

Gen-AI Safety Landscape: A Guide to the Mitigation Stack for Text-to-Image Models
No Wild West for AI: A tour of the safety components that tame T2I modelsUnderstanding Text-to-Image AI Model Capabilities and RisksText-to-Image models (T2I) are AI systems that generate images based on text prompt descriptions. Latent Diffusion Models (LDM) are emerging as one of the most popular architectures for image generation. LDMs first compress images into a “latent space”, which is a compressed, simplified representation of the core information needed to represent an image without all the detailed pixel data in fewer dimensions. The model starts with random noise in this latent space and gradually refines it into a clear image through a process called diffusion, guided by the input text. LDMs are versatile and are capable not only of generating text-to-image outputs but also has capabilities like inpainting, which allows users to edit specific parts of an existing image by simply describing the desired changes. For example, you can remove an object from a photo or add new elements seamlessly, all through text commands.These capabilities pose significant safety risks that need to be carefully managed. The generated image could include explicit or inappropriate content, either in direct response to explicit prompts or unintentionally, even when the input prompt is harmless — for example, a request for images of person smoking might mistakenly produce images of an underage kid smoking. For inpainting capability, which allows users to alter images by uploading their own, there is a freedom to modify images of people that surpasses traditional photo editing tools in speed, scale, and efficiency, making it more accessible but also potentially more dangerous. It can be used to alter images in ways that can be harmful, such as changing someone’s appearance, removing clothing or modifying contextual elements like clothing or food items in religiously sensitive ways.Safety mitigation stackGiven the potential risks tied to image generation and inpainting capabilities, it is necessary to establish a robust safety mitigation stack across different stages of the model’s lifecycle. This involves implementing protections during pre-training, fine-tuning, and post-training phases, such as applying safety filters to both input prompts and generated images or utilizing a multimodal classifier that evaluates both input text and output images simultaneously.Pre-training and fine-tuning stages must incorporate ethical considerations and bias mitigation to ensure that the foundational models do not perpetuate harmful stereotypes, bias or generate inappropriate content. Once the safety fine-tuned foundation model is deployed to production, an input prompt classifier is essential to filter out explicit or harmful requests before any image generation occurs, preventing the model from processing unsafe inputs. Similarly, an output image classifier or a multimodal classifier can analyze the generated images to detect and flag any inappropriate or unintended image before it reaches the user.This layered approach ensures multiple checkpoints throughout the process, significantly reducing the risk of harmful outputs and ensuring image generation technology is used responsibly.Safety mitigation stack. Image by AuthorPre-training mitigationsT2I models are trained on pairs of images and their corresponding captions. Pairs are drawn from a combination of publicly available sources and sources that are licensed.Mitigations on training dataT2I models are trained on billion-sized datasets of images scraped off the internet. Research [1] has shown that datasets of Image-Alt-text pairs like LION-400M containtroublesome and explicit images and text pairs of rape, pornography, malign stereotypes, racist and ethnic slurs, and other extremely problematic content.Most models have a pre-training step to filter out such harmful content from the training data. DALL·E 2 [2] specifically mentions that explicit content including graphic sexual and violent content as well as images of some hate symbols have explicitly been filtered out. However studies have shown that filtering out sexual content exacerbates biases in the training data. Specifically, filtering of sexual content reduced the quantity of generated images of women in general because the images of women were disproportionately represented in filtered sexual imagery. Several approaches like rebalancing the dataset using synthetic data generation or re-weighting the filtered dataset so that its distribution better matched the distribution of unfiltered images have been taken to mitigate the amplification of bias issue [2].At this stage, it is also essential to consider privacy mitigations to ensure that no personal, sensitive, or identifiable information is included in the data used to train the model. Several techniques can be applied — anonymization can be used to remove or obfuscate any personal identifiers (names, addresses, faces), differential privacy (noise addition, subsampling a
No Wild West for AI: A tour of the safety components that tame T2I models
Understanding Text-to-Image AI Model Capabilities and Risks
Text-to-Image models (T2I) are AI systems that generate images based on text prompt descriptions. Latent Diffusion Models (LDM) are emerging as one of the most popular architectures for image generation. LDMs first compress images into a “latent space”, which is a compressed, simplified representation of the core information needed to represent an image without all the detailed pixel data in fewer dimensions. The model starts with random noise in this latent space and gradually refines it into a clear image through a process called diffusion, guided by the input text. LDMs are versatile and are capable not only of generating text-to-image outputs but also has capabilities like inpainting, which allows users to edit specific parts of an existing image by simply describing the desired changes. For example, you can remove an object from a photo or add new elements seamlessly, all through text commands.
