
Image by Author
In this post, we will explore the new state-of-the-art open-source model called Mixtral 8x7b. We will also learn how to access it using the LLaMA C++ library and how to run large language models on reduced computing and memory.
Mixtral 8x7b is a high-quality sparse mixture of experts (SMoE) model with open weights, created by Mistral AI. It is licensed under Apache 2.0 and outperforms Llama 2 70B on most benchmarks while having 6x faster inference. Mixtral matches or beats GPT3.5 on most standard benchmarks and is the best open-weight model regarding cost/performance.
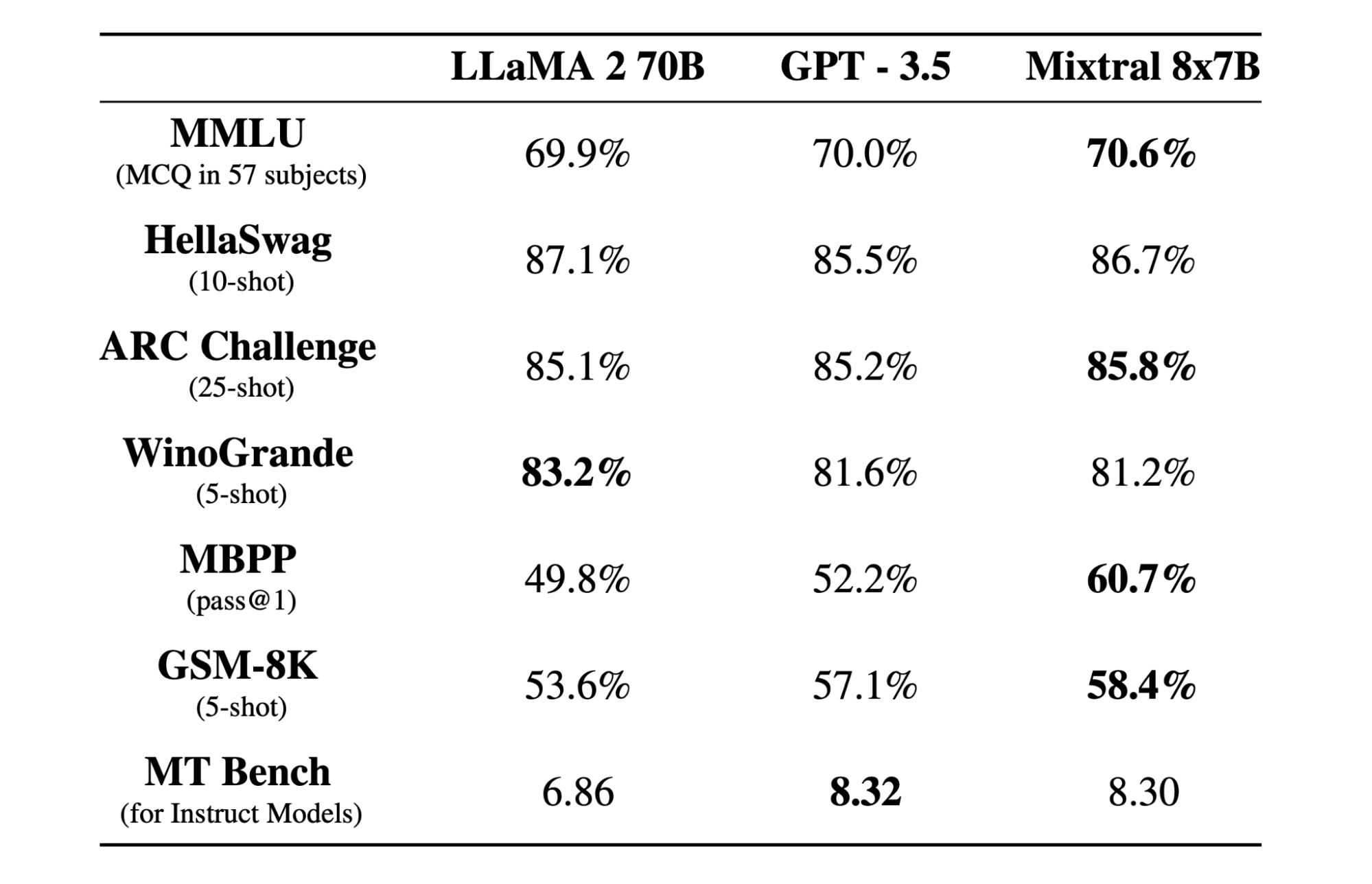
Image from Mixtral of experts
Mixtral 8x7B uses a decoder-only sparse mixture-of-experts network. This involves a feedforward block selecting from 8 groups of parameters, with a router network choosing two of these groups for each token, combining their outputs additively. This method enhances the model’s parameter count while managing cost and latency, making it as efficient as a 12.9B model, despite having 46.7B total parameters.
