

Introducing Layer Enhanced Classification (LEC)
A novel approach for lightweight safety classification using pruned language modelsLeveraging the hidden state from an intermediate Transformer layer for efficient and robust content safety and prompt injection classificationImage by author and GPT-4o meant to represent the robust language understanding provided by Large Language Models.IntroductionAs the adoption of Language Models (LMs) grows, it’s more and more important to detect inappropriate content in both the user’s input and the generated outputs of the language model. With each new model release from any major model provider, one of the first things people try to do is find ways to “jailbreak” or otherwise manipulate the model to respond in ways it shouldn’t. A quick search on Google or X reveals many examples of how people have found ways around model alignment tuning to get models to respond to inappropriate requests. Furthermore, many companies have released Generative AI based chatbots publicly for tasks like customer service, which often end up suffering from prompt injection attacks and responding to tasks both inappropriate and far beyond their intended use. Detecting and classifying these instances is extremely important for businesses so that they don’t end up with a system that can be easily manipulated by their users, especially if they deploy their chat systems publicly.My team, Mason Sawtell, Sandi Besen, Jim Brown, and I recently published our paper Lightweight Safety Classification using Pruned Language Models as an ArXiv preprint. Our work introduces a new approach, Layer Enhanced Classification (LEC), and demonstrates that using LEC it is possible to effectively classify both content safety violations and prompt injection attacks by using the hidden state(s) from the intermediate transformer layer(s) of a Language Model to train a penalized logistic regression classifier with very few trainable parameters (769 on the low end) and a small number of training examples, often fewer than 100. This approach combines the computational efficiency of a simple classification model with the robust language understanding of a Language Model.All of the models trained using our approach, LEC, outperform special-purpose models designed for each task as well as GPT-4o. We find that there are optimal intermediate transformer layers that produce the necessary features for both content safety and prompt injection classification tasks. This is important because it suggests you can use the same model to simultaneously classify content safety violations, prompt injections, and generate the output tokens. Alternatively, you could use a very small LM, prune it to the optimal intermediate layer, and use the outputs from this layer as the features for the classification task. This would allow for an incredibly compute efficient and lightweight classifier that integrates well with an existing LM inference pipeline.This is the first of several articles I plan to share on this topic. In this article I will summarize the goals, approach, key results, and implications of our research. In a future article, I plan to share how we applied our approach to IBM’s Granite-8B model and an open-source model without any guardrails, allowing both models to detect content safety & prompt injection violations and generate output tokens all in one pass through the model. For further details on our research feel free to check out the full paper or reach out with questions.Goals & ApproachOverview: Our research focuses on understanding how well the hidden states of intermediate transformer layers perform when used as the input features for classification tasks. We wanted to understand if small general-purpose models and special-purpose models for content safety and prompt injection classification tasks would perform better on these tasks if we could identify the optimal layer to use for the task instead of using the entire model / the last layer for classification. We also wanted to understand how small of a model, in terms of the total number of parameters, we could use as a starting point for this task. Other research has shown that different layers of the model focus on different characteristics of any given prompt input, our work finds that the intermediate layers tend to best capture the features that are most important for these classification tasks.Datasets: For both content safety and prompt injection classification tasks we compare the performance of models trained using our approach to baseline models on task-specific datasets. Previous work indicated our classifiers would only see small performance improvements after a few hundred examples so for both classification tasks we used a task-specific dataset with 5,000 randomly sampled examples, allowing for enough data diversity while minimizing compute and training time. For the content safety dataset we use a combination of the SALAD Data dataset from OpenSafetyLab and the LMSYS-Chat-1M dataset from LMSYS. For the pro

A novel approach for lightweight safety classification using pruned language models
Leveraging the hidden state from an intermediate Transformer layer for efficient and robust content safety and prompt injection classification

Introduction
As the adoption of Language Models (LMs) grows, it’s more and more important to detect inappropriate content in both the user’s input and the generated outputs of the language model. With each new model release from any major model provider, one of the first things people try to do is find ways to “jailbreak” or otherwise manipulate the model to respond in ways it shouldn’t. A quick search on Google or X reveals many examples of how people have found ways around model alignment tuning to get models to respond to inappropriate requests. Furthermore, many companies have released Generative AI based chatbots publicly for tasks like customer service, which often end up suffering from prompt injection attacks and responding to tasks both inappropriate and far beyond their intended use. Detecting and classifying these instances is extremely important for businesses so that they don’t end up with a system that can be easily manipulated by their users, especially if they deploy their chat systems publicly.