These capabilities pose significant safety risks that need to be carefully managed. The generated image could include explicit or inappropriate content, either in direct response to explicit prompts or unintentionally, even when the input prompt is harmless — for example, a request for images of person smoking might mistakenly produce images of an underage kid smoking. For inpainting capability, which allows users to alter images by uploading their own, there is a freedom to modify images of people that surpasses traditional photo editing tools in speed, scale, and efficiency, making it more accessible but also potentially more dangerous. It can be used to alter images in ways that can be harmful, such as changing someone’s appearance, removing clothing or modifying contextual elements like clothing or food items in religiously sensitive ways.
Safety mitigation stack
Given the potential risks tied to image generation and inpainting capabilities, it is necessary to establish a robust safety mitigation stack across different stages of the model’s lifecycle. This involves implementing protections during pre-training, fine-tuning, and post-training phases, such as applying safety filters to both input prompts and generated images or utilizing a multimodal classifier that evaluates both input text and output images simultaneously.
Pre-training and fine-tuning stages must incorporate ethical considerations and bias mitigation to ensure that the foundational models do not perpetuate harmful stereotypes, bias or generate inappropriate content. Once the safety fine-tuned foundation model is deployed to production, an input prompt classifier is essential to filter out explicit or harmful requests before any image generation occurs, preventing the model from processing unsafe inputs. Similarly, an output image classifier or a multimodal classifier can analyze the generated images to detect and flag any inappropriate or unintended image before it reaches the user.
This layered approach ensures multiple checkpoints throughout the process, significantly reducing the risk of harmful outputs and ensuring image generation technology is used responsibly.
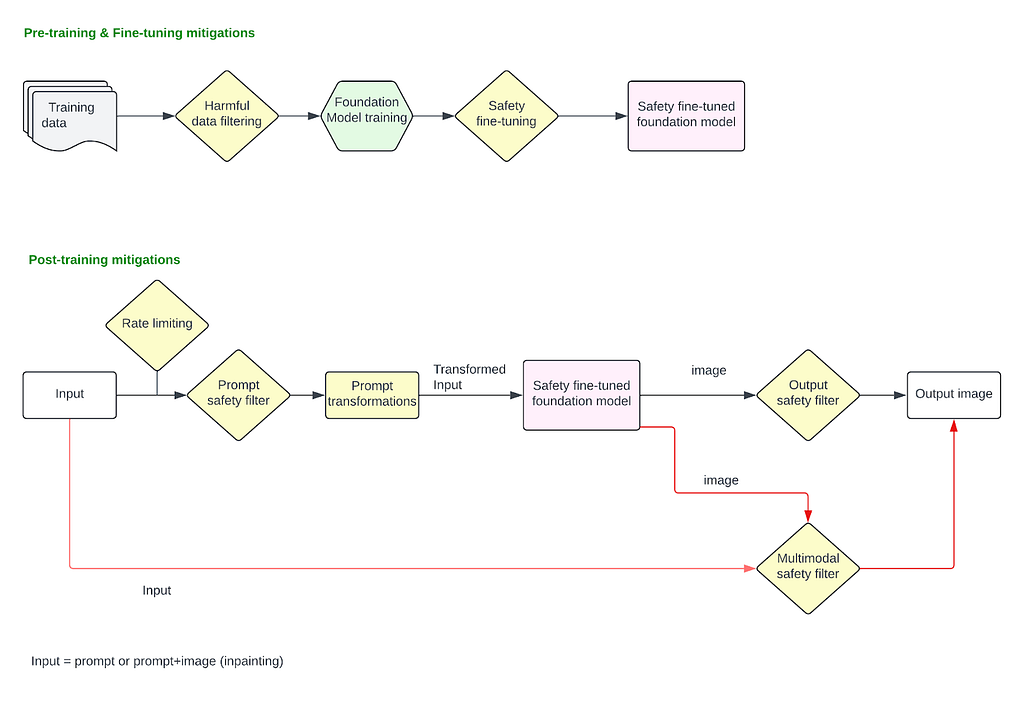
Pre-training mitigations
T2I models are trained on pairs of images and their corresponding captions. Pairs are drawn from a combination of publicly available sources and sources that are licensed.
