Adopting finetuned adapters has become a cornerstone in generative image models, facilitating customized image creation while minimizing storage requirements. This transition has catalyzed the development of expansive open-source platforms, fostering communities to innovate and exchange various adapters and model checkpoints, thereby propelling the proliferation of creative AI art. With over 100,000 adapters now available, the Low-Rank Adaptation (LoRA) method has emerged as the prevailing finetuning technique. This evolution has led to a new paradigm where users creatively combine multiple adapters atop existing checkpoints to produce high-fidelity images, transcending the conventional focus on enhancing model class or scale.
However, amid these performance advancements, a critical challenge persists in automatically selecting relevant adapters based on user-provided prompts. This task diverges from existing retrieval-based systems used in text ranking, as efficiently retrieving adapters necessitates converting them into lookup embeddings.
This process is hindered by factors such as low-quality documentation or limited access to training data, which are common predicaments encountered on open-source platforms. Additionally, in image generation, user prompts often imply multiple highly specific tasks, requiring the segmentation of prompts into distinct keywords and the selection of pertinent adapters for each task—a task beyond the capabilities of existing retrieval-based systems.
To address these challenges, a novel system called Stylus is proposed by a team of researchers from UC Berkeley and CMU MLD, designed to efficiently evaluate user prompts, retrieve and combine sets of highly relevant adapters, and automatically enhance generative models for diverse, high-quality image production.
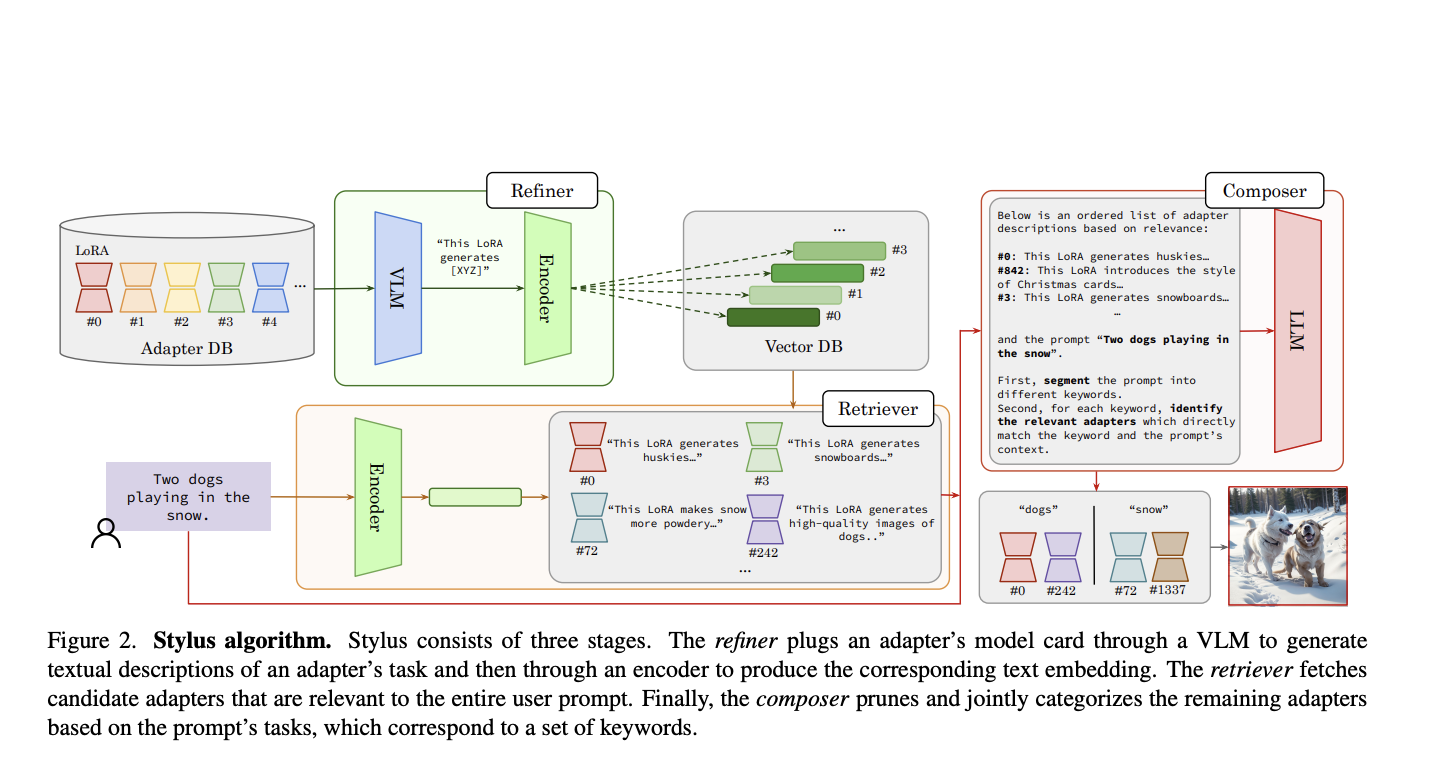
Stylus operates through a three-stage framework: the refiner pre-computes concise adapter descriptions as lookup embeddings, the retriever assesses the relevance of each embedding against the user’s prompt to retrieve candidate adapters, and the composer segments the prompt into tasks, prunes irrelevant candidates, and assigns adapters to each task accordingly. This approach ensures the identification of highly relevant adapters while mitigating biases that may degrade image quality.
Moreover, Stylus introduces a binary mask mechanism to control the number of adapters per task, ensuring image diversity and mitigating challenges associated with composing multiple adapters. To evaluate its efficacy, the authors introduce StylusDocs, an adapter dataset containing 75,000 LoRAs with pre-computed documentation and embeddings.
Results indicate that Stylus enhances visual fidelity, textual alignment, and image diversity compared to popular Stable Diffusion (SD 1.5) checkpoints, improving efficiency and 2x higher preference scores with human evaluators and vision-language models.
In conclusion, Stylus presents a practical solution for automating the selection and composition of adapters in generative image models. It offers improvements across various evaluation metrics without imposing significant overhead on the image generation process. Moreover, its versatility extends beyond image generation, potentially benefiting other image-to-image application domains such as inpainting and translation.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.