

Can LLMs talk SQL, SPARQL, Cypher, and MongoDB Query Language (MQL) equally well?
Are LLMs Better at Generating SQL, SPARQL, Cypher, or MongoDB Queries?Our NeurIPS’24 paper sheds light on this underinvestigated topic with a new and unique public dataset and benchmark.(Image by author)Many recent works have been focusing on how to generate SQL from a natural language question using an LLM. However, there is little understanding of how well LLMs can generate other database query languages in a direct comparison. To answer the question, we created a completely new dataset and benchmark of 10K question-query pairs covering four databases and query languages. We evaluated several relevant closed and open-source LLMs from OpenAI, Google, and Meta together with common in-context-learning (ICL) strategies. The corresponding paper “SM3-Text-to-Query: Synthetic Multi-Model Medical Text-to-Query Benchmark” [1] is published at NeurIPS 2024 in the Dataset and Benchmark track (https://arxiv.org/abs/2411.05521).All code and data are available at https://github.com/jf87/SM3-Text-to-Query to enable you to test your own Text-to-Query method across four query languages. But before we look at Text-to-Query, let’s first take a step back and examine the more common paradigm of Text-to-SQL.What is Text-to-SQL?Text-to-SQL (also called NL-to-SQL) systems translate the provided natural language question into a corresponding SQL query. SQL has served as a primary query language for structured data sources (relational model), offering a declarative interface for application developers to access information. Text-to-SQL systems thus aim to enable non-SQL expert users to access and fulfill their information needs by simply making their requests in natural language.Figure 1. Overview Text-to-SQL. Users ask questions in natural language, which are then translated to the corresponding SQL query. The query is executed against a relational database such as PostgreSQL, and the response is returned to the users. (Image by author)Text-to-SQL methods have recently increased in popularity and made substantial progress in terms of their generation capabilities. This can easily be seen from Text-to-SQL accuracies reaching 90% on the popular benchmark Spider (https://yale-lily.github.io/spider) and up to 74% on the more recent and more complex BIRD benchmark (https://bird-bench.github.io/). At the core of this success lie the advancements intransformer-based language models, from Bert [2] (340M parameters) and Bart [ 3 ] (148M parameters) to T5 [4 ] (3B parameters) to the advent of Large Language Models (LLMs), such as OpenAI’s GPT models, Anthropic Claude models or Meta’s LLaMA models (up to 100s of billions of parameters).Beyond Relational Databases: Document & Graph ModelWhile many structured data sources inside companies and organizations are indeed stored in a relational database and accessible through the SQL query language, there are other core database models (also often referred to as NoSQL) that come with their own benefits and drawbacks in terms of ease of data modeling, query performance, and query simplicity:Relational Database Model. Here, data is stored in tables (relations) with a fixed, hard-to-evolve schema that defines tables, columns, data types, and relationships. Each table consists of rows (records) and columns (attributes), where each row represents a unique instance of the entity described by the table (for example, a patient in a hospital), and each column represents a specific attribute of that entity. The relational model enforces data integrity through constraints such as primary keys (which uniquely identify each record) and foreign keys (which establish relationships between tables). Data is accessed through SQL. Popular relational databases include PostgreSQL, MySQL, and Oracle Database.Document Database Model. Here, data is stored in a document structure (hierarchical data model) with a flexible schema that is easy to evolve. Each document is typically represented in formats such as JSON or BSON, allowing for a rich representation of data with nested structures. Unlike relational databases, where data must conform to a predefined schema, document databases allow different documents within the same collection to have varying fields and structures, facilitating rapid development and iteration. This flexibility means that attributes can be added or removed without affecting other documents, making it suitable for applications where requirements change frequently. Popular document databases include MongoDB, CouchDB, and Amazon DocumentDB.Graph Database Model. Here, data is represented as nodes (entities) and edges (relationships) in a graph structure, allowing for the modeling of complex relationships and interconnected data. This model provides a flexible schema that can easily accommodate changes, as new nodes and relationships can be added without altering existing structures. Graph databases excel at handling queries involving relationships and traversals, making them ideal for applications such a

Are LLMs Better at Generating SQL, SPARQL, Cypher, or MongoDB Queries?
Our NeurIPS’24 paper sheds light on this underinvestigated topic with a new and unique public dataset and benchmark.

