
Language models’ evolution is shifting from Large Language Models (LLMs) to the era of Small Language Models (SLMs). At the core of both LLMs and SLMs lies the power of transformers, which are the building blocks of LLMs and SLMs. While transformers have proven their outstanding performance across domains through their attention networks, multiple issues exist in attention networks, including low inductive bias and quadratic complexity concerning input sequence length.
State Space Models (SSMs) like S4 and others have emerged to address the above issues and help handle longer sequence lengths. S4 has been less effective in catering to modeling information-dense data, particularly in domains such as computer vision, and faces challenges in discrete scenarios like genomic data. Mamba, a selective state space sequence modeling technique, was recently proposed to address typical state space models’ difficulties in handling long sequences efficiently. However, Mamba has stability issues, i.e., the training loss is not converging while scaling to large-sized networks for computer vision datasets.
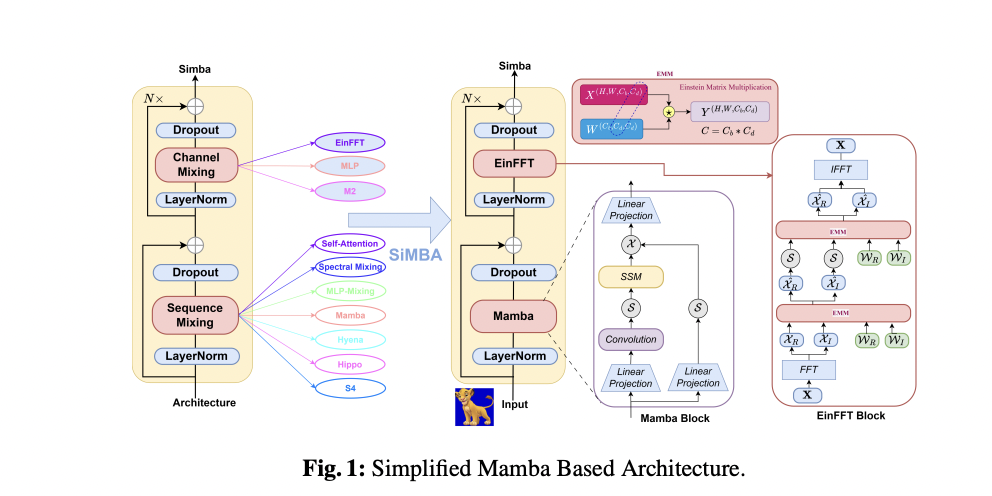
The researchers from Microsoft introduced SiMBA, a new architecture that introduces Einstein FFT (EinFFT) for channel modeling. SiMBA architecture incorporates Mamba for sequence modeling and introduces EinFFT as a new channel modeling technique. SiMBA effectively addresses the instability issues observed in Mamba when scaling to large networks. This method highlights various models based on convolutional models, transformers models, MLP-mixers, spectralmixers models, and state space methods. Also, it introduces hybrid models combining convolution with transformers or spectral approaches.
The Channel Mixing component of SiMBA incorporates three main components: Spectral Transformation, Spectral Gating Network using Einstein Matrix multiplication, and Inverse Spectral Transformation. EinFFT utilizes frequency-domain channel mixing by applying Einstein Matrix multiplication on complex number representations. This enables the extraction of crucial data patterns with enhanced global visibility and energy concentration. Mamba combined with MLP for channel mixing bridges the performance gap for small-scale networks but may have the same stability issues for large networks. Combined with EinFFT, Mamba solves stability issues for small-scale and large networks.
SiMBA demonstrates superior performance across multiple evaluation metrics, including Mean Squared Error (MSE) and Mean Absolute Error (MAE), outperforming the state-of-the-art models. These results highlight the effectiveness of the SiMBA architecture in handling diverse time series forecasting tasks and modalities, solidifying its position as a leading model in the field. By conducting performance evaluations on the ImageNet 1K dataset, the model demonstrates remarkable performance with an 84.0% top-1 accuracy, surpassing prominent convolutional networks like ResNet-101 and ResNet-152, as well as leading transformers such as EffNet, ViT, Swin, and DeIT.
The major contributions of the researchers in this paper are the following:
- EinFFT: A new technique for channel modeling known as EinFFT is proposed to solve the stability issue in Mamba. This uses Fourier transforms with nonlinearity to model eigenvalues as negative real numbers, which solves instability.
- SiMBA: Researchers propose an optimized Mamba architecture for computer vision tasks called SiMBA. This architecture uses EinFFT for channel modeling and Mamba for token mixing to handle inductive bias and computational complexity.
- Performance Gap: SiMBA is the first SSM to close the performance gap with state-of-the-art attention-based transformers on the ImageNet dataset and six standard time series datasets.
In conclusion, The researchers from Microsoft have proposed SiMBA, a new architecture that utilizes EinFFT for channel modeling and Mamba for sequence modeling. SiMBA allows for exploring various alternatives for sequence modeling like S4, long conv, Hyena, H3, RWKV, and even newer state space models. SiMBA also bridges the performance gap that most state space models have with state-of-the-art transformers on both vision and time series datasets.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.

