

LLMs for Coding in 2024: Price, Performance, and the Battle for the Best
Evaluating the current LLM landscape based both benchmarks and real-world insights to help you make informed choices.Image generated by Flux.1 - SchnellThe landscape of Large Language Models (LLMs) for coding has never been more competitive. With major players like Alibaba, Anthropic, Google, Meta, Mistral, OpenAI, and xAI all offering their own models, developers have more options than ever before.But how can you choose the best LLM for your coding use case?In this post, I provide an in-depth analysis of the top LLMs available through public APIs. I focus on their performance in coding tasks as measured by benchmarks like HumanEval, and their observed real-world performance as reflected by their respective Elo scores.Whether you’re working on a personal project or integrating AI into your development workflow, understanding the strengths and weaknesses of these models will help you make a more informed decision.Disclaimer: challenges when comparing LLMsComparing LLMs is hard. Models frequently receive updates that have a significant influence on their performance — say for example OpenAI’s updates from GPT-4 to GPT-4-turbo to GPT-4o to the o1 models. However, even minor updates have an effect — GPT-4o, for example, received already 3 updates after its release on May 13th!Additionally, the stochastic nature of these models means their performance can vary across different runs, leading to inconsistent results in studies. Finally, some companies may tailor benchmarks and configurations — such as specific Chain-of-Thought techniques — to showcase their models in the best light, which skew comparisons and mislead conclusions.Conclusion: comparing LLM performance is hard.This post represents a best-effort comparison of various models for coding tasks based on the information available. I welcome any feedback to improve the accuracy of this analysis!Evaluating LLMs: HumanEval and Elo scoresAs hinted at in the disclaimer above, to properly understand how LLMs perform in coding tasks, it’s advisable to evaluate them from multiple perspectives.Benchmarking through HumanEvalInitially, I tried to aggregate results from several benchmarks to see which model comes out on top. However, this approach had as core problem: different models use different benchmarks and configurations. Only one benchmark seemed to be the default for evaluating coding performance: HumanEval. This is a benchmark dataset consisting of human-written coding problems, evaluating a model’s ability to generate correct and functional code based on specified requirements. By assessing code completion and problem-solving skills, HumanEval serves as a standard measure for coding proficiency in LLMs.The voice of the people through Elo scoresWhile benchmarks give a good view of a model’s performance, they should also be taken with a grain of salt. Given the vast amounts of data LLMs are trained on, some of a benchmark’s content (or highly similar content) might be part of that training. That’s why it’s beneficial to also evaluate models based on how well they perform as judged by humans. Elo ratings, such as those from Chatbot Arena (coding only), do just that. These are scores derived from head-to-head comparisons of LLMs in coding tasks, evaluated by human judges. Models are pitted against each other, and their Elo scores are adjusted based on wins and losses in these pairwise matches. An Elo score shows a model’s relative performance compared to others in the pool, with higher scores indicating better performance. For example, a difference of 100 Elo points suggests that the higher-rated model is expected to win about 64% of the time against the lower-rated model.Current state of model performanceNow, let’s examine how these models perform when we compare their HumanEval scores with their Elo ratings. The following image illustrates the current coding landscape for LLMs, where the models are clustered by the companies that created them. Each company’s best performing model is annotated.Figure 1: Elo score by HumanEval — colored by company. X- and y-axis ticks show all models released by each company, with the best performing model shown in bold.OpenAI’s models are at the top of both metrics, demonstrating their superior capability in solving coding tasks. The top OpenAI model outperforms the best non-OpenAI model — Anthropic’s Claude Sonnet 3.5 — by 46 Elo points , with an expected win rate of 56.6% in head-to-head coding tasks , and a 3.9% difference in HumanEval. While this difference isn’t overwhelming, it shows that OpenAI still has the edge. Interestingly, the best model is o1-mini, which scores higher than the larger o1 by 10 Elo points and 2.5% in HumanEval.Conclusion: OpenAI continues to dominate, positioning themselves at the top in benchmark performance and real-world usage. Remarkably, o1-mini is the best performing model, outperforming its larger counterpart o1.Other companies follow closely behind and seem to exist within the same “perform
Evaluating the current LLM landscape based both benchmarks and real-world insights to help you make informed choices.

The landscape of Large Language Models (LLMs) for coding has never been more competitive. With major players like Alibaba, Anthropic, Google, Meta, Mistral, OpenAI, and xAI all offering their own models, developers have more options than ever before.
But how can you choose the best LLM for your coding use case?