Many recent works have been focusing on how to generate SQL from a natural language question using an LLM. However, there is little understanding of how well LLMs can generate other database query languages in a direct comparison. To answer the question, we created a completely new dataset and benchmark of 10K question-query pairs covering four databases and query languages. We evaluated several relevant closed and open-source LLMs from OpenAI, Google, and Meta together with common in-context-learning (ICL) strategies. The corresponding paper “SM3-Text-to-Query: Synthetic Multi-Model Medical Text-to-Query Benchmark” [1] is published at NeurIPS 2024 in the Dataset and Benchmark track (https://arxiv.org/abs/2411.05521).
All code and data are available at https://github.com/jf87/SM3-Text-to-Query to enable you to test your own Text-to-Query method across four query languages. But before we look at Text-to-Query, let’s first take a step back and examine the more common paradigm of Text-to-SQL.
What is Text-to-SQL?
Text-to-SQL (also called NL-to-SQL) systems translate the provided natural language question into a corresponding SQL query. SQL has served as a primary query language for structured data sources (relational model), offering a declarative interface for application developers to access information. Text-to-SQL systems thus aim to enable non-SQL expert users to access and fulfill their information needs by simply making their requests in natural language.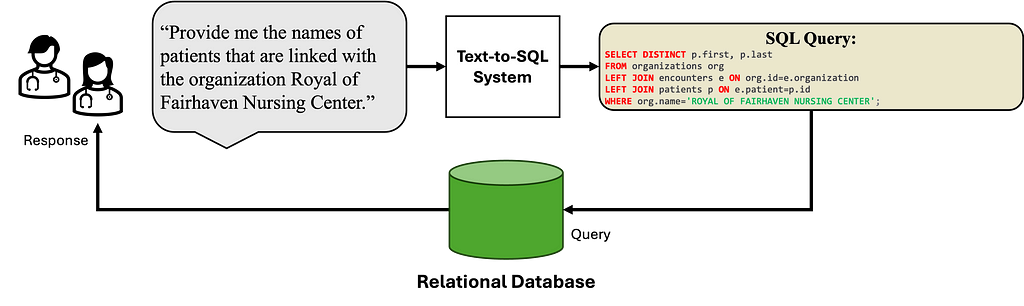
Text-to-SQL methods have recently increased in popularity and made substantial progress in terms of their generation capabilities. This can easily be seen from Text-to-SQL accuracies reaching 90% on the popular benchmark Spider (https://yale-lily.github.io/spider) and up to 74% on the more recent and more complex BIRD benchmark (https://bird-bench.github.io/). At the core of this success lie the advancements in
transformer-based language models, from Bert [2] (340M parameters) and Bart [ 3 ] (148M parameters) to T5 [4 ] (3B parameters) to the advent of Large Language Models (LLMs), such as OpenAI’s GPT models, Anthropic Claude models or Meta’s LLaMA models (up to 100s of billions of parameters).
Beyond Relational Databases: Document & Graph Model
While many structured data sources inside companies and organizations are indeed stored in a relational database and accessible through the SQL query language, there are other core database models (also often referred to as NoSQL) that come with their own benefits and drawbacks in terms of ease of data modeling, query performance, and query simplicity:
- Relational Database Model. Here, data is stored in tables (relations) with a fixed, hard-to-evolve schema that defines tables, columns, data types, and relationships. Each table consists of rows (records) and columns (attributes), where each row represents a unique instance of the entity described by the table (for example, a patient in a hospital), and each column represents a specific attribute of that entity. The relational model enforces data integrity through constraints such as primary keys (which uniquely identify each record) and foreign keys (which establish relationships between tables). Data is accessed through SQL. Popular relational databases include PostgreSQL, MySQL, and Oracle Database.
- Document Database Model. Here, data is stored in a document structure (hierarchical data model) with a flexible schema that is easy to evolve. Each document is typically represented in formats such as JSON or BSON, allowing for a rich representation of data with nested structures. Unlike relational databases, where data must conform to a predefined schema, document databases allow different documents within the same collection to have varying fields and structures, facilitating rapid development and iteration. This flexibility means that attributes can be added or removed without affecting other documents, making it suitable for applications where requirements change frequently. Popular document databases include MongoDB, CouchDB, and Amazon DocumentDB.