Mixtral 8x7B model excels in handling a wide context of 32k tokens and supports multiple languages, including English, French, Italian, German, and Spanish. It demonstrates strong performance in code generation and can be fine-tuned into an instruction-following model, achieving high scores on benchmarks like MT-Bench.
LLaMA.cpp is a C/C++ library that provides a high-performance interface for large language models (LLMs) based on Facebook’s LLM architecture. It is a lightweight and efficient library that can be used for a variety of tasks, including text generation, translation, and question answering. LLaMA.cpp supports a wide range of LLMs, including LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B, and GPT4ALL. It is compatible with all operating systems and can function on both CPUs and GPUs.
In this section, we will be running the llama.cpp web application on Colab. By writing a few lines of code, you will be able to experience the new state-of-the-art model performance on your PC or on Google Colab.
Getting Started
First, we will download the llama.cpp GitHub repository using the command line below:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.git
After that, we will change directory into the repository and install the llama.cpp using the `make` command. We are installing the llama.cpp for the NVidia GPU with CUDA installed.
%cd llama.cpp
!make LLAMA_CUBLAS=1
Download the Model
We can download the model from the Hugging Face Hub by selecting the appropriate version of the `.gguf` model file. More information on various versions can be found in TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
Image from TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
You can use the command `wget` to download the model in the current directory.
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.gguf
External Address for LLaMA Server
When we run the LLaMA server it will give us a localhost IP which is useless for us on Colab. We need the connection to the localhost proxy by using the Colab kernel proxy port.
After running the code below, you will get the global hyperlink. We will use this link to access our webapp later.
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/
Running the Server
To run the LLaMA C++ server, you need to provide the server command with the location of the model file and the correct port number. It’s important to make sure that the port number matches the one we initiated in the previous step for the proxy port.
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
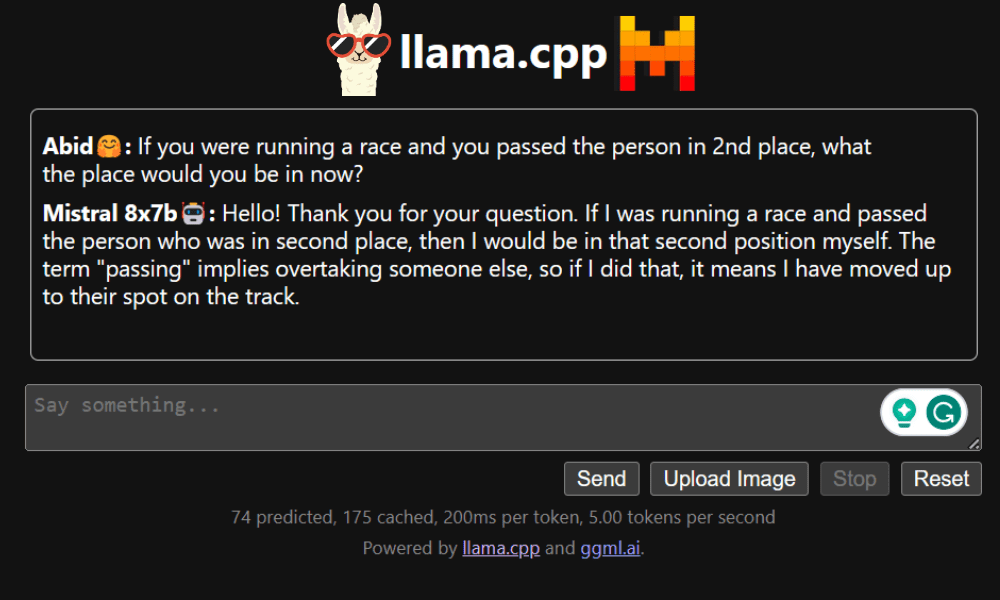
The chat webapp can be accessed by clicking on the proxy port hyperlink in the previous step since the server is not running locally.
LLaMA C++ Webapp
Before we begin using the chatbot, we need to customize it. Replace “LLaMA” with your model name in the prompt section. Additionally, modify the user name and bot name to distinguish between the generated responses.