My team, Mason Sawtell, Sandi Besen, Jim Brown, and I recently published our paper Lightweight Safety Classification using Pruned Language Models as an ArXiv preprint. Our work introduces a new approach, Layer Enhanced Classification (LEC), and demonstrates that using LEC it is possible to effectively classify both content safety violations and prompt injection attacks by using the hidden state(s) from the intermediate transformer layer(s) of a Language Model to train a penalized logistic regression classifier with very few trainable parameters (769 on the low end) and a small number of training examples, often fewer than 100. This approach combines the computational efficiency of a simple classification model with the robust language understanding of a Language Model.
All of the models trained using our approach, LEC, outperform special-purpose models designed for each task as well as GPT-4o. We find that there are optimal intermediate transformer layers that produce the necessary features for both content safety and prompt injection classification tasks. This is important because it suggests you can use the same model to simultaneously classify content safety violations, prompt injections, and generate the output tokens. Alternatively, you could use a very small LM, prune it to the optimal intermediate layer, and use the outputs from this layer as the features for the classification task. This would allow for an incredibly compute efficient and lightweight classifier that integrates well with an existing LM inference pipeline.
This is the first of several articles I plan to share on this topic. In this article I will summarize the goals, approach, key results, and implications of our research. In a future article, I plan to share how we applied our approach to IBM’s Granite-8B model and an open-source model without any guardrails, allowing both models to detect content safety & prompt injection violations and generate output tokens all in one pass through the model. For further details on our research feel free to check out the full paper or reach out with questions.
Goals & Approach
Overview: Our research focuses on understanding how well the hidden states of intermediate transformer layers perform when used as the input features for classification tasks. We wanted to understand if small general-purpose models and special-purpose models for content safety and prompt injection classification tasks would perform better on these tasks if we could identify the optimal layer to use for the task instead of using the entire model / the last layer for classification. We also wanted to understand how small of a model, in terms of the total number of parameters, we could use as a starting point for this task. Other research has shown that different layers of the model focus on different characteristics of any given prompt input, our work finds that the intermediate layers tend to best capture the features that are most important for these classification tasks.
Datasets: For both content safety and prompt injection classification tasks we compare the performance of models trained using our approach to baseline models on task-specific datasets. Previous work indicated our classifiers would only see small performance improvements after a few hundred examples so for both classification tasks we used a task-specific dataset with 5,000 randomly sampled examples, allowing for enough data diversity while minimizing compute and training time. For the content safety dataset we use a combination of the SALAD Data dataset from OpenSafetyLab and the LMSYS-Chat-1M dataset from LMSYS. For the prompt injection dataset we use the SPML dataset since it includes system and user prompt pairs. This is critical because some user requests might seem “safe” (e.g., “help me solve this math problem”) but they ask the model to respond outside of the system’s intended use as defined in the system prompt (e.g. “You are a helpful AI assistant for Company X, you only respond to questions about our company”).
Model Selection: We use GPT-4o as a baseline model for both tasks since it is widely considered one of the most capable LLMs and in some cases outperformed the baseline special-purpose model(s). For content safety classification we use Llama Guard 3 1B and 8B models and for prompt injection classification we use Protect AI’s DeBERTA v3 Base Prompt Injection v2 model since these models are considered leaders in their respective areas. We apply our approach, LEC, to the baseline special purpose models (Llama Guard 3 1B, Llama Guard 3 8B, and DeBERTa v3 Base Prompt Injection) and general-purpose models. For general-purpose models we selected Qwen 2.5 Instruct in sizes 0.5B, 1.5B, and 3B since these models are relatively close in size to the special-purpose models.