- Graph Database Model. Here, data is represented as nodes (entities) and edges (relationships) in a graph structure, allowing for the modeling of complex relationships and interconnected data. This model provides a flexible schema that can easily accommodate changes, as new nodes and relationships can be added without altering existing structures. Graph databases excel at handling queries involving relationships and traversals, making them ideal for applications such as social networks, recommendation systems, and fraud detection. Popular graph databases include Neo4j, Amazon Neptune, and ArangoDB.
From Text-to-SQL to Text-to-Query
The choice of database and the underlying core data model (relational, document, graph) has a large impact on read/write performance and query complexity. For example, the graph model naturally represents many-to-many relationships, such as connections between patients, doctors, treatments, and medical conditions. In contrast, relational databases require potentially expensive join operations and complex queries. Document databases have only rudimentary support for many-to-many relationships and aim at scenarios where data is not highly interconnected and stored in collections of documents with a flexible schema.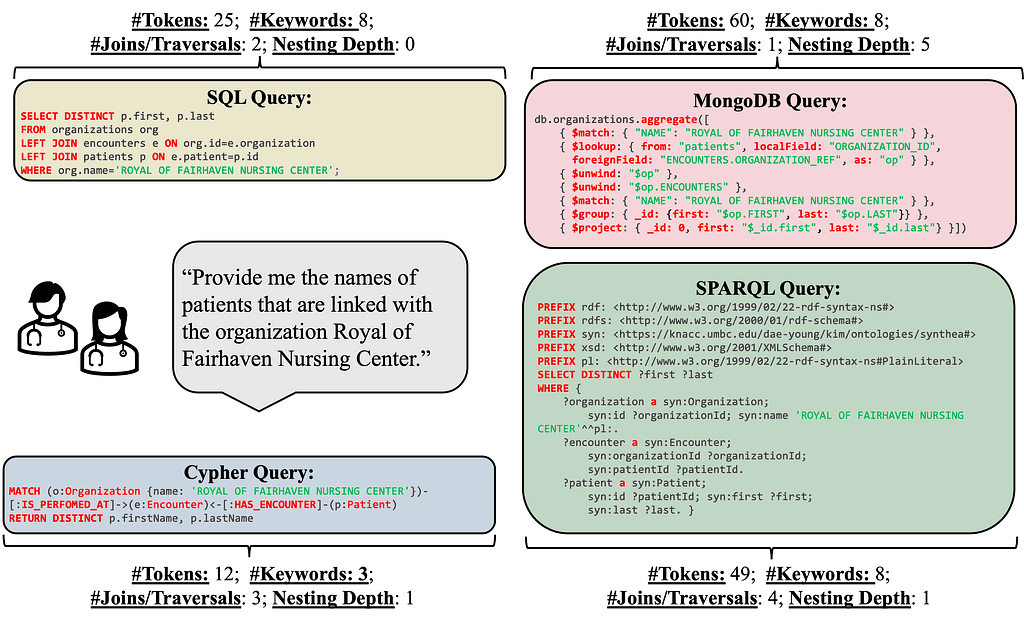
While these differences have been a known fact in database research and industry, their implications for the growing number of Text-to-Query systems have surprisingly not been investigated so far.
SM3-Text-to-Query Benchmark
SM3-Text-to-Query is a new dataset and benchmark that enables the evaluation across four query languages (SQL, MongoDB Query Language, Cypher, and SPARQL) and three data models (relational, graph, document).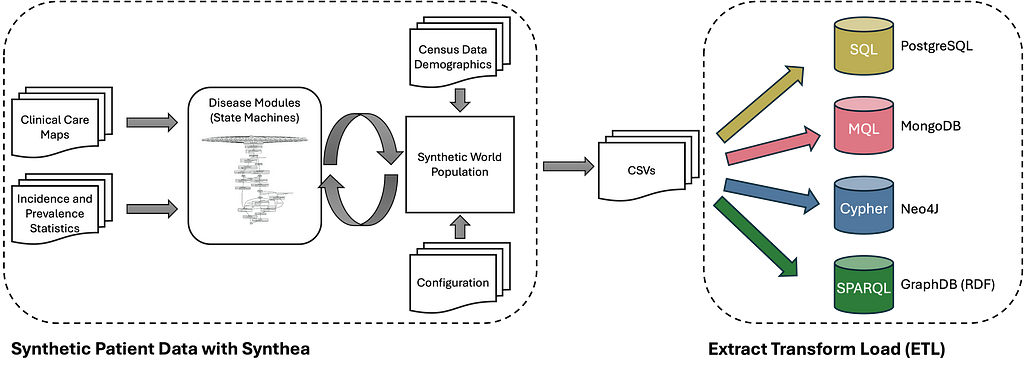
SM3-Text-to-Query is constructed from synthetic patient data created with Synthea. Synthea is an open-source synthetic patient generator that produces realistic electronic health record (EHR) data. It simulates patients' medical histories over time, including various demographics, diseases, medications, and treatments. This created data is then transformed and loaded into four different database systems: PostgreSQL, MongoDB, Neo4J, and GraphDB (RDF).
