
As the hubs for patient care and medical administration, hospitals often manage vast amounts of paperwork and documentation. The traditional reliance on manual data entry consumes valuable time and introduces the risk of errors that can have critical consequences.
Enter Optical Character Recognition (OCR) software is a technological marvel reshaping how hospitals handle documentation processes. OCR software has emerged as a game-changer, offering solutions to some of the most pressing challenges healthcare institutions face.
What are these challenges?
- Paperwork Galore: Hospitals are inundated with paperwork daily, from patient records and prescriptions to billing documents and insurance forms. This deluge of paper poses a logistical nightmare and hinders the swift and accurate retrieval of crucial information.
- Ensuring Data Accuracy: Accuracy is paramount in healthcare, and errors in patient information or medical records can have severe consequences. Manual data entry is prone to human error, leading to misinterpretations, transcription mistakes, and jeopardizing patient safety.
- Addressing Compliance and Security Concerns: The healthcare industry operates under strict regulatory frameworks, with the Health Insurance Portability and Accountability Act (HIPAA) as a cornerstone for safeguarding patient data privacy and security. Compliance with HIPAA is non-negotiable for healthcare institutions, and any lapse in adherence can result in severe consequences.
In a field where time can be a matter of life and death, the need for streamlined document management is more pressing than ever.
Here are the top 10 OCR software for hospitals in 2024.
Automate manual data entry using Nanonet’s AI-based OCR software. Capture data from documents instantly and automate data workflows. Reduce turnaround times and eliminate manual effort.
What is OCR for Hospitals?
OCR software, or Optical Character Recognition software, converts different types of documents into machine-readable text. In hospitals, OCR software is crucial in digitizing and managing vast amounts of paperwork and documents associated with patient care, administration, and healthcare processes.
Here are key features and functionalities of OCR software for hospitals:
- Document Digitization
OCR software allows hospitals to convert physical documents, such as patient records, medical charts, prescriptions, and billing information, into digital formats. This digitization process facilitates easier storage, retrieval, and sharing of crucial healthcare information. - Text Extraction
One of the primary functions of OCR is to extract text from scanned documents or images. In the healthcare setting, this is particularly useful for capturing important details from handwritten notes, printed documents, or forms, contributing to more efficient data management. - Data Accuracy
OCR software minimizes errors associated with manual data entry. Automating text extraction from documents reduces the risk of transcription mistakes, ensuring that patient information is accurately recorded and maintained. - Workflow Efficiency
Streamlining administrative processes is essential in a hospital setting. OCR software enhances workflow efficiency by automating document handling, allowing healthcare professionals to focus more on patient care and less on paperwork. - Search and Retrieval
Digitized documents become searchable, enabling quick and easy retrieval of information. Healthcare staff can efficiently locate specific patient records or relevant medical information, contributing to faster decision-making and improved patient care. - Compliance and Security
OCR software helps hospitals adhere to regulatory standards, including those outlined in healthcare privacy laws such as HIPAA. It ensures secure handling of sensitive patient information, with features like encryption, access controls, and redaction of protected health information (PHI). - Integration with Electronic Health Records (EHR) Systems
Many OCR solutions are designed to integrate with Electronic Health Records (EHR) systems seamlessly. This integration facilitates the smooth transfer of digitized information into the hospital’s infrastructure, promoting a cohesive and centralized approach to healthcare data management. - Language Support
Hospitals often deal with documents in multiple languages. OCR software with robust language support can accurately process and extract text from documents written in different languages, ensuring inclusivity in healthcare documentation.
The Best OCR Software for Hospitals in 2024
Let’s look at some of the best OCR for hospitals available.
1. Nanonets
Nanonets stands out as a stellar OCR software solution for hospitals, offering a tailored approach to address the unique challenges faced in healthcare documentation.
Its advanced machine learning algorithms excel in accurately extracting text from diverse medical documents, including handwritten notes and complex forms. Nanonets’ exceptional data accuracy ensures precise transcription of patient records, minimizing the risk of errors and supporting healthcare professionals in delivering optimal care.
One of Nanonets’ key strengths is its seamless integration with Electronic Health Records (EHR) systems, effortlessly streamlining the transition from paper to digital workflows. The software’s robust security features, including encryption and PII redaction, align with the stringent compliance requirements of healthcare regulations such as HIPAA.
Nanonets not only revolutionizes hospital document management by enhancing efficiency and data accuracy but also empowers healthcare institutions to meet regulatory standards and prioritize patient confidentiality.
