
Language modeling, a critical component of natural language processing, involves the development of models to process and generate human language. This field has seen transformative advancements with the advent of large language models (LLMs). The primary challenge lies in efficiently optimizing these models. Distributed training with multiple devices faces communication latency hurdles, especially when varying in computational capabilities or geographically dispersed.
Traditionally, Local Stochastic Gradient Descent (Local-SGD), known as federated averaging, is used in distributed optimization for language modeling. This method involves each device performing several local gradient steps before synchronizing their parameter updates to reduce communication frequency. However, this approach can be inefficient due to the straggler effect, where faster devices remain idle, waiting for slower ones to catch up, thus undermining the system’s overall efficiency.
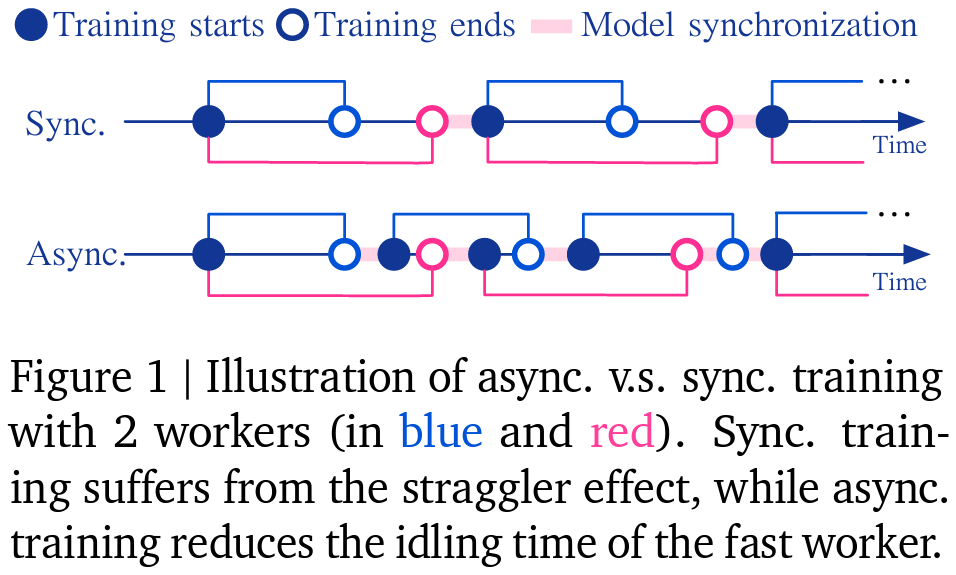
Research by DeepMind introduces an innovative method to enhance asynchronous Local-SGD for language modeling. This method updates global parameters asynchronously as workers complete their Stochastic Gradient Descent (SGD) steps. By doing so, it seeks to overcome the limitations inherent in synchronous Local-SGD, particularly concerning the varied computational capabilities of worker hardware and different model sizes.
The methodology of the proposed approach is intricate yet effective. It incorporates a delayed Nesterov momentum update to handle momentum acceleration, a challenge when worker gradients are stale. This technique involves adjusting the local training steps of workers based on their computation speed, which aligns with the dynamic local updates (DyLU) strategy. This adjustment ensures that the learning progress across various data shards is balanced, each with its own optimized learning rate schedule. Such a nuanced approach to handling asynchronous updates is pivotal in managing the complexities of distributed training.
The performance and results of this method are notable. Evaluated using models with up to 150M parameters on the C4 dataset, this approach matched the performance of its synchronous counterpart in terms of perplexity per update step. It significantly outperformed it in terms of wall clock time. This breakthrough promises faster convergence and greater efficiency, which is critical for large-scale distributed learning. The research highlights that with this approach, the issues of communication latency and inefficiency in synchronization can be effectively mitigated, paving the way for more efficient and scalable training of language models.
This study introduces a novel approach to asynchronous Local-SGD, which combines delayed Nesterov momentum updates with dynamic local updates, showcasing significant advancement in language modeling and addressing key challenges in distributed learning. This method demonstrates an improvement in training efficiency and holds promise for more scalable and effective language model training, which is pivotal in the evolution of natural language processing technologies.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.