In this post, I provide an in-depth analysis of the top LLMs available through public APIs. I focus on their performance in coding tasks as measured by benchmarks like HumanEval, and their observed real-world performance as reflected by their respective Elo scores.
Whether you’re working on a personal project or integrating AI into your development workflow, understanding the strengths and weaknesses of these models will help you make a more informed decision.
Disclaimer: challenges when comparing LLMs
Comparing LLMs is hard. Models frequently receive updates that have a significant influence on their performance — say for example OpenAI’s updates from GPT-4 to GPT-4-turbo to GPT-4o to the o1 models. However, even minor updates have an effect — GPT-4o, for example, received already 3 updates after its release on May 13th!
Additionally, the stochastic nature of these models means their performance can vary across different runs, leading to inconsistent results in studies. Finally, some companies may tailor benchmarks and configurations — such as specific Chain-of-Thought techniques — to showcase their models in the best light, which skew comparisons and mislead conclusions.
Conclusion: comparing LLM performance is hard.
This post represents a best-effort comparison of various models for coding tasks based on the information available. I welcome any feedback to improve the accuracy of this analysis!
Evaluating LLMs: HumanEval and Elo scores
As hinted at in the disclaimer above, to properly understand how LLMs perform in coding tasks, it’s advisable to evaluate them from multiple perspectives.
Benchmarking through HumanEval
Initially, I tried to aggregate results from several benchmarks to see which model comes out on top. However, this approach had as core problem: different models use different benchmarks and configurations. Only one benchmark seemed to be the default for evaluating coding performance: HumanEval. This is a benchmark dataset consisting of human-written coding problems, evaluating a model’s ability to generate correct and functional code based on specified requirements. By assessing code completion and problem-solving skills, HumanEval serves as a standard measure for coding proficiency in LLMs.
The voice of the people through Elo scores
While benchmarks give a good view of a model’s performance, they should also be taken with a grain of salt. Given the vast amounts of data LLMs are trained on, some of a benchmark’s content (or highly similar content) might be part of that training. That’s why it’s beneficial to also evaluate models based on how well they perform as judged by humans. Elo ratings, such as those from Chatbot Arena (coding only), do just that. These are scores derived from head-to-head comparisons of LLMs in coding tasks, evaluated by human judges. Models are pitted against each other, and their Elo scores are adjusted based on wins and losses in these pairwise matches. An Elo score shows a model’s relative performance compared to others in the pool, with higher scores indicating better performance. For example, a difference of 100 Elo points suggests that the higher-rated model is expected to win about 64% of the time against the lower-rated model.
Current state of model performance
Now, let’s examine how these models perform when we compare their HumanEval scores with their Elo ratings. The following image illustrates the current coding landscape for LLMs, where the models are clustered by the companies that created them. Each company’s best performing model is annotated.
OpenAI’s models are at the top of both metrics, demonstrating their superior capability in solving coding tasks. The top OpenAI model outperforms the best non-OpenAI model — Anthropic’s Claude Sonnet 3.5 — by 46 Elo points , with an expected win rate of 56.6% in head-to-head coding tasks , and a 3.9% difference in HumanEval. While this difference isn’t overwhelming, it shows that OpenAI still has the edge. Interestingly, the best model is o1-mini, which scores higher than the larger o1 by 10 Elo points and 2.5% in HumanEval.
Conclusion: OpenAI continues to dominate, positioning themselves at the top in benchmark performance and real-world usage. Remarkably, o1-mini is the best performing model, outperforming its larger counterpart o1.
Other companies follow closely behind and seem to exist within the same “performance ballpark”. To provide a clearer sense of the difference in model performance, the following figure shows the win probabilities of each company’s best model — as indicated by their Elo rating.
Mismatch between benchmark results and real-world performance
From Figure 1, one thing that stands out is the misalignment between HumanEval (benchmark) and the Elo scores (real-world performance). Some models — like Mistral’s Mistral Large — have significantly better HumanEval scores relative to their Elo rating. Other models — like Google’s Gemini 1.5 Pro — have significantly better Elo ratings relative to the HumanEval score they obtain.
It’s hard to know when to trust benchmarks, as the benchmark data might as well be included in the model’s training dataset. This can lead to (overfitted) models that memorize and repeat the answer to a coding question, rather than understand and actually solve the problem.
Similarly, It’s also problematic to take the Elo ratings as a ground truth, given that these are scores obtained by a crowdsourcing effort. By doing so, you add a human bias to the scoring, favoring models that output in a specific style, take a specific approach, … over others, which does not always align with a factually better model.
Conclusion: better benchmark results don’t always reflect better real-world performance. It’s advised to look at both independently.
