
Image by Author
There are many courses and resources available on machine learning and data science, but very few on data engineering. This raises some questions. Is it a difficult field? Is it offering low pay? Is it not considered as exciting as other tech roles? However, the reality is that many companies are actively seeking data engineering talent and offering substantial salaries, sometimes exceeding $200,000 USD. Data engineers play a crucial role as the architects of data platforms, designing and building the foundational systems that enable data scientists and machine learning experts to function effectively.
Addressing this industry gap, DataTalkClub has introduced a transformative and free bootcamp, “Data Engineering Zoomcamp“. This course is designed to empower beginners or professionals looking to switch careers, with essential skills and practical experience in data engineering.
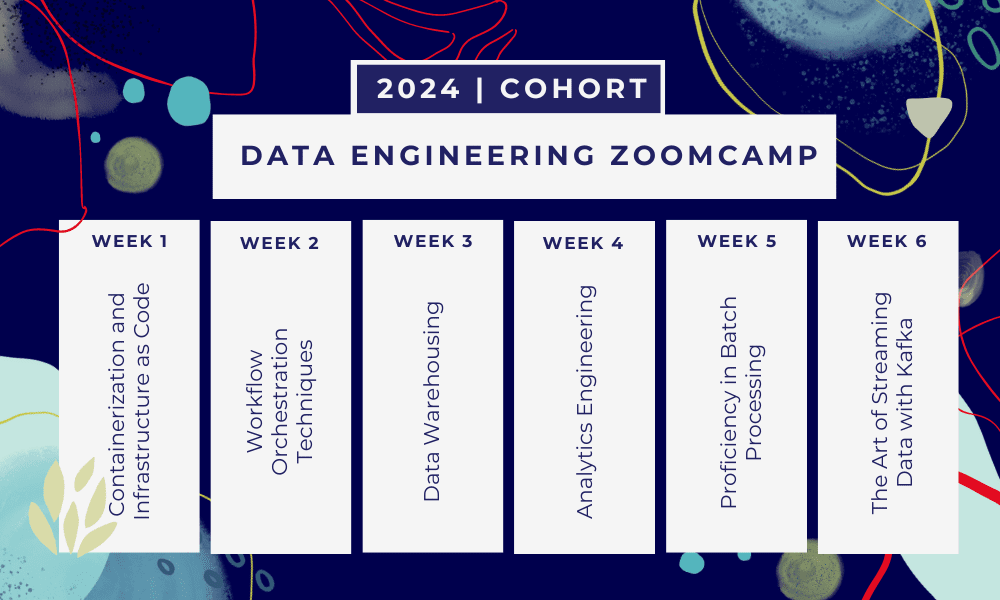
This is a 6-week bootcamp where you will learn through multiple courses, reading materials, workshops, and projects. At the end of each module, you will be given homework to practice what you’ve learned.
- Week 1: Introduction to GCP, Docker, Postgres, Terraform, and environment setup.
- Week 2: Workflow orchestration with Mage.
- Week 3: Data warehousing with BigQuery and machine learning with BigQuery.
- Week 4: Analytical engineer with dbt, Google Data Studio, and Metabase.
- Week 5: Batch processing with Spark.
- Week 6: Streaming with Kafka.
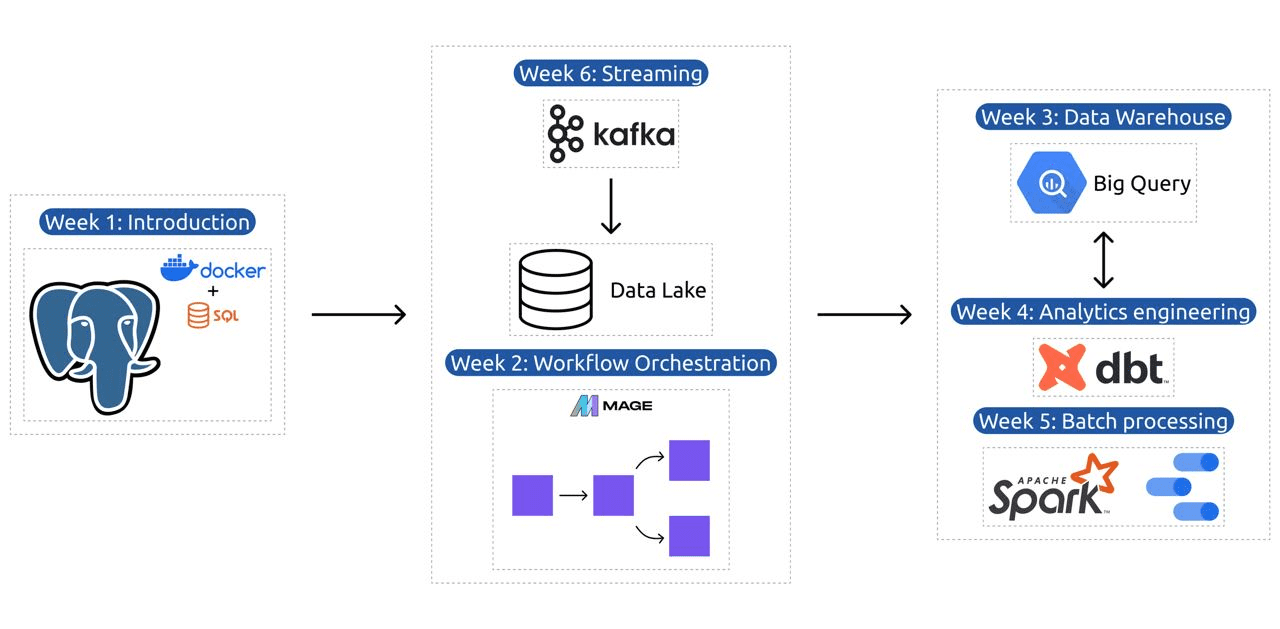
Image from DataTalksClub/data-engineering-zoomcamp
The syllabus contains 6 modules, 2 workshops, and a project that covers everything needed for becoming a professional data engineer.