Mitigations on training data
T2I models are trained on billion-sized datasets of images scraped off the internet. Research [1] has shown that datasets of Image-Alt-text pairs like LION-400M contain
troublesome and explicit images and text pairs of rape, pornography, malign stereotypes, racist and ethnic slurs, and other extremely problematic content.
Most models have a pre-training step to filter out such harmful content from the training data. DALL·E 2 [2] specifically mentions that explicit content including graphic sexual and violent content as well as images of some hate symbols have explicitly been filtered out. However studies have shown that filtering out sexual content exacerbates biases in the training data. Specifically, filtering of sexual content reduced the quantity of generated images of women in general because the images of women were disproportionately represented in filtered sexual imagery. Several approaches like rebalancing the dataset using synthetic data generation or re-weighting the filtered dataset so that its distribution better matched the distribution of unfiltered images have been taken to mitigate the amplification of bias issue [2].
At this stage, it is also essential to consider privacy mitigations to ensure that no personal, sensitive, or identifiable information is included in the data used to train the model. Several techniques can be applied — anonymization can be used to remove or obfuscate any personal identifiers (names, addresses, faces), differential privacy (noise addition, subsampling a person’s data to remove overfitting) to ensure that individual data points cannot be reverse-engineered from the model, and filtering out any data that contains confidential or proprietary information.
Fine-tuning the foundation model for safety
LDMs inherently are known to have a range of safety issues (bias, stereotypes, etc.) as well as the lack of prompt alignment in certain high-risk areas. These are “unintentional harms” where users give a perfectly benign prompt but the LDM generates a harmful response. Some examples are unintended sexualization, where casual prompts like “woman dressed for a date” can generate a sexualized image. Or, issues caused by lack of prompt alignment as shown in example below, where the midjourney model is incapable of generating a wife in non-Indian attire for Indian men, whereas for white men, it correctly generates a wife of different ethnicities and in different attires.





There is also a large area of risk as documented in [4] where marginalized groups are associated with harmful connotations reinforcing societal hateful stereotypes. For example, representation of demographic groups that conflates humans with animals or mythological creatures (such as black people as monkeys or other primates), conflating humans with food or objects (like associating people with disabilities and vegetables) or associating demographic groups with negative semantic concepts (such as terrorism with muslim people).
Problematic associations like these between groups of people and concepts reflect long-standing negative narratives about the group. If a generative AI model learns problematic associations from existing data, it may reproduce them in content that is generates [4].

There are several ways to fine-tune the LLMs. According to [6], one common approach is called Supervised Fine-Tuning (SFT). This involves taking a pre-trained model and further training it with a dataset that includes pairs of inputs and desired outputs. The model adjusts it’s parameters by learning to better match these expected responses.
Typically, fine-tuning involves two phases: SFT to establish a base model, followed by RLHF for enhanced performance. SFT involves imitating high-quality demonstration data, while RLHF refines LLMs through preference feedback.
RLHF can be done in two ways, reward-based or reward-free methods. In reward-based method, we first train a reward model using preference data. This model then guides online Reinforcement Learning algorithms like PPO. Reward-free methods are simpler, directly training the models on preference or ranking data to understand what humans prefer. Among these reward-free methods, DPO has demonstrated strong performances and become popular in the community. Diffusion DPO can be used to steer the model away from problematic depictions towards more desirable alternatives. The tricky part of this process is not training itself, but data curation. For each risk, we need a collection of hundreds or thousands of prompts, and for each prompt, a desirable and undesirable image pair. The desirable example should ideally be a perfect depiction for that prompt, and the undesirable example should be identical to the desirable image, except it should include the risk that we want to unlearn.
Post-Training mitigations
These mitigations are applied after the model is finalized and deployed in the production stack. These cover all the mitigations applied on the user input prompt and the final image output.
Prompt filtering
When users input a text prompt to generate an image, or upload an image to modify it using inpainting technique, filters can be applied to block requests asking for harmful content explicitly. At this stage, we address issues where users explicitly provide harmful prompts like “show an image of a person killing another person” or upload an image and ask “remove this person’s clothing” and so on.
