In artificial intelligence, a significant focus has been on developing models that simultaneously process and interpret multiple forms of data. These multimodal models are designed to analyze and synthesize information from various sources, such as text, images, and audio, mimicking human sensory and cognitive processes.
The main challenge in this field is developing systems that not only excel in single-mode tasks like image recognition or text analysis but can also integrate these capabilities to handle complex interactions between different data types. Traditional models often fall short when tasks require a seamless blend of visual and textual understanding.
Historically, models have been limited by their specialization in processing textual or visual data, with diminished efficacy when tasked with interpreting the nexus of the two. This limitation is particularly evident in scenarios where the model must generate content involving text and image components, such as automatically generating descriptive captions for images that accurately reflect the visual content.
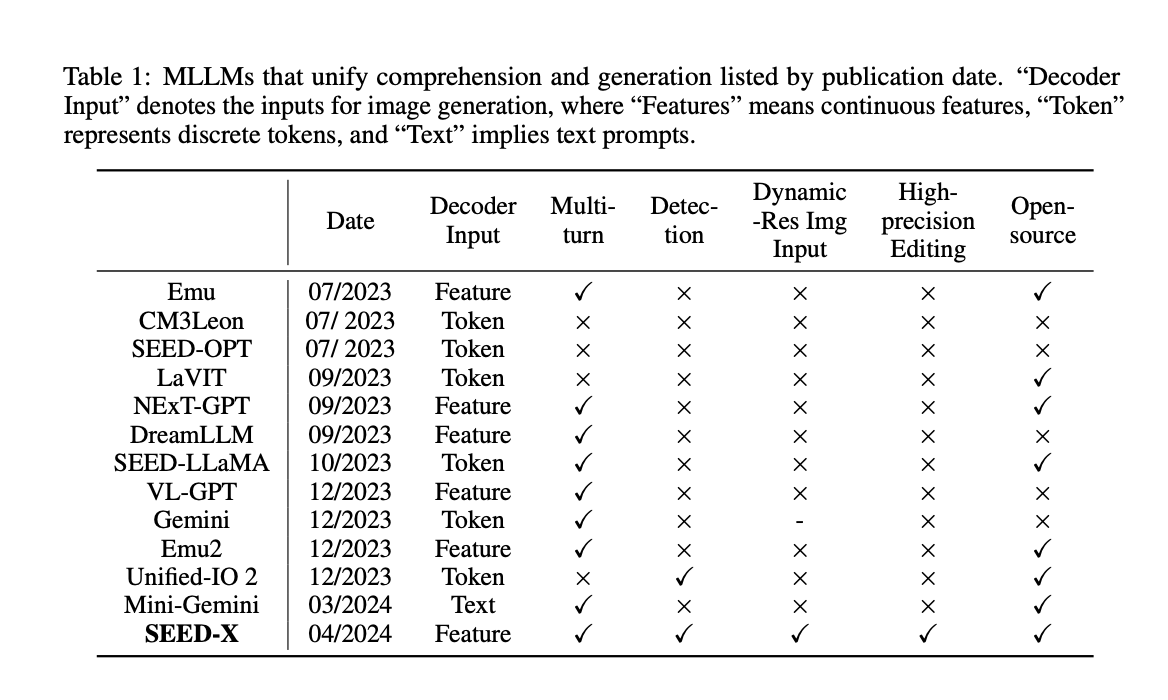
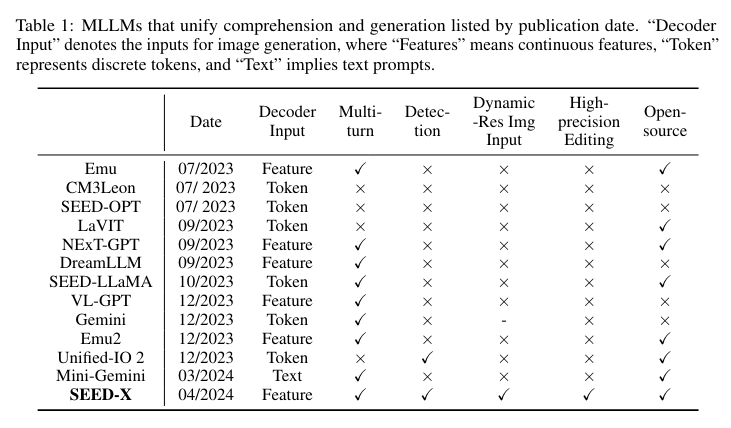
SEED-X by researchers from Tencent AI Lab and ARC Lab, Tencent PCG has made great progress in overcoming the abovementioned hurdles. SEED-X enhances the abilities of its predecessor, SEED-LLaMA, by integrating features that allow for a more holistic approach to multimodal data processing. This new model employs a sophisticated visual tokenizer and a multi-granularity de-tokenizer that work together to understand and generate content across different modalities.
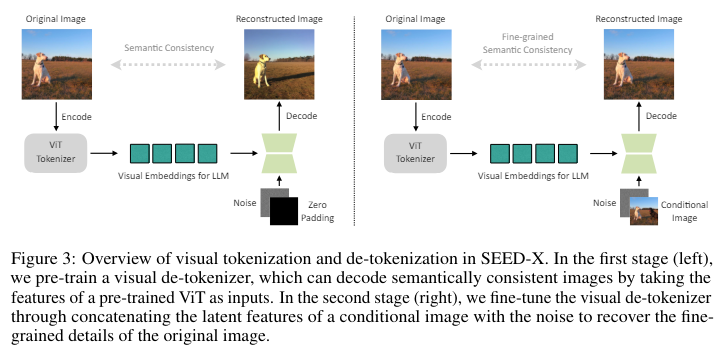
SEED-X is designed to address the challenges of multimodal comprehension and generation by incorporating dynamic resolution image encoding and a unique visual de-tokenizer that can reconstruct images from textual descriptions with high semantic fidelity. The model’s ability to handle images of arbitrary sizes and aspect ratios significantly broadens its applicability in real-world settings.
SEED-X demonstrates robust capabilities across a variety of applications. It can generate images closely aligned with their textual descriptions, showcasing an advanced understanding of the nuances in multimodal data. The model’s performance metrics indicate substantial improvements over traditional models, achieving new benchmarks in multimodal tasks. For instance, in tests involving image and text integration, SEED-X achieved a performance increase of approximately 20% over previous models.
The comprehensive capabilities of SEED-X suggest a transformative potential for AI applications. By enabling more nuanced and sophisticated interactions between different data types, SEED-X paves the way for innovative applications in areas ranging from automated content generation to enhanced interactive user interfaces.
In conclusion, SEED-X marks a significant advancement in artificial intelligence by addressing the critical challenge of multimodal data integration. Employing innovative methods such as a visual tokenizer and a multi-granularity de-tokenizer, SEED-X enhances comprehension and generation capabilities across diverse data types. The results are compelling; SEED-X significantly outperforms traditional models, demonstrating its superior ability to generate and understand complex interactions between text and images. This breakthrough paves the way for more sophisticated and intuitive AI applications that operate effectively in dynamic, real-world environments.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.

