
The world of artificial intelligence has been abuzz with the remarkable achievements of Large Language Models (LLMs) like GPT, PaLM, and LLaMA. These models have demonstrated an impressive understanding and generation of natural language, signaling a promising step toward artificial general intelligence. However, while LLMs excel at processing text, extending their capabilities to videos with rich temporal information has been a significant challenge.
Existing approaches to enable video understanding in LLMs have had their limitations. Some methods rely on the average pooling of video frames, which fails to capture the dynamic temporal sequences effectively. Others incorporate additional structures for temporal sampling and modeling, but these solutions demand extensive computational resources and often require multi-stage pretraining.
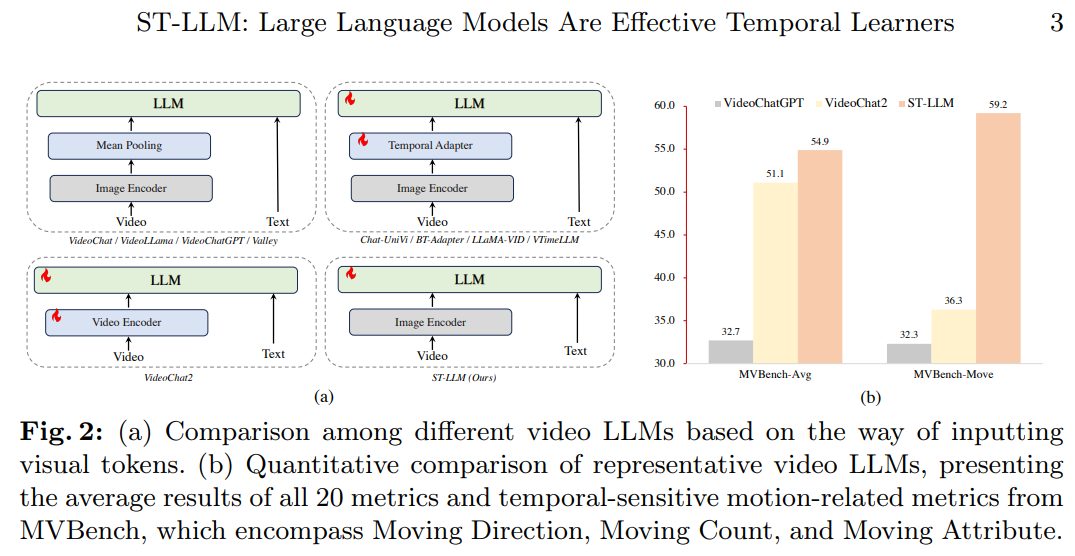
To tackle this challenge, a team of researchers from Peking University and Tencent has proposed a novel approach called ST-LLM. The core idea is simple yet unexplored: leverage the robust sequence modeling capabilities inherent in LLMs to process raw spatial-temporal video tokens directly.

ST-LLM feeds all video frames into the LLM, as shown in Figure 2 and 3, allowing it to model the spatial-temporal sequences effectively. The researchers introduce a dynamic video token masking strategy and masked video modeling during training to address the potential issue of increased context length for long videos. This approach not only reduces the sequence length but also enhances the model’s robustness to varying video lengths during inference.
For particularly long videos, ST-LLM employs a unique global-local input mechanism. It combines the average pooling of a large number of frames (global representation) with a smaller subset of frames (local representation). This asymmetric design enables processing a large number of video frames while preserving the modeling of video tokens within the LLM.
Extensive experiments on various video benchmarks, including MVBench, VideoChatGPT-Bench, and zero-shot video QA, have demonstrated the remarkable effectiveness of ST-LLM. Qualitatively, the model exhibits superior temporal understanding compared to other video LLMs, accurately capturing even complex motion and scene transitions. Quantitatively, ST-LLM achieves state-of-the-art performance, particularly excelling in metrics related to temporal-sensitive motion.
While ST-LLM struggles with fine-grained tasks like pose estimation, its ability to leverage the LLM’s sequence modeling capabilities without introducing additional modules or expensive pretraining is a significant advantage. The researchers have successfully harnessed the power of LLMs for video understanding, opening up new possibilities in this domain.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
Vibhanshu Patidar is a consulting intern at MarktechPost. Currently pursuing B.S. at Indian Institute of Technology (IIT) Kanpur. He is a Robotics and Machine Learning enthusiast with a knack for unraveling the complexities of algorithms that bridge theory and practical applications.