This setup allows us to compare 3 key things:
- How well our approach performs when applied to a small general-purpose model compared to both baseline models (GPT-4o and the special-purpose model).
- How much applying our approach improves the performance of the special-purpose model relative to its own baseline performance on that task.
- How well our approach generalizes across model architectures, by evaluating its performance on both general-purpose and
special-purpose models.
Important Implementation Details: For both Qwen 2.5 Instruct models and task-specific special-purpose models we prune individual layers and capture the hidden state of the transformer layer to train a Penalized Logistic Regression (PLR) model with L2 regularization. The PLR model has the same number of trainable parameters as the size of the model’s hidden state plus one for the bias in binary classification tasks, this ranges from 769 for the smallest model (Protect AI’s DeBERTa) to 4097 for the largest model (Llama Guard 3 8B). We train the classifier with varying numbers of examples for each layer allowing us to understand the impact of individual layers on the task and how many training examples are necessary to surpass the baseline models’ performance or achieve optimal performance in terms of F1 score. We run our entire test set through the baseline models to establish their performance on each task.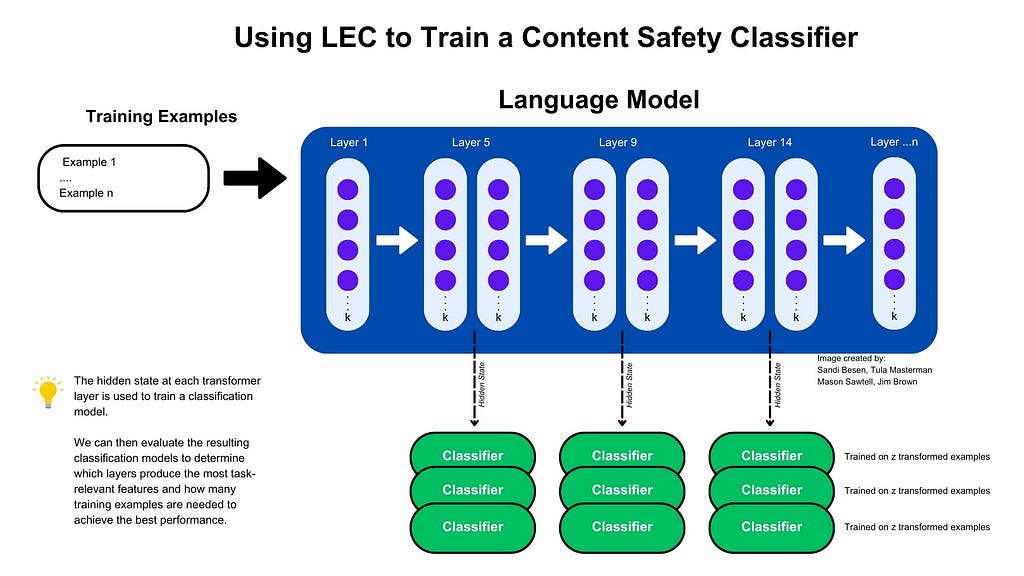
Key Results
In this section I’ll cover the important results across both tasks and for each task, content safety classification and prompt injection classification, individually.
Key findings across both tasks:
- Overall, our approach results in a higher F1 score across all evaluated tasks, models, and number of of training examples, typically surpassing baseline model performance within 20–100 examples.
- The intermediate layers tend to show the largest improvement in F1 score compared to the final layer when trained on fewer examples. These layers also tend to have the best performance relative to the baseline models. This indicates that local features important to both classification tasks are represented early on in the transformer network and suggests that use cases with fewer training examples can especially benefit from our approach.
- Furthermore, we found that applying our approach to the special-purpose models outperforms the models own baseline performance, typically within 20 examples, by identifying and using the most task-relevant layer.
- Both general-purpose Qwen 2.5 Instruct models and task-specific special-purpose models achieve higher F1 scores within fewer examples with our approach. This suggests that our approach generalizes across architectures and domains.