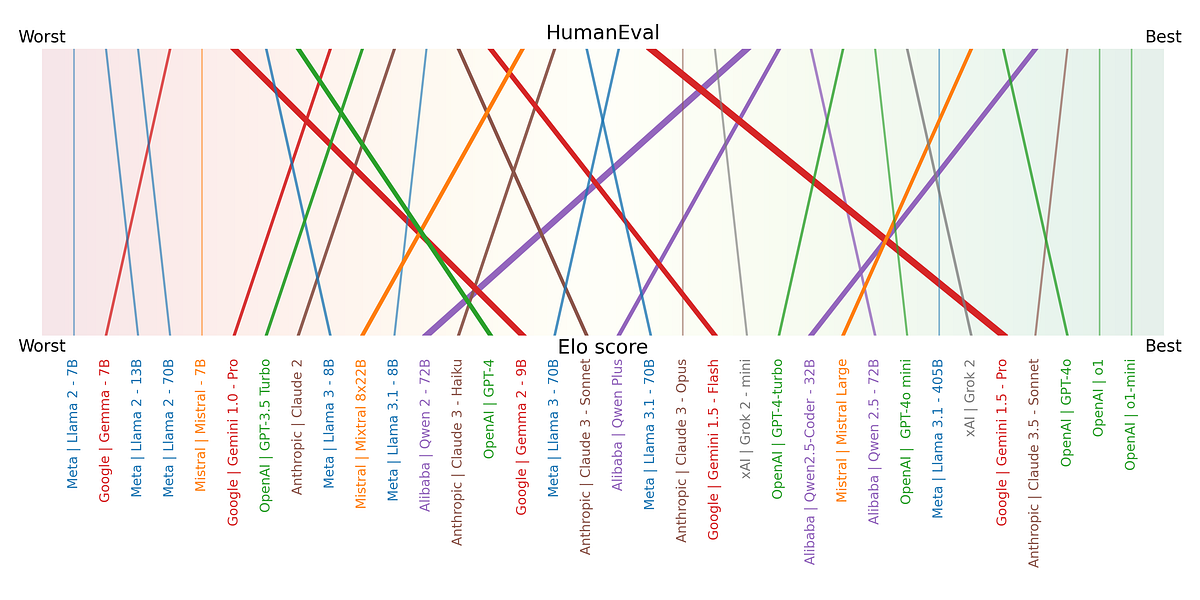
The following image shows the disagreement between HumanEval and Elo scores. All models are sorted based on their respective scores, ignoring “how much better” one model is compared to another for simplicity. It shows visually which models perform better on benchmarks than in real life and vice-versa.
Figure 4 further highlights the difference between benchmarking and real-world performance by simplifying the comparison even further. Here, the figure shows the relative difference in rank, indicating when a model is likely overfitting the benchmark or performs better than reported. Some interesting conclusions can be drawn here:
- Overfitting on benchmark: Alibaba and Mistral both stick out for systematically creating models that perform better on benchmarks than in real life. Their most recent models, Alibaba’s Qwen 2.5 Coder (-20.0%) and Mistral’s Mistral Large (-11.5%) follow this pattern, too.
- Better than reported: Google stands out for producing models that perform significantly better than reported, with its newest Gemini 1.5 Pro model on top with a difference of +31.5%. Their focus on “honest training and evaluation” is evident in their model reporting and the dicision to develop their own Natural2Code benchmark instead of using HumanEval. “Natural2Code is a code generation benchmark across Python, Java, C++, JS, Go . Held out dataset HumanEval-like, not leaked on the web” ~ Google in the Gimini 1.5 release.
- Well balanced: It’s very interesting and particular how well and consistently Meta nails the balance between benchmark a real-world performance. Of course, given that the figure displays rank over score, this stability also depends on the performance of other models.

Conclusion: Alibaba and Mistral tend to create models that overfit on the benchmark data.
Conclusion: Google’s models are underrated in benchmark results, due to their focus on fair training and evaluation.
Balancing performance and price: the models that provide the best bang for buck
When choosing an LLM as your coding companion, performance isn’t the only factor to consider. Another important dimension to consider is price. This section re-evaluates the different LLMs and compares how well they fare when evaluated on performance — as indicated by their Elo rating — and price.
Before starting the comparison, it’s worth noting of the odd one out: Meta. Meta’s Llama models are open-source and not hosted by Meta themselves. However, given their popularity, I include them. The price attached to these models is the best pay-as-you-go price offered by the big three cloud vendors (Google, Microsoft, Amazon) — which usually comes down to AWS’s price.