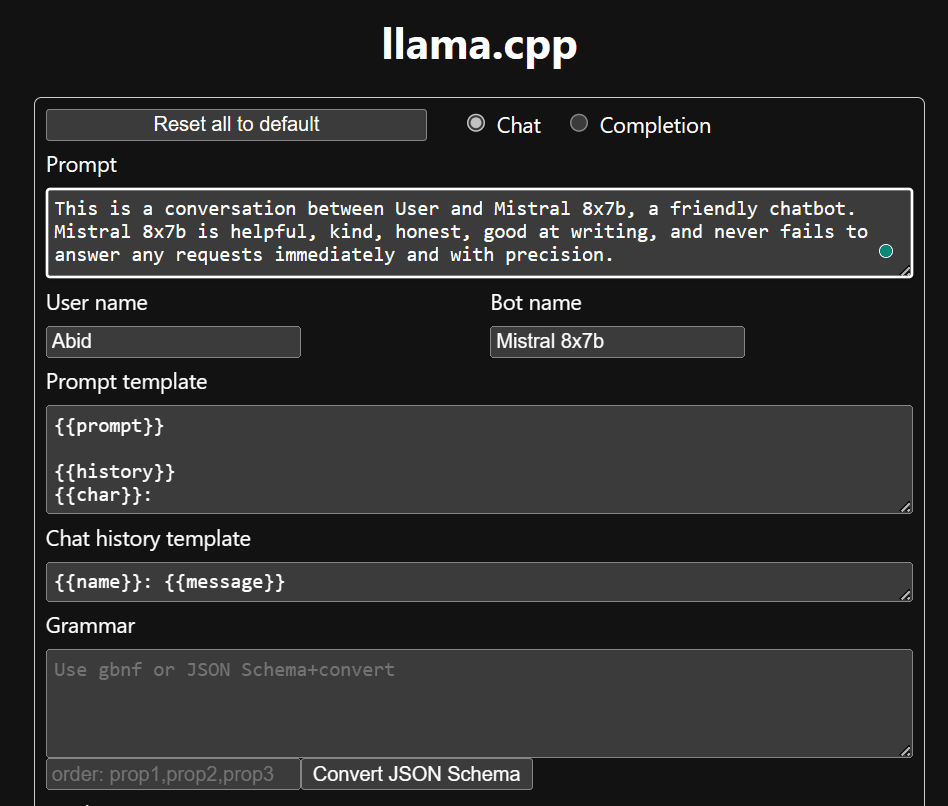
Start chatting by scrolling down and typing in the chat section. Feel free to ask technical questions that other open source models have failed to answer properly.
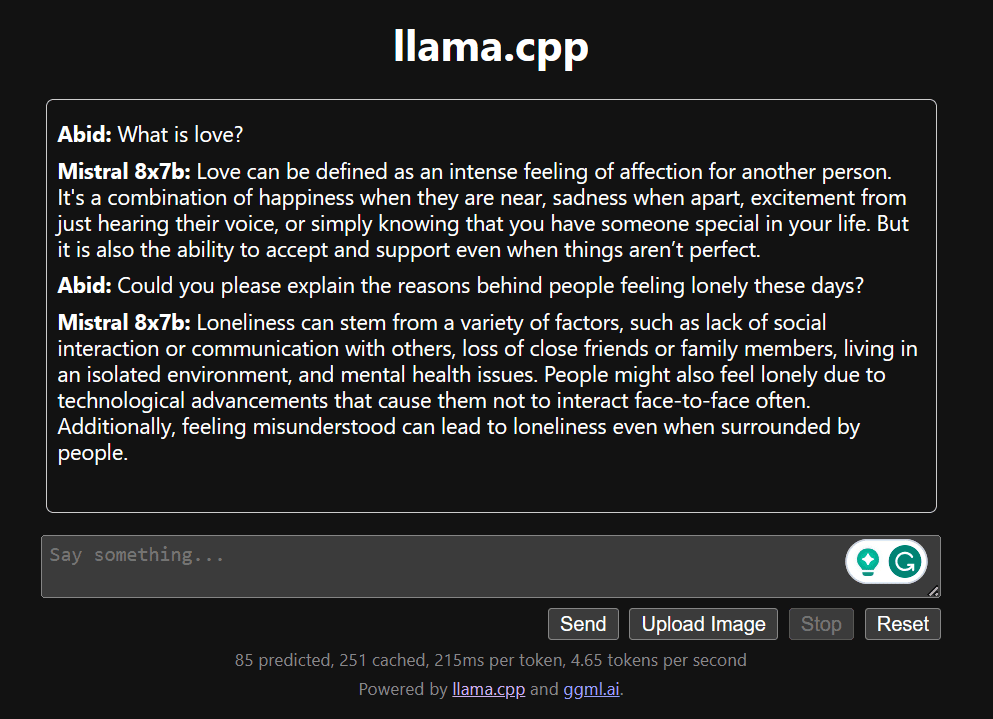
If you encounter issues with the app, you can try running it on your own using my Google Colab: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
This tutorial provides a comprehensive guide on how to run the advanced open-source model, Mixtral 8x7b, on Google Colab using the LLaMA C++ library. Compared to other models, Mixtral 8x7b delivers superior performance and efficiency, making it an excellent solution for those who want to experiment with large language models but do not have extensive computational resources. You can easily run it on your laptop or on a free cloud compute. It is user-friendly, and you can even deploy your chat app for others to use and experiment with.
I hope you found this simple solution to running the large model helpful. I am always looking for simple and better options. If you have an even better solution, please let me know, and I will cover it next time.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master’s degree in Technology Management and a bachelor’s degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.