- In the Qwen 2.5 Instruct models, we find that the intermediate model layers attain higher F1 scores with fewer examples for both content safety and prompt injection classification tasks. This suggests that it’s feasible to use one model for both classification tasks and generate the outputs in one pass. The additional compute time for these extra classification steps would be almost negligible given the small size of the classifiers.
Content safety classification results: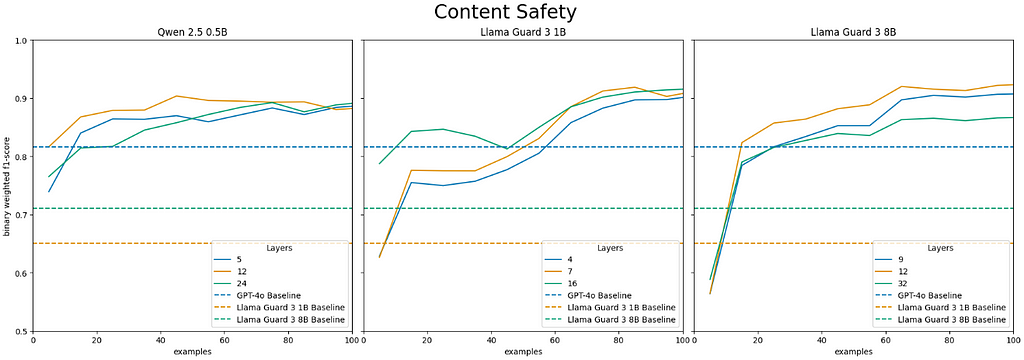
- For both binary and multi-class classification, the general and special purpose models trained using our approach typically outperform the baseline Llama Guard 3 models within 20 examples and GPT-4o in fewer than 100 examples.
- For both binary and multi-class classification, the general and special purpose LEC models typically surpass all baseline models performance for the intermediate layers if not all layers. Our results on binary content safety classification surpass the baselines by the widest margins attaining maximum F1-scores of 0.95 or 0.96 for both Qwen 2.5 Instruct and Llama Guard LEC models. In comparison, GPT-4o’s baseline F1 score is 0.82, Llama Guard 3 1B’s is 0.65 , and Llama Guard 3 8B’s is 0.71.
- For binary classification our approach performs comparably when applied to Qwen 2.5 Instruct 0.5B, Llama Guard 3 1B, and Llama Guard 3 8B. The models attain a maximum F1 score of 0.95, 0.96, and 0.96 respectively. Interestingly, Qwen 2.5 Instruct 0.5B surpasses GPT-4o’s baseline performance in 15 examples for the middle layers while it takes both Llama Guard 3 models 55 examples to do so.
- For multi-class classification, a very small LEC model using the hidden state from the middle layers of Qwen 2.5 Instruct 0.5B surpasses GPT-4o’s baseline performance within 35 training examples for all three difficulty levels of the multi-class classification task.
Prompt injection classification results: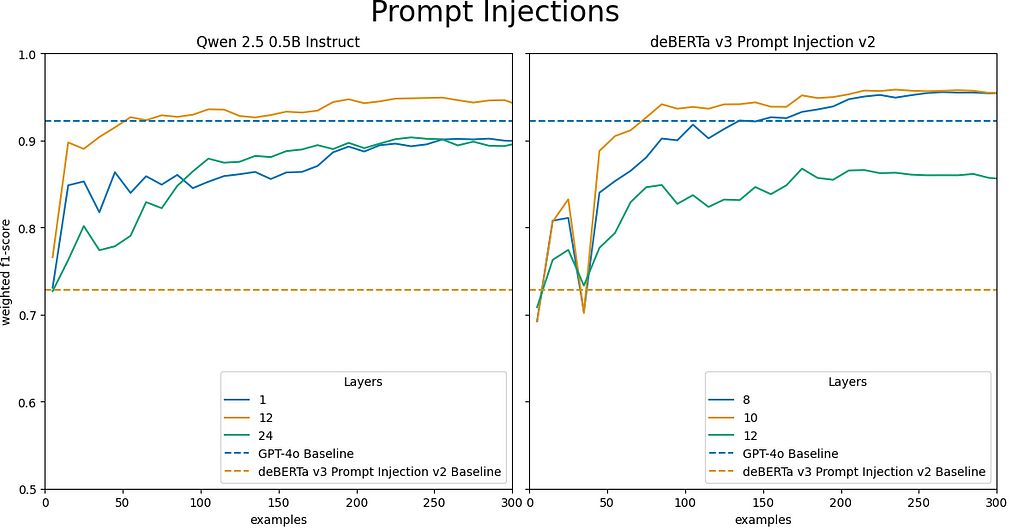
- Applying our approach to both general-purpose Qwen 2.5 Instruct models and special-purpose DeBERTa v3 Prompt Injection v2 results in both models intermediate layers outperforming the baseline models in fewer than 100 training examples. This again indicates that our approach generalizes across model architectures and domains.
