
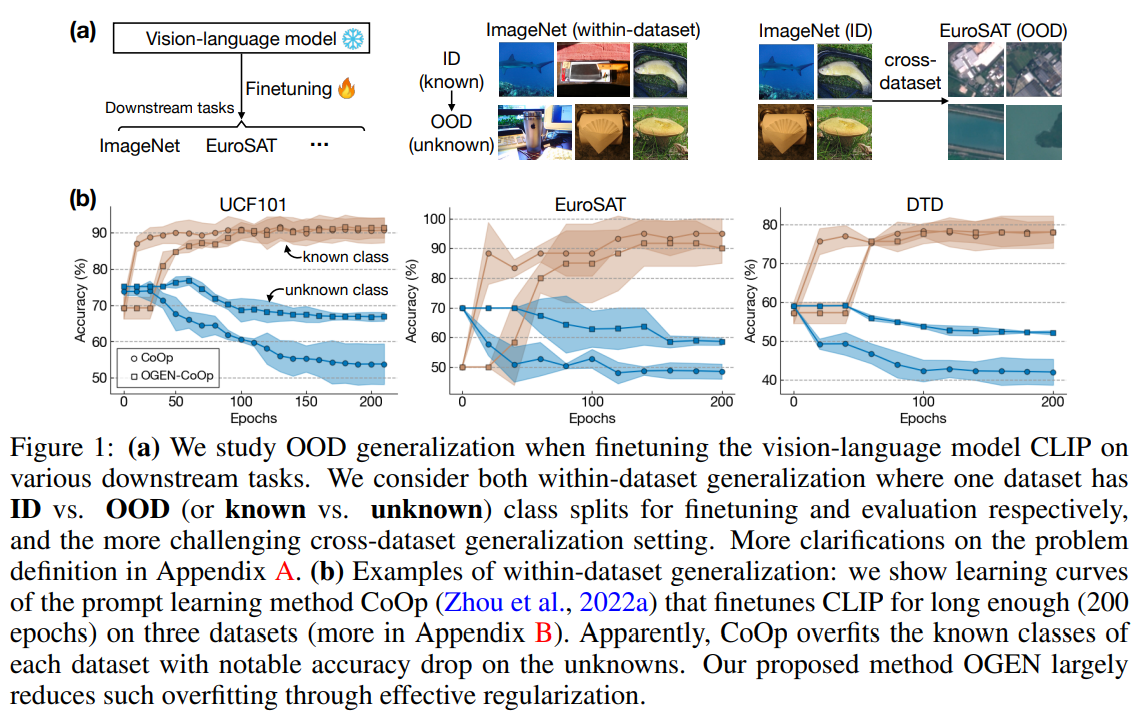
Large-scale pre-trained vision-language models, exemplified by CLIP (Radford et al., 2021), exhibit remarkable generalizability across diverse visual domains and real-world tasks. However, their zero-shot in-distribution (ID) performance faces limitations on certain downstream datasets. Additionally, when evaluated in a closed-set manner, these models often struggle with out-of-distribution (OOD) samples from novel classes, posing safety risks in the open domain. Recent efforts aim to enhance zero-shot OOD detection, either through softmax scaling or by incorporating an extra text generator. Fort et al. (2021) demonstrate promise by finetuning CLIP models on an ID dataset, improving both ID and OOD accuracies. However, extensive benchmarking reveals a susceptibility to overfitting (see Figure 1(b)) during finetuning without proper regularization, hindering generalization on unknown classes. This paper introduces a novel approach that combines image feature synthesis for unknown classes and an unknown-aware finetuning algorithm with effective model regularization.
Given the absence of knowledge about unknown classes, the proposed method addresses the challenge of effective model regularization. It introduces a class-conditional feature generator that synthesizes image features for unknown classes based on CLIP’s well-aligned image-text feature spaces. This lightweight attention module, equipped with an “extrapolating bias” on unknown classes, generalizes well to “unknown unknowns,” enabling the modeling of complex visual class distributions in the open domain. By leveraging both ID and synthesized OOD data for joint optimization, the approach aims to establish a better-regularized decision boundary, preserving ID performance while enhancing OOD generalization.
Early experiments reveal the difficulty of directly generating OOD features from class names due to their non-linear and high-dimensional nature. To address this, the authors reframe the feature synthesis problem, introducing an “extrapolating bias” to extrapolate features from similar known classes, such as generating features of the unknown class raccoon by extrapolating from training classes like cat and bear. The proposed method (see Figure 2(c)) incorporates Multi-Head Cross-Attention (MHCA) to effectively capture similarities between the unknown class and each known class, offering an innovative solution to the feature synthesis challenge.
The paper introduces two feature synthesis methods: “extrapolating per class” and “extrapolating jointly.” While both approaches aim to synthesize unknown features, the latter proves to be more collaborative and consistently outperforms the former in experiments. An adaptive self-distillation mechanism is presented to further reduce overfitting during joint optimization. This mechanism utilizes teacher models from historical training epochs to guide optimization at the current epoch, ensuring consistency between predictions induced by the teacher and student models.
The proposed approach, named OGEN, is evaluated across different finetuning methods for CLIP-like models. It consistently improves OOD generalization performance under two challenging settings: within-dataset (base-to-new class) generalization and cross-dataset generalization. OGEN is shown to be effective across various baselines, demonstrating its potential to address overfitting and improve both ID and OOD performance.
In the within-dataset generalization setting, OGEN enhances new class accuracy without compromising base class accuracy, showcasing its ability to strike a favorable trade-off between ID and OOD performance. Comparative analysis with state-of-the-art methods reveals the consistent improvement achieved by OGEN.
Cross-dataset generalization experiments demonstrate the universality of OGEN’s approach. It uniformly improves generalization performance across different target datasets, with substantial gains observed on datasets with significant distribution shifts from ImageNet.
In conclusion, this paper introduces an innovative approach to navigate challenges in OOD generalization for vision-language models. By combining feature synthesis for unknown classes and adaptive regularization, OGEN achieves improved performance across diverse datasets and settings. Future work includes extending the evaluation of OGEN to other finetuning methods and exploring its effectiveness in modeling uncertainties on unseen data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.

