
Fine-tuning large language models (LLMs) enhances task performance and ensures adherence to instructions while modifying behaviors. However, this process incurs significant costs due to high GPU memory requirements, especially for large models like LLaMA 65B and GPT-3 175B. Consequently, various parameter-efficient fine-tuning (PEFT) methods, such as low-rank adaptation (LoRA), are proposed, which reduces parameters and memory usage without increasing inference latency.
Researchers from the Institute for Artificial Intelligence, Peking University, School of Intelligence Science and Technology, Peking University, and the National Key Laboratory of General Artificial Intelligence introduce Principal Singular values and Singular vectors Adaptation (PiSSA). This method optimizes a reduced parameter space by representing a matrix within the model as the product of two trainable matrices, along with a residual matrix for error correction. It utilizes Singular Value Decomposition (SVD) to factorize the matrix, initializing the principal singular values and vectors to train the two matrices while keeping the residual matrix frozen during fine-tuning. PiSSA shares the same architecture with LoRA, utilizing the hypothesis that changes in model parameters form a low-rank matrix.
PiSSA method employs SVD to factorize matrices within self-attention and MLP layers. It initializes an adapter with principal singular values and vectors and a residual matrix with residual singular values and vectors. The adapter encapsulates the model’s primary capabilities while using fewer parameters during fine-tuning. PiSSA shares the architecture with LoRA, inheriting benefits such as reduced trainable parameters, quantization of the residual model, and easy deployment. PiSSA’s early introduction preserves the model’s capabilities by rendering the residual matrix negligible, enabling the adapter to encapsulate primary capabilities. Fine-tuning mirrors the full model process, unlike LoRA, potentially avoiding wasteful gradient steps and suboptimal outcomes.
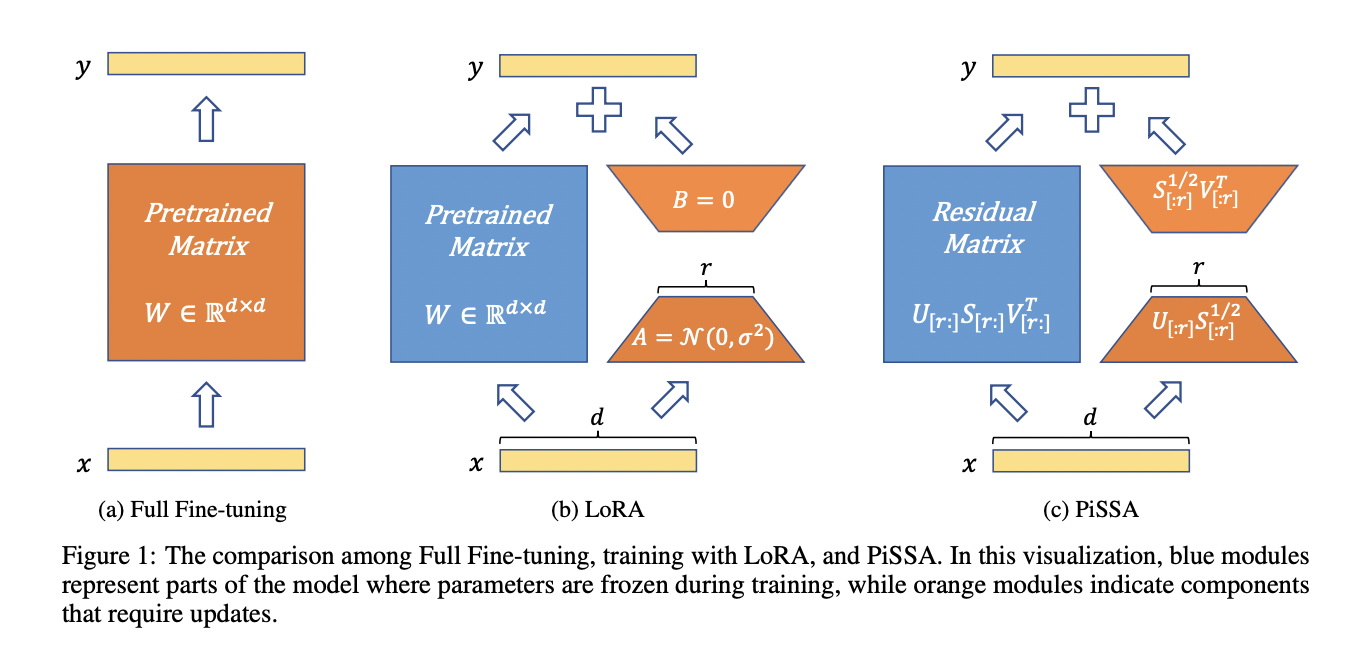
Comparative experiments between PiSSA, LoRA, and full parameter fine-tuning on LLaMA 2-7B, Mistral-7B-v0.1, and Gemma-7B models across various tasks demonstrate PiSSA’s superiority. Fine-tuning adapters initialized with principal singular values and vectors yield better outcomes, indicating that direct fine-tuning of the model’s principal components leads to superior results. PiSSA exhibits superior performance, converges more swiftly, and aligns closely with training data compared to LoRA, showcasing robust superiority under similar trainable parameter configurations. Also, employing the Fast SVD technique helps PiSSA balance initialization speed and performance.
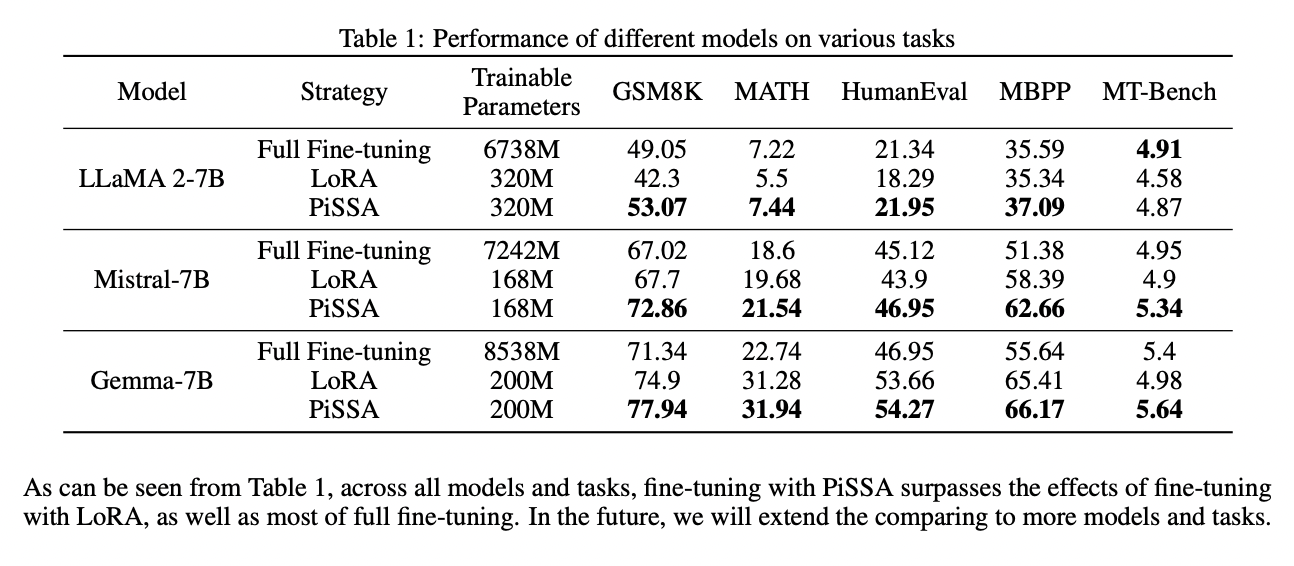
In conclusion, the research introduces PiSSA, a parameter-efficient fine-tuning technique that utilizes singular value decomposition to initialize adapters with principal components. Through extensive experiments, PiSSA demonstrates superior fine-tuning performance compared to LoRA, offering a promising approach to PEFT. Analogous to slicing and re-baking the richest pizza slice, PiSSA efficiently identifies and fine-tunes the model’s principal components. Sharing LoRA’s architecture, PiSSA presents an easy-to-use and efficient initialization method.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.