Introduction to Nanonets
Pros:
- Modern UI
- Handles large volumes of documents
- Reasonably priced
- Ease of use
- Zero-shot or zero-training data extraction
- Cognitive capture of data – resulting in minimal intervention
- Requires no in-house team of developers
- Algorithms/models can be trained/retrained
- Great documentation & support
- Lots of customization options
- Wide choice of integration options
- Accurate multilingual OCR
- Seamless 2-way integration with multiple accounting software
- Great OCR API for developers
Cons:
- Table capture UI can be better
Get started with Nanonets’ pre-trained OCR extractors or build your own custom OCR models. You can also schedule a demo to learn more about our OCR use cases!

2. ABBYY Flexicapture
ABBYY FlexiCapture is an OCR solution excelling in capturing and digitizing data from various medical documents. With its sophisticated machine learning algorithms, FlexiCapture ensures high accuracy in extracting text, making it ideal for transcribing patient records, prescriptions, and other healthcare-related paperwork.
ABBYY FlexiCapture for Invoices – Demo Video
Pros:
- Recognizes images very well
- Easy to store hard copy result in system
- Integrates well with ERP systems
- Automates data extraction from documents (to an extent)
Cons:
- Initial setup can be difficult and complex
- Automatic processing of MEDICAL DOCUMENTS not set up
- No ready-made templates
- Difficult to customize
- No resources available
- Could have better integration with RPA solutions
- Low accuracy with low resolution images/documents
- Batch verifications are held up even if there’s an error just in a particular section
- Line item error messages pop up even for items that should be skipped
- RESTful API is not available in the on-prem version
3. ABBYY Finereader
FineReader is primarily designed for individual users and small businesses, offering powerful OCR capabilities for converting scanned documents, images, and PDFs into editable and searchable formats. It’s an excellent choice for digitizing printed documents, extracting text from books, or converting paper-based content into electronic formats. While FineReader is versatile and user-friendly, it may lack some advanced automation and data capture features essential for complex, large-scale document processing common in healthcare settings.
ABBYY FineReader can be used to convert printed medical documents into digital formats or extract text from medical textbooks.
Processing Documents with ABBYY FineReader Server – Demo Video
Pros:
- Keyboard-friendly OCR editor for manual corrections
- Exceptionally clear interface
- Exports to multiple formats
- Unique document-compare feature
Cons:
- Lacks full-text indexing for fast searches
- Requires a learning curve
- Pricing can be prohibitive
- Inability to view the history of document changes
- Can’t merge several files into one
- Might require some post-processing
- The UI could be overwhelming at first
- Slow to process big files
Need an OCR software for image-to-text extraction or PDF data extraction? Check out Nanonets in action!
Omnipage is a powerful PDF OCR software that can handle automation for high-volume medical document processing tasks. The software is equipped with advanced OCR capabilities to extract text and data from scanned documents accurately. In healthcare, this feature is crucial for capturing relevant information from diverse sources like medical records and prescriptions.
Benefits:
- Minimizes downstream data flow errors with highly accurate text extraction and data from medical documents like prescriptions and test reports.
- Provides a wide range of built-in filters and tools to improve the quality of scanned or photographed medical documents before OCR.
Limitations:
- Setting up the AP automation workflows or the API integration involves intricate setups unsuitable for non-technical users.
- The interface has a steep learning curve and could be more intuitive, hampering hospital adoption.
- The UI is not intuitive and may not be a fit for busy healthcare professionals.
5. IBM Datacap
IBM Datacap is a robust document capture and processing software. Datacap helps healthcare organizations digitize patient records, prescriptions, and other documents by streamlining the capture, recognition, and classification of medical documents. With advanced features like AI-powered intelligent processing and machine learning, Datacap automates handling complex documents, enhancing accuracy and reducing the burden of manual data entry.
The integration of Datacap with IBM Cloud Pak for Business Automation provides a comprehensive solution for healthcare document management. It supports multichannel input, export to various applications, and highly adaptable rules-based capture workflows.
Pros:
- Configures complex applications in data capture
- Scanning mechanism
- Ease of use
Cons:
- Very little online support
- UI could be more intuitive
- Setup can be cumbersome
- Slow
- Creating a customized flow isn’t straightforward
- Batch commits take time
Start using Nanonets for Automation. Try out the various OCR models or request a demo today. Find out how Nanonets’ use cases can apply to your product.
