A team of researchers from MIT and the Institute of AI and Fundamental Interactions (IAIFI) has introduced a groundbreaking framework for robotic manipulation, addressing the challenge of enabling robots to understand and manipulate objects in unpredictable and cluttered environments. The problem at hand is the need for robots to have a detailed understanding of 3D geometry, which is often lacking in 2D image features.
Currently, many robotic tasks require both spatial and semantic understanding. For instance, a warehouse robot may need to pick up an item from a cluttered storage bin based on a text description in a product manifest. This necessitates the ability to grasp objects with stable affords based on both their geometric properties and semantic attributes.
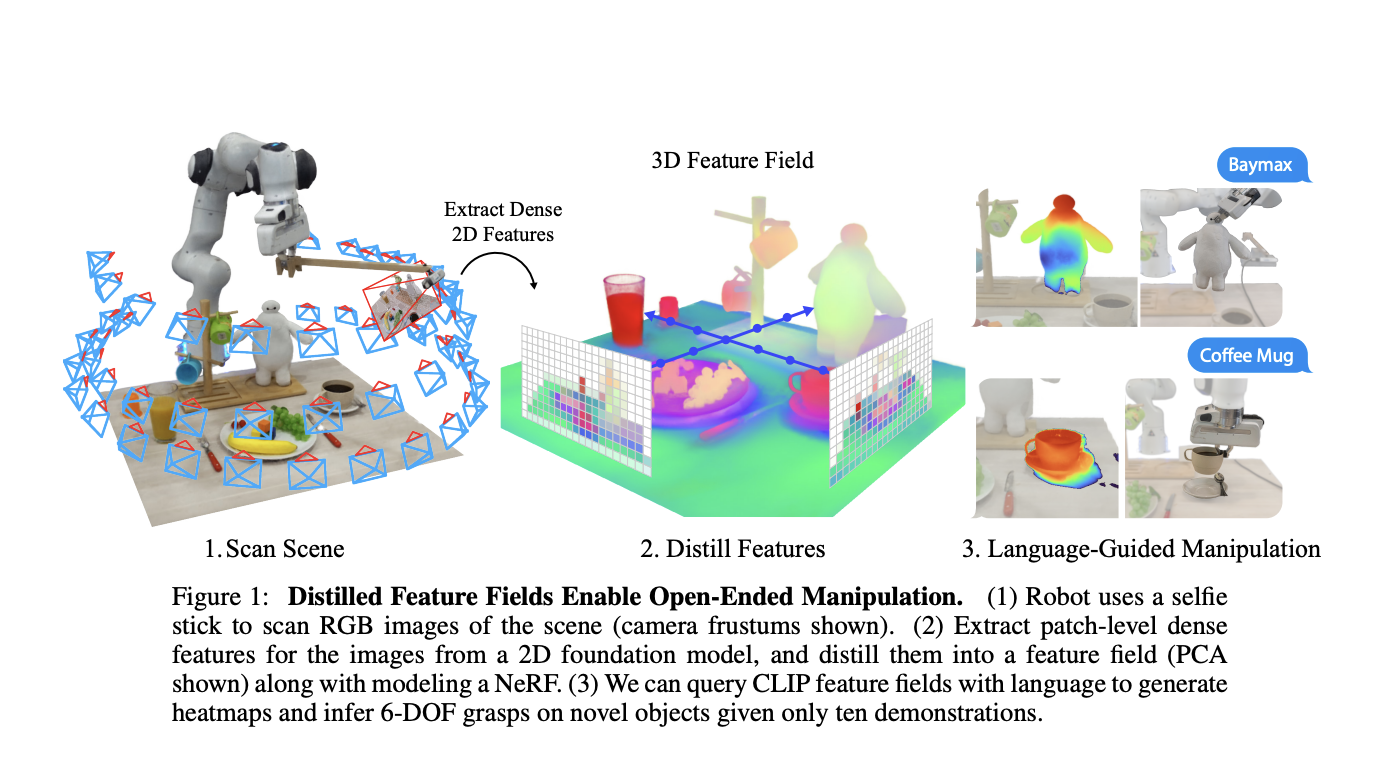
To bridge this gap between 2D image features and 3D geometry, the researchers developed a framework called Feature Fields for Robotic Manipulation (F3RM). This approach leverages distilled feature fields, combining accurate 3D geometry with rich semantics from 2D foundation models. The key idea is to use pre-trained vision and vision-language models to extract features and distill them into 3D feature fields.
The F3RM framework involves three main components: feature field distillation, representing 6-DOF poses with feature fields, and open-text language guidance. Distilled Feature Fields (DFFs) extend the concept of Neural Radiance Fields (NeRF) by including an additional output to reconstruct dense 2D features from a vision model, which allows the model to map a 3D position to a feature vector, incorporating both spatial and semantic information.
For pose representation, the researchers use a set of query points in the gripper’s coordinate frame, which are sampled from a 3D Gaussian. These points are transformed into the world frame, and the features are weighted based on the local geometry. The resulting feature vectors are concatenated into a representation of the pose.
The framework also includes the ability to incorporate open-text language commands for object manipulation. The robot receives natural language queries specifying the object to manipulate during testing. It then retrieves relevant demonstrations, initializes coarse grasps, and optimizes the grasp pose based on the provided language guidance.
In terms of results, the researchers conducted experiments on grasping and placing tasks, as well as language-guided manipulation. It could understand density, color and distance between items. Experiments with cups, mugs, screwdriver handles, and caterpillar ears showed successful runs. The robot could generalize to objects that differ significantly in shape, appearance, materials, and poses. It also successfully responded to free-text natural language commands, even for new categories of objects not seen during demonstrations.
In conclusion, the F3RM framework offers a promising solution to the challenge of open-set generalization for robotic manipulation systems. By combining 2D visual priors with 3D geometry and incorporating natural language guidance, it paves the way for robots to handle complex tasks in diverse and cluttered environments. While there are still limitations, such as the time it takes to model each scene, the framework holds significant potential for advancing the field of robotics and automation.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.