For detecting harmful requests and blocking, we can use a simple blocklist based approached with keyword matching, and block all prompts that have a matching harmful keyword (say “suicide”). However, this approach is brittle, and can produce large number of false positives and false negatives. Any obfuscating mechanisms (say, users querying for “suicid3” instead of “suicide”) will fall through with this approach. Instead, an embedding-based CNN filter can be used for harmful pattern recognition by converting the user prompts into embeddings that capture the semantic meaning of the text, and then using a classifier to detect harmful patterns within these embeddings. However, LLMs have been proved to be better for harmful pattern recognition in prompts because they excel at understanding context, nuance, and intent in a way that simpler models like CNNs may struggle with. They provide a more context-aware filtering solution and can adapt to evolving language patterns, slang, obfuscating techniques and emerging harmful content more effectively than models trained on fixed embeddings. The LLMs can be trained to block any defined policy guideline by your organization. Aside from harmful content like sexual imagery, violence, self-injury etc., it can also be trained to identify and block requests to generate public figures or election misinformation related images. To use an LLM based solution at production scale, you’d have to optimize for latency and incur the inference cost.
Prompt manipulations
Before passing in the raw user prompt to model for image generation, there are several prompt manipulations that can be done for enhancing the safety of the prompt. Several case studies are presented below:
Prompt augmentation to reduce stereotypes: LDMs amplify dangerous and complex stereotypes [5] . A broad range of ordinary prompts produce stereotypes, including prompts simply mentioning traits, descriptors, occupations, or objects. For example, prompting for basic traits or social roles resulting in images reinforcing whiteness as ideal, or prompting for occupations resulting in amplification of racial and gender disparities. Prompt engineering to add gender and racial diversity to the user prompt is an effective solution. For example, “image of a ceo” -> “image of a ceo, asian woman” or “image of a ceo, black man” to produce more diverse results. This can also help reduce harmful stereotypes by transforming prompts like “image of a criminal” -> “image of a criminal, olive-skin-tone” since the original prompt would have most likely produced a black man.
Prompt anonymization for privacy: Additional mitigation can be applied at this stage to anonymize or filter out the content in the prompts that ask for specific private individuals information. For example “Image of John Doe from
Prompt rewriting and grounding to convert harmful prompt to benign: Prompts can be rewritten or grounded (usually with a fine-tuned LLM) to reframe problematic scenarios in a positive or neutral way. For example, “Show a lazy [ethnic group] person taking a nap” -> “Show a person relaxing in the afternoon”. Defining a well-specified prompt, or commonly referred to as grounding the generation, enables models to adhere more closely to instructions when generating scenes, thereby mitigating certain latent and ungrounded biases. “Show two people having fun” (This could lead to inappropriate or risky interpretations) -> “Show two people dining at a restaurant”.
Output image classifiers
Image classifiers can be deployed that detect images produced by the model as harmful or not, and may block them before being sent back to the users. Stand alone image classifiers like this are effective for blocking images that are visibly harmful (showing graphic violence or a sexual content, nudity, etc), However, for inpainting based applications where users will upload an input image (e.g., image of a white person) and give a harmful prompt (“give them blackface”) to transform it in an unsafe manner, the classifiers that only look at output image in isolation will not be effective as they lose context of the “transformation” itself. For such applications, multimodal classifiers that can consider the input image, prompt, and output image together to make a decision of whether a transformation of the input to output is safe or not are very effective. Such classifiers can also be trained to identify “unintended transformation” e.g., uploading an image of a woman and prompting to “make them beautiful” leading to an image of a thin, blonde white woman.
Regeneration instead of refusals
Instead of refusing the output image, models like DALL·E 3 uses classifier guidance to improve unsolicited content. A bespoke algorithm based on classifier guidance is deployed, and the working is described in [3]—
When an image output classifier detects a harmful image, the prompt is re-submitted to DALL·E 3 with a special flag set. This flag triggers the diffusion sampling process to use the harmful content classifier to sample away from images that might have triggered it.
Basically this algorithm can “nudge” the diffusion model towards more appropriate generations. This can be done at both prompt level and image classifier level.
Several additional safety measures are typically implemented in the production stack, such as watermarking AI-generated images to trace the content’s origin and enable tracking of misuse. These also include comprehensive monitoring and reporting systems for users to report incidents, allowing for swift resolution of live issues. Serious violations may be disclosed to government authorities (such as NCMEC), and penalties for policy breaches, including account disabling, are enforced to block risky users. Additionally, rate limiting at the application level helps prevent automated or scripted attacks.