6. Google Document AI
Google Document AI is a powerful document processing tool that utilizes machine learning to extract valuable information from unstructured documents. Document AI can streamline administrative tasks in healthcare by automating the extraction of crucial data from medical records, prescriptions, and invoices. Its advanced capabilities in natural language processing and intelligent data extraction contribute to improved accuracy and efficiency in document handling.
Pros:
- Easy to set up
- Integrates very well with other Google services
- Storage of information
- Speed
Cons:
- AI modules lack proper documentation
- Customization of existing modules and libraries is hard
- Not suited for Python or other coding languages
- Outdated API documentation
- Expensive
- Not suited for hybrid cloud deployments
- Not suited for use cases that require custom AI algorithms
AWS Textract is an optical character recognition (OCR) engine by Amazon Web Services. It can convert scanned images and documents into machine-readable text, with applications across various industries, including healthcare.
Tesseract’s versatility in recognizing text from various document types and languages enhances interoperability in healthcare systems. By automating the conversion of paper-based documents into digital formats, AWS Tesseract contributes to increased efficiency, improved data accuracy, and better overall patient care in healthcare institutions.
Pros:
- Pay-per-use billing model
- Ease of use
- Works well for tables and forms
Cons:
- Can’t be trained
- Varying accuracy
- Not meant for handwritten documents
Want to scrape data from PDF documents, convert PDF tables to Excel, or automate table extraction? Check out Nanonets PDF scraper or PDF parser to scrape PDF data or parse PDFs at scale!
8. Docparser
Docparser is a document parsing and data extraction platform that transforms unstructured documents, such as invoices, forms, and receipts, into structured data. Docparser can streamline document processing in healthcare by automatically extracting key information from medical records, insurance forms, and other healthcare-related documents. Its advanced parsing capabilities enable the extraction of specific data fields, facilitating accurate and efficient digitization of patient information.
Pros:
- Easy setup
- Zapier integration
Cons:
- The webhooks occasionally fail
- Requires some deal of training to pick up the parsing rules
- Not enough templates
- Zonal OCR approach – can’t handle unknown templates
- UI could be better
- Slow to load pages
- Documentation could be better
9. Adobe Acrobat DC
Adobe Acrobat is a comprehensive family of software and services developed by Adobe Inc. for creating, editing, converting, and managing PDF (Portable Document Format) files. Optical Character Recognition is a functionality within Adobe Acrobat that converts scanned paper documents or images into editable and searchable text.
With Adobe Acrobat OCR, users can recognize and extract text from scanned documents, making it possible to edit, search, and manipulate the content within PDF files. This feature is particularly useful in scenarios where the original document only exists in non-editable image formats, allowing for greater flexibility and accessibility when working with text-based information.
Pros:
- Stability/compatibility
- Ease of use
Cons:
- Expensive
- Not an exclusive OCR software
- Heavy on the system
- Takes up a lot of space on the hard disk
- Difficult to integrate with services like Sharepoint or Dropbox
- Requires an Adobe Creative Cloud license
10. Klippa
Klippa uses advanced OCR (Optical Character Recognition) and machine learning technologies to accurately identify, classify, and extract relevant information from unstructured documents, reducing manual data entry and the risk of errors.
Klippa’s applications in healthcare can lead to increased efficiency, improved accuracy in data management, and enhanced compliance with regulatory standards.
Pros:
- Fast setup
- Great support
- Great API for developers
- Clear and concise API documentation
- Links well with accounting programs
- Competitively priced
- Integrations
Cons:
- OCR recognition can be better
- Limited template customizations
- Limited white-label customizations
- Bulk adjustments not supported
- The VAT is often not displayed correctly
- The app often crashes
- Can’t train the OCR model
- The selection process isn’t straightforward, as there are a lot of options
Nanonets OCR API has many interesting use cases that could optimize your business performance, save costs,, and boost growth. Find out how Nanonets’ use cases can apply to your product.
Other notable mentions include Veryfi, Readiris, Infrrd, Rossum & Hypatos. Also, check out the leading alternatives to Nanonets.
