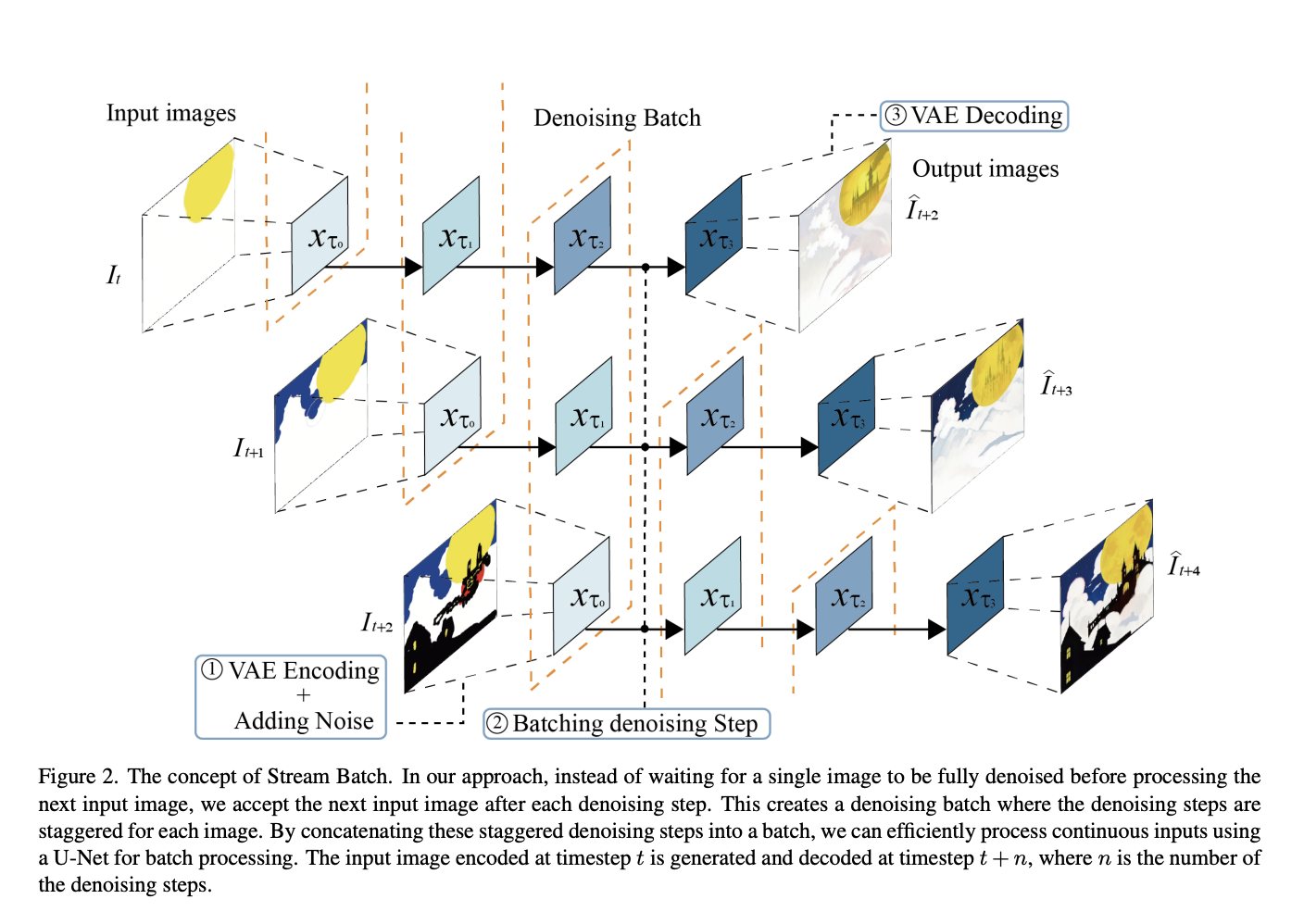
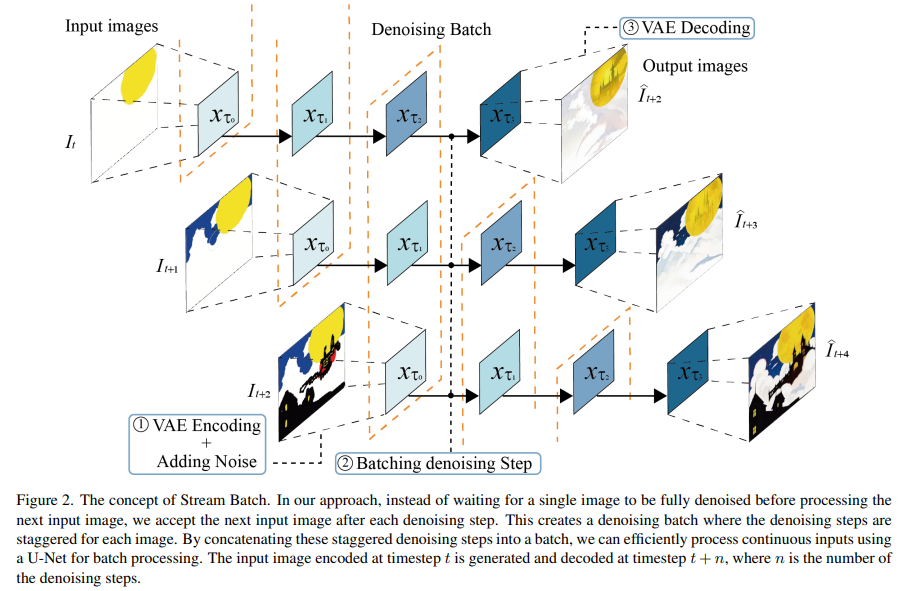
The use of diffusion models for interactive image generation is a burgeoning area of research. These models are lauded for creating high-quality images from various prompts and finding applications in digital art, virtual reality, and augmented reality. However, their real-time interaction capabilities are limited, particularly in dynamic environments like the Metaverse and video game graphics.
Researchers from UC Berkeley, the University of Tsukuba, International Christian University, Toyo University, Tokyo Institute of Technology, Tohoku University, and MIT address a significant challenge in interactive image generation with diffusion models. Traditional diffusion models excel at creating images from text or image prompts but need more real-time interactions. This inadequacy becomes particularly evident in scenarios requiring continuous input and high throughput, such as in the Metaverse, video game graphics, live streaming, and broadcasting. The sequential denoising process in these models results in low throughput, hindering their practical applicability in dynamic and interactive environments.
Prior efforts in enhancing high throughput and real-time capabilities have primarily focused on reducing the number of denoising iterations. This includes strategies like decreasing iterations from fifty to a few or even one, distilling multi-step diffusion models into fewer steps, and re-framing the diffusion process using ordinary neural Differential Equations. However, these methods are limited to individual model optimizations and don’t provide an overarching solution for pipeline efficiency.
The research introduces StreamDiffusion, a novel pipeline-level approach that enables real-time interactive image generation with high throughput. This solution fundamentally alters the diffusion process by switching from the conventional sequential denoising to a batching denoising process. The concept of StreamDiffusion revolves around eliminating the traditional wait-and-interact approach, thereby enabling fluid and high throughput streams.