Module 1: Mastering Containerization and Infrastructure as Code
In this module, you will learn about the Docker and Postgres, starting with the basics and advancing through detailed tutorials on creating data pipelines, running Postgres with Docker, and more.
The module also covers essential tools like pgAdmin, Docker-compose, and SQL refresher topics, with optional content on Docker networking and a special walk-through for Windows subsystem Linux users. In the end, the course introduces you to GCP and Terraform, providing a holistic understanding of containerization and infrastructure as a code, essential for modern cloud-based environments.
Module 2: Workflow Orchestration Techniques
The module offers an in-depth exploration of Mage, an innovative open-source hybrid framework for data transformation and integration. This module begins with the basics of workflow orchestration, progressing to hands-on exercises with Mage, including setting it up via Docker and building ETL pipelines from API to Postgres and Google Cloud Storage (GCS), and then into BigQuery.
The module’s blend of videos, resources, and practical tasks ensures a comprehensive learning experience, equipping learners with the skills to manage sophisticated data workflows using Mage.
Workshop 1: Data Ingestion Strategies
In the first workshop you will master building efficient data ingestion pipelines. The workshop focuses on essential skills like extracting data from APIs and files, normalizing and loading data, and incremental loading techniques. After completing this workshop, you will be able to create efficient data pipelines like a senior data engineer.
Module 3: Data Warehousing
The module is an in-depth exploration of data storage and analysis, focusing on Data Warehousing using BigQuery. It covers key concepts such as partitioning and clustering, and dives into BigQuery’s best practices. The module progresses into advanced topics, particularly the integration of Machine Learning (ML) with BigQuery, highlighting the use of SQL for ML, and providing resources on hyperparameter tuning, feature preprocessing, and model deployment.
Module 4: Analytics Engineering
The analytics engineering module focuses on building a project using dbt (Data Build Tool) with an existing data warehouse, either BigQuery or PostgreSQL.
The module covers setting up dbt in both cloud and local environments, introducing analytics engineering concepts, ETL vs ELT, and data modeling. It also covers advanced dbt features such as incremental models, tags, hooks, and snapshots.
In the end, the module introduces techniques for visualizing transformed data using tools like Google Data Studio and Metabase, and it provides resources for troubleshooting and efficient data loading.
Module 5: Proficiency in Batch Processing
This module covers batch processing using Apache Spark, starting with introductions to batch processing and Spark, along with installation instructions for Windows, Linux, and MacOS.
It includes exploring Spark SQL and DataFrames, preparing data, performing SQL operations, and understanding Spark internals. Finally, it concludes with running Spark in the cloud and integrating Spark with BigQuery.
Module 6: The Art of Streaming Data with Kafka
The module begins with an introduction to stream processing concepts, followed by in-depth exploration of Kafka, including its fundamentals, integration with Confluent Cloud, and practical applications involving producers and consumers.
The module also covers Kafka configuration and streams, addressing topics like stream joins, testing, windowing, and the use of Kafka ksqldb & Connect. Additionally, it extends its focus to Python and JVM environments, featuring Faust for Python stream processing, Pyspark – Structured Streaming, and Scala examples for Kafka Streams.
Workshop 2: Stream Processing with SQL
You will learn to process and manage streaming data with RisingWave, which provides a cost-efficient solution with a PostgreSQL-style experience to empower your stream processing applications.
Project: Real-World Data Engineering Application
The objective of this project is to implement all the concepts we have learned in this course to construct an end-to-end data pipeline. You will be creating to create a dashboard consisting of two tiles by selecting a dataset, building a pipeline for processing the data and storing it in a data lake, building a pipeline for transferring the processed data from the data lake to a data warehouse, transforming the data in the data warehouse and preparing it for the dashboard, and finally building a dashboard to present the data visually.
2024 Cohort Details
- Registration: Enroll Now
- Start date: January 15, 2024, at 17:00 CET
- Self-paced learning with guided support
- Cohort folder with homeworks and deadlines
- Interactive Slack Community for peer learning
Prerequisites
- Basic coding and command line skills
- Foundation in SQL
- Python: beneficial but not mandatory
Expert Instructors Leading Your Journey
- Ankush Khanna
- Victoria Perez Mola
- Alexey Grigorev
- Matt Palmer
- Luis Oliveira
- Michael Shoemaker
Join our 2024 cohort and start learning with an amazing data engineering community. With expert-led training, hands-on experience, and a curriculum tailored to the needs of the industry, this bootcamp not only equips you with the necessary skills but also positions you at the forefront of a lucrative and in-demand career path. Enroll today and transform your aspirations into reality!
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master’s degree in Technology Management and a bachelor’s degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.