Risk discovery and assessment
Aside from the actual mitigations, there are two other important aspects to be considered to ensure safety. One of them is Red-teaming, where teams actively try to find weaknesses, exploits, or unforeseen risks in AI models. Red-teaming simulates real-world attacks and emerging risks, either manually, with the help of expert human red-teamers from different socio-economic, educational and cultural backgrounds or with the help of more scalable, automated systems that are trained to “play the attack”. The other aspect is Benchmarking (or evaluations), where models are run against a standardized set of tests or metrics to evaluate their performance in predefined areas, such as detecting harmful content, handling bias, or maintaining fairness. While red-teaming often uncovers vulnerabilities that benchmarking might miss, making it crucial for discovering unknown risk, benchmarking provides consistent, repeatable evaluations and helps compare models based on established criteria, but may not expose novel risks or vulnerabilities outside the benchmark’s scope. Both these are critical for assessing AI system safety, but they differ in scope and approach.
Here’s a sample of a timeline that shows stages at which red-teaming or evaluations might be carried out. At the minimum, a red-teaming session is carried out once the trained foundation model is ready, to assess the implicit risks in the model. Usually you’d uncover the issues where the model is capable of producing harmful outputs to benign prompts. After those uncovered risks are mitigated at the fine-tuning stage, you’d run comprehensive evaluations to identify any gaps and improve the model further before it is finalized for production. Finally, once the model is deployed in the production stack, you’d run a red-teaming session on the end-to-end system with the entire post-training stack in place, to assess any residual risks that are not covered by the current setup and document them to address either via quick hotfixing, or a more robust longer term strategy. At this stage, you can also run benchmarks to ensure your application meets all the safety, fairness and performance standards before being used by real users and can report these metrics externally.
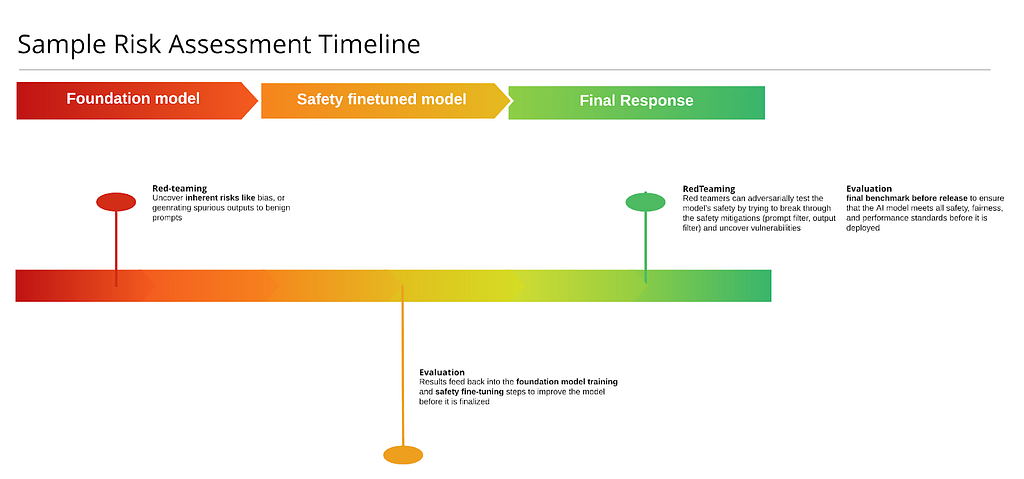
While this is just a minimum guideline, red-teaming and evaluations can be done multiple times across the stack and even on individual components (on just the prompt classifier, image classifier or the rewriter) before finalizing them and making sure the component has high precision and recall.
In conclusion, by implementing comprehensive safeguards throughout the model’s lifecycle — from pre-training to post-training, developers can not only reduce the risks of AI models generating harmful or biased content, but also prevent such content from being surfaced to the end user. Additionally, ongoing practices like red teaming and benchmarking throughout the lifecycle are crucial for discovering and evaluating vulnerabilities, ensuring that AI systems act safe, fair, and responsible in real-world applications.
References
- Multimodal datasets: misogyny, pornography, and malignant stereotypes
- DALLE 2 system card
- DALLE_3 system card
- T-HITL Effectively Addresses Problematic Associations in Image Generation and Maintains Overall Visual Quality
- Easily Accessible Text-to-Image Generation Amplifies Demographic Stereotypes at Large Scale
- Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
Gen-AI Safety Landscape: A Guide to the Mitigation Stack for Text-to-Image Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.