StreamDiffusion incorporates several innovative components: Stream Batch for restructuring sequential denoising operations into batch processes, Residual Classifier-Free Guidance (RCFG) for enhanced image alignment, an input-output queuing system for efficient parallel processing, and a Stochastic Similarity Filter to optimize power consumption. The pipeline also employs pre-computation and model acceleration tools, such as TensorRT and a tiny autoencoder, to improve throughput and efficiency further.
The implementation of StreamDiffusion showcases remarkable improvements in throughput and energy efficiency. The pipeline achieves up to 91.07 frames per second for image generation tasks on a standard consumer-grade GPU, significantly outperforming existing methods. It demonstrates a substantially reduced GPU power consumption, making it a more sustainable and efficient solution for real-time interactive applications.
In conclusion, the research carried out can be put forth in the following points:
- StreamDiffusion marks a significant leap in interactive diffusion generation, addressing the critical need for high throughput in dynamic environments.
- Its innovative pipeline-level approach distinguishes it from existing methods focusing on individual model optimizations.
- Integrating batching, denoising, RCFG, and efficient parallel processing dramatically enhances real-time interaction capabilities.
- Thanks to its scalability and efficiency, its applicability extends to various high-demand sectors, including the Metaverse, video gaming, and live broadcasting.
- StreamDiffusion’s contribution lies in its technical prowess and its role as a model for future research and development in interactive diffusion generation.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.