Here’s a quick comparison of all the OCR software listed above across some crucial OCR software features & parameters:
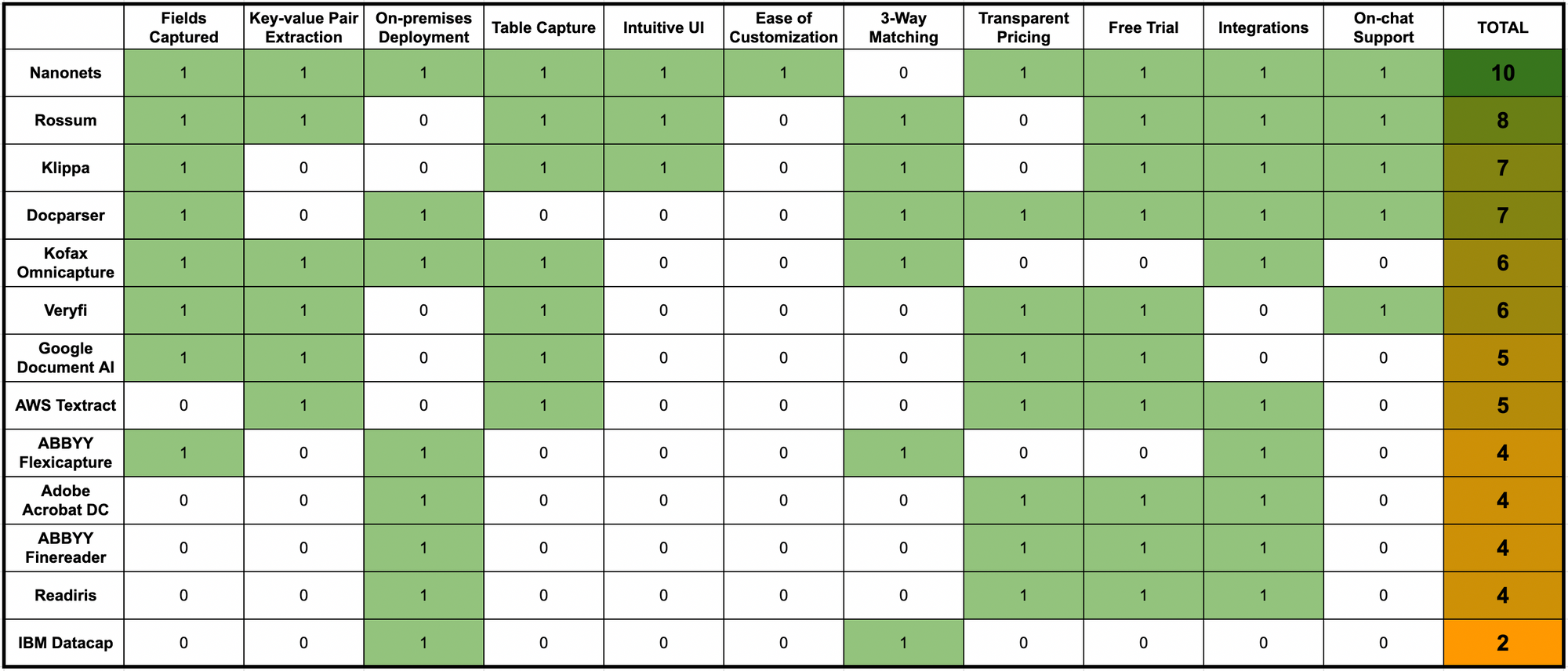
Why is Nanonets the Most Comprehensive OCR Software for Hospitals?
Nanonets OCR software is easy and flexible to set up, requiring just about one day. The intelligent automation platform handles unstructured data without much difficulty, and the AI also handles common data constraints with ease.
Nanonets OCR’s benefits in hospitals go beyond better accuracy, experience, and scalability.
- Data capture and entry—Nanonets OCR can be used to accurately capture data from prescriptions, invoices, legacy medical data, and more within seconds. The extracted data can be directly connected to any hospital management software, reducing the need for manual data entry and improving accuracy.
- Documentation and storing— Nanonets OCR can easily create digital and editable copies of all medical documents. These documents can then be easily stored and retrieved whenever required.
- Quality control—Nanonets OCR can provide multiple approval steps before a document is ingested into the system or sent for approval. This helps identify errors early and reduces the resources and costs required for rework.
- User-Friendly Interface: Nanonets has an intuitive and user-friendly interface, making it accessible to healthcare professionals without extensive technical training.
Is there any Free OCR Software for Hospitals?
Running on open-source OCR engines (like Tesseract), these free solutions help convert photos, PDFs, TIFFs, or scanned documents into editable digital text formats. While they might not be able to process complex medical records at scale, they are adequate for extracting text from simple documents with straightforward formatting.
Free OCR software regularly fails to process handwritten documents, multi-column tables, long-line items, or low-quality images/scans.
Here are some free optical character recognition tools for your consideration:

