
Language models stand as titans, harnessing the vast expanse of human language to power many applications. These models have revolutionized how machines understand and generate text, enabling translation, content creation, and conversational AI breakthroughs. Their huge size is a source of their prowess and presents formidable challenges. The computational heft required to operate these behemoths restricts their utility to those with access to significant resources. It raises concerns about their environmental footprint due to the substantial energy consumption and associated carbon emissions.
The crux of enhancing language model efficiency is navigating the delicate balance between model size and performance. Earlier models have been engineering marvels, capable of understanding and generating human-like text. Yet, their operational demands have rendered them less accessible and raised questions about their long-term viability and environmental impact. This conundrum has spurred researchers into action, developing innovative techniques aimed at slimming down these models without diluting their capabilities.
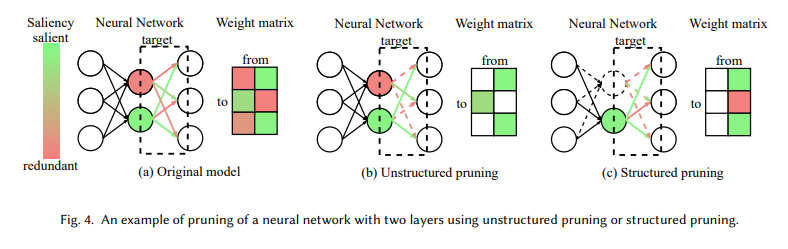
Pruning and quantization emerge as key techniques in this endeavor. Pruning involves identifying and removing parts of the model that contribute little to its performance. This surgical approach not only reduces the model’s size but also its complexity, leading to gains in efficiency. Quantization simplifies the model’s numerical precision, effectively compressing its size while maintaining its essential characteristics. These techniques represent a potent arsenal for more manageable and environmentally friendly language models.
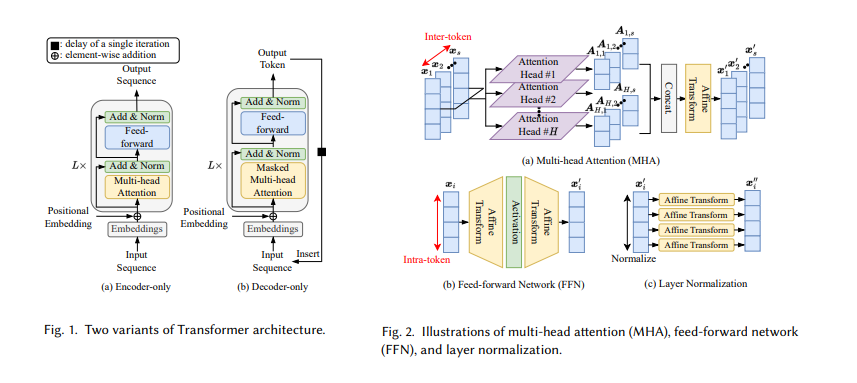
The survey by researchers from Seoul National University delves into the depths of these optimization techniques, presenting a comprehensive survey that spans the gamut from high-cost, high-precision methods to innovative, low-cost compression algorithms. These latter approaches are particularly noteworthy, offering hope for making large language models more accessible. By significantly reducing these models’ size and computational demands, low-cost compression algorithms promise to democratize access to advanced AI capabilities. The survey meticulously analyzes and compares these methods on their potential to reshape the landscape of language model optimization.

The revelations of this study are the surprising efficacy of low-cost compression algorithms in enhancing model efficiency. These previously underexplored methods have shown remarkable promise in reducing the footprint of large language models without a corresponding drop in performance. The study’s in-depth analysis of these techniques illuminates their unique contributions and underscores their potential as a focal point for future research. By highlighting the advantages and limitations of different approaches, the survey offers valuable insights into the path forward for optimizing language models.
The implications of this research are profound, extending far beyond the immediate benefits of reduced model size and improved efficiency. By paving the way for more accessible and sustainable language models, these optimization techniques have the potential to catalyze further innovations in AI. They promise a future where advanced language processing capabilities are within reach of a broader array of users, fostering inclusivity and driving progress across various applications.
In summary, the journey to optimize language models is marked by a relentless pursuit of balance – between size and performance, accessibility and capability. This research calls for a continued focus on developing innovative compression techniques that can unlock the full potential of language models. As we stand on the brink of this new frontier, the possibilities are as vast as the digital universe. The quest for more efficient, accessible, and sustainable language models is a technical challenge and a gateway to a future where AI is interwoven into our daily lives, enhancing our capabilities and enriching our understanding of the world.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.