Based on a set of > 400 manually created template questions and the generated data, 10K question-query pairs are generated for each of the four query languages (SQL, MQL, Cypher, and SPARQL). However, based on the synthetic data generation process, adding additional template questions or generating your own patient data is also easily possible (for example, adapted to a specific region or in another language). It would even be possible to construct a (private) dataset with actual patient data.
Text-to-Query Results
So, how do current LLMs perform in the generation across the four query languages? There are three main lessons that we can learn from the reported results.
Lesson 01: Schema information helps for all query languages but not equally well.
Schema information helps for all query languages, but its effectiveness varies significantly. Models leveraging schema information outperform those that don’t — even more in one-shot scenarios where accuracy plummets otherwise. For SQL, Cypher, and MQL, it can more than double the performance. However, SPARQL shows only a small improvement. This suggests that LLMs may already be familiar with the underlying schema (SNOMED CT, https://www.snomed.org), which is a common medical ontology.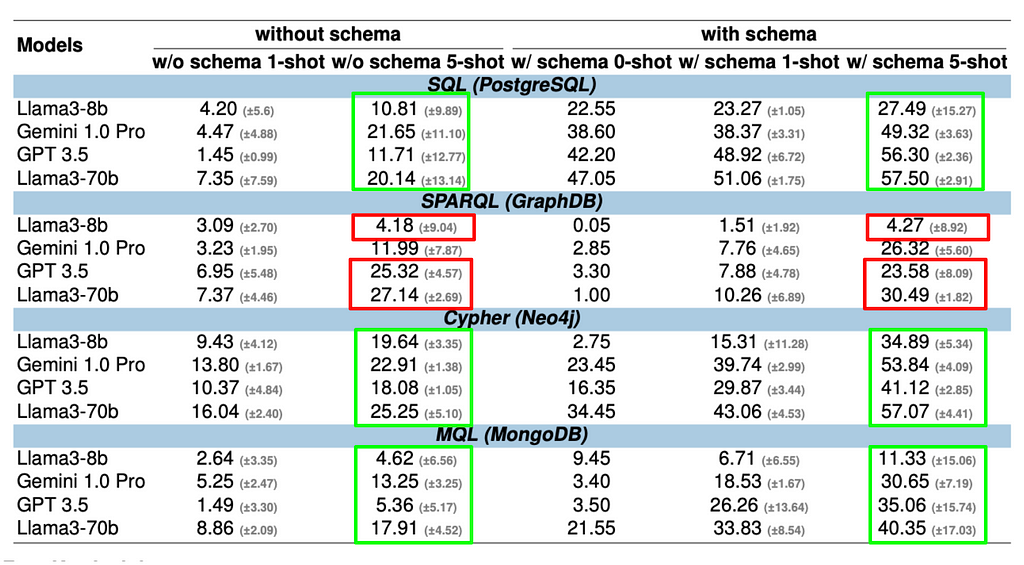
Lesson 02: Adding examples improves accuracy through in-context learning (ICL) for all LLMs and query languages; however, the rate of improvement varies greatly across query languages.
Examples enhance accuracy through in-context learning (ICL) across all LLMs and query languages. However, the degree of improvement varies greatly. For SQL, the most popular query language, larger LLMs (GPT-3.5, Llama3–70b, Gemini 1.0) already show a solid baseline accuracy of around 40% with zero-shot schema input, gaining only about 10% points with five-shot examples. However, the models struggle significantly with less common query languages such as SPARQL and MQL without examples. For instance, SPARQL’s zero-shot accuracy is below 4%. Still, with five-shot examples, it skyrockets to 30%, demonstrating that ICL supports models to generate more accurate queries when provided with relevant examples.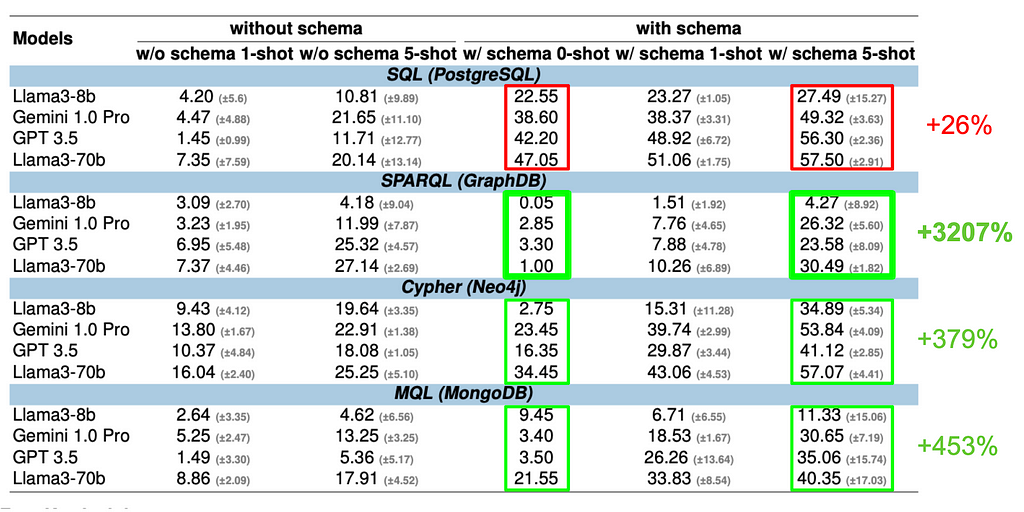
Lesson 03: LLMs have varying levels of training knowledge across different query languages
LLMs exhibit differing levels of proficiency across query languages. This is likely rooted in their training data sources. An analysis of Stack Overflow posts supports this assumption. There is a big contrast in the post-frequency for the different query languages:
- [SQL]: 673K posts
- [SPARQL]: 6K posts
- [MongoDB, MQL]: 176K posts
- [Cypher, Neo4J]: 33K posts
This directly correlates with the zero-shot accuracy results, where SQL leads with the best model accuracy of 47.05%, followed by Cypher and MQL at 34.45% and 21.55%. SPARQL achieves just 3.3%. These findings align with existing research [5], indicating that the frequency and recency of questions on platforms like Stack Overflow significantly impact LLM performance. An intriguing exception arises with MQL, which underperforms compared to Cypher, likely due to the complexity and length of MQL queries.
Conclusion
SM3-Text-to-query is the first dataset that targets the cross-query language and cross-database model evaluation of the increasing number of Text-to-Query systems that are fueled by rapid progress in LLMs. Existing works have mainly focused on SQL. Other important query languages are underinvestigated. This new dataset and benchmark allow a direct comparison of four relevant query languages for the first time, making it a valuable resource for both researchers and practitioners who want to design and implement Text-to-Query systems.
The initial results already provide many interesting insights, and I encourage you to check out the full paper [1].
Try it yourself
All code and data are open-sourced on https://github.com/jf87/SM3-Text-to-Query. Contributions are welcome. In a follow-up post, we will provide some hands-on instructions on how to deploy the different databases and try out your own Text-to-Query method.
[1] Sivasubramaniam, Sithursan, Cedric Osei-Akoto, Yi Zhang, Kurt Stockinger, and Jonathan Fuerst. “SM3-Text-to-Query: Synthetic Multi-Model Medical Text-to-Query Benchmark.” In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
[2] Devlin, Jacob. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[3]Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
[4] Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. “Exploring the limits of transfer learning with a unified text-to-text transformer.” Journal of machine learning research 21, no. 140 (2020): 1–67.
[5] Kabir, Samia, David N. Udo-Imeh, Bonan Kou, and Tianyi Zhang. “Is stack overflow obsolete? an empirical study of the characteristics of chatgpt answers to stack overflow questions.” In Proceedings of the CHI Conference on Human Factors in Computing Systems, pp. 1–17. 2024.
Can LLMs talk SQL, SPARQL, Cypher, and MongoDB Query Language (MQL) equally well? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.










