general comparisons and question-answer pairs for comparisons.
In conclusion, the research aimed to develop a model that provides answers and detailed reasonings on open-range questions that compare quality among multiple images. Co-Instruct has achieved this by fine-tuning LMMs and outperforming all existing LMMs on the visual quality comparison. Also, the construction of MICBench helps evaluate multi-image quality comparison for LMMs on three and four images.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.