- All three Qwen 2.5 Instruct model sizes surpass the baseline DeBERTa v3 Prompt Injection v2 model’s F1 score of 0.73 within 5 training examples for all model layers.
- Qwen 2.5 Instruct 0.5B surpasses GPT-4o’s performance for the middle layer, layer 12 in 55 examples. Similar, but slightly better performance is observed for the larger Qwen 2.5 Instruct models.
- Applying our approach to the DeBERTa v3 Prompt Injection v2 model results in a maximum F1 score of 0.98, significantly surpassing the model’s baseline performance F1 score of 0.73 on this task.
- The intermediate layers achieve the highest weighted F1 scores for both the DeBERTa model and across Qwen 2.5 Instruct model sizes.
Conclusion
In our research we focused on two responsible AI related classification tasks but expect this approach to work for other classification tasks provided that the important features for the task can be detected by the intermediate layers of the model.
We demonstrated that our approach of training a classification model on the hidden state from an intermediate transformer layer creates effective content safety and prompt injection classification models with minimal parameters and training examples. Furthermore, we illustrated how our approach improves the performance of existing special-purpose models compared to their own baseline results.
Our results suggest two promising options for integrating top-performing content safety and prompt injection classifiers into existing LLM inference workflows. One option is to take a lightweight small model like the ones explored in our paper, prune it to the optimal layer and use it as a feature extractor for the classification task. The classification model could then be used to identify any content safety violations or prompt injections before processing the user input with a closed-source model like GPT-4o. The same classification model could be used to validate the generated response before sending it to the user. A second option is to apply our approach to an open-source, general-purpose model, like IBM’s Granite or Meta’s Llama models, identify which layers are most relevant to the classification task, then update the inference pipeline to simultaneously classify content safety and prompt injections while generating the output response. If content safety or prompt injections are detected you could easily stop the output generation, otherwise if there are no violations, the model can continue generating it’s response. Either of these options could be extended to apply to AI-agent based scenarios depending on the model used for each agent.
In summary, LEC provides a new promising and practical solution to safeguarding Generative AI based systems by identifying content safety and prompt injection attacks with better performance and fewer training examples compared to existing approaches. This is critical for any person or business building with Generative AI today to ensure their systems are operating both responsibly and as intended.
Note: The opinions expressed both in this article and the research paper are solely those of the authors and do not necessarily reflect the views or policies of their respective employers.
Interested in discussing further or collaborating? Reach out on LinkedIn!
Additional References:
- Lightweight Safety Classification Using Pruned Language Models (see full references section in our paper on ArXiv)
- OpenSafetyLab’s SALAD Dataset
- LMSYS’ LMSYS-Chat-1M Dataset
- SPML: A DSL for Defending Language Models Against Prompt Injection Attacks
- Qwen 2.5 0.5B Instruct on HuggingFace
- Llama Guard 3 Model Cards on Meta
- ProtectAI’s DeBERTa v3 Prompt Injection v2 on HuggingFace
- Large Language Models are Overparameterized Text Encoders
- Logistic Regression makes small LLMs strong and explainable “tens-of-shot” classifiers
Introducing Layer Enhanced Classification (LEC) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.