Figure 5 compares the different models and shows the Pareto front. Elo ratings are used to represent model performance, this seemed the best choice given it’s evaluated by humans and doesn’t include an overfitting bias. Next, the pay-as-you-go API price is used with the displayed price being the average of input- and output-token cost for a total of one million generated tokens.
The Pareto front is made up of models coming from only two companies: OpenAI and Google. As mentioned in the previous sections, OpenAI’s models dominate in performance, and they appear to be fairly priced too. Meanwhile, Google seems to focus on lighter weight — thus cheaper — models that still perform well. This makes sense, given their focus on on-device LLM use-cases which hold great strategic value for their mobile operating system (Android).
Conclusion: the Pareto front is made up of models coming from either OpenAI (high performance) or Google (good value for money).
The next figure shows a similar trend when using HumanEval instead of Elo scores to represent coding performance. Some observations:
- Anthropic’s Claude 3.5 Haiku is the only notable addition, as this model does not yet have an Elo rating. Could it be a potential contender for middle-priced, high-performance models?
- The differences for Google’s Gemini 1.5 Pro and Mistral’s Mistral Large are explained in the previous section that compared HumanEval scores with Elo ratings.
- Given that Google’s Gemini 1.5 Flash 8B does not have a HumanEval score, it is excluded from this figure.

Shifting through the data: additional insights and trends
To conclude, I will discuss some extra insights worth noting in the current LLM (coding) landscape. This section explores three key observations: the steady improvement of models over time, the continued dominance of proprietary models, and the significant impact even minor model updates can have. All the observations stem from the Elo rating by price comparison shown in Figure 5.
Models are getting better and cheaper
The following figure illustrates how new models continue to achieve higher accuracy while simultaneously driving down costs. It’s remarkable to see how three time segments — 2023 and before, H1 of 2024, and H2 of 2024 — each define their own Pareto front and occupy almost completely distinct segments. Curious to see how this will continue to progress in 2025!
Conclusion: models get systematically better and cheaper, a trend observed with almost every new model release.
Proprietary models remain in power
The following image shows which of the analyzed models are proprietary and which are open-source. We see that proprietary models continue to dominate the LLM coding landscape. The Pareto front is still driven by these “closed-source” models, both on the high-performing and low-cost ends.
However, open-source models are closing the gap. It’s interesting to see, though, that for each open-source model, there is a proprietary model with the same predictive performance that is significantly cheaper. This suggests that the proprietary are either more lighterweight or better optimized, thus requiring less computational power — though this is just a personal hunch.
Conclusion: proprietary models continue to hold the performance-cost Pareto front.
Even minor model updates have an effect
The following and final image illustrates how even minor updates to the same models can have an impact. Most often, these updates bring a performance boost, improving the models gradually over time without a major release. Occasionally though, a model’s performance might drop for coding tasks following a minor update, but this is almost always accompanied by a reduction in price. This is likely because the models were optimized in some way, such as through quantization or pruning parts of their network.
Conclusion: minor model updates almost always improve performance or push down cost.
Conclusion: key takeaways of LLMs for coding
The LLM landscape for coding is rapidly evolving, with newer models regularly pushing the Pareto front toward better-performing and/or cheaper options. Developers must stay informed about the latest models to identify those that offer the best capabilities within their budget. Recognizing the misalignment between real-world results and benchmarks is essential to making informed decisions. By carefully weighing performance against cost, developers can choose the tools that best meet their needs and stay ahead in this dynamic field.
Here’s a quick overview of all the conclusions made in this post:
- Comparing LLM performance is hard.
- OpenAI continues to dominate, positioning themselves at the top in benchmark performance and real-world usage. Remarkably, o1-mini is the best performing model, outperforming its larger counterpart o1.
- Better benchmark results don’t always reflect better real-world performance. It’s advised to look at both independently.
- Alibaba and Mistral tend to create models that overfit on the benchmark data.
- Google’s models are underrated in benchmark results, due to their focus on fair training and evaluation.
- The Pareto front is made up of models coming from either OpenAI (high performance) or Google (good value for money).
- Models get systematically better and cheaper, a trend observed with almost every new model release.
- Proprietary models continue to hold the performance-cost Pareto front.
- Minor model updates almost always improve performance or push down cost.
Found this useful? Feel free to follow me on LinkedIn to see my next explorations!
The images shown in this article were created by myself, the author, unless specified otherwise.
LLMs for Coding in 2024: Price, Performance, and the Battle for the Best was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.










