

Slow Thinking with LLMs: Lessons from Imitation, Exploration, and Self-Improvement
Reasoning systems such as o1 from OpenAI were recently introduced to solve complex tasks using slow-thinking processes. However, it is clear that large language models have limitations, as they cannot plan, break down problems, improve ideas, summarize, or rethink due to their training and methods. While these tools try to enhance reasoning, they depend on […] The post Slow Thinking with LLMs: Lessons from Imitation, Exploration, and Self-Improvement appeared first on MarkTechPost.



Reasoning systems such as o1 from OpenAI were recently introduced to solve complex tasks using slow-thinking processes. However, it is clear that large language models have limitations, as they cannot plan, break down problems, improve ideas, summarize, or rethink due to their training and methods. While these tools try to enhance reasoning, they depend on structured guidance and extra processing time, raising doubts about their ability to handle complex tasks without regular human help.
Current methods in reasoning systems are mostly based on fast-thinking approaches, thus providing quick responses but with less depth and accuracy. The industry has mostly developed and maintained these systems, but their core techniques are not disclosed publicly. They usually fail in extended thinking, thus considerably limiting their ability to solve complex problems. Methods like tree search and reward models were used in some systems, but they were not very effective in generalizing across domains or were too slow for real-world use. New systems used test-time scaling to give more time for processing and generating detailed reasoning steps called thoughts to find solutions. Fine-tuning large language models with long chains of thought has also improved performance on complex tasks.
To solve this, researchers from the Gaoling School of Artificial Intelligence, Renmin University of China, and BAAI proposed a solution that involves a three-phase framework called “imitate, explore, and self-improve” to enhance reasoning in language models. Researchers presented a three-phase training method—imitation, exploration, and self-improvement—for developing reasoning models similar to OpenAI’s o1 system.
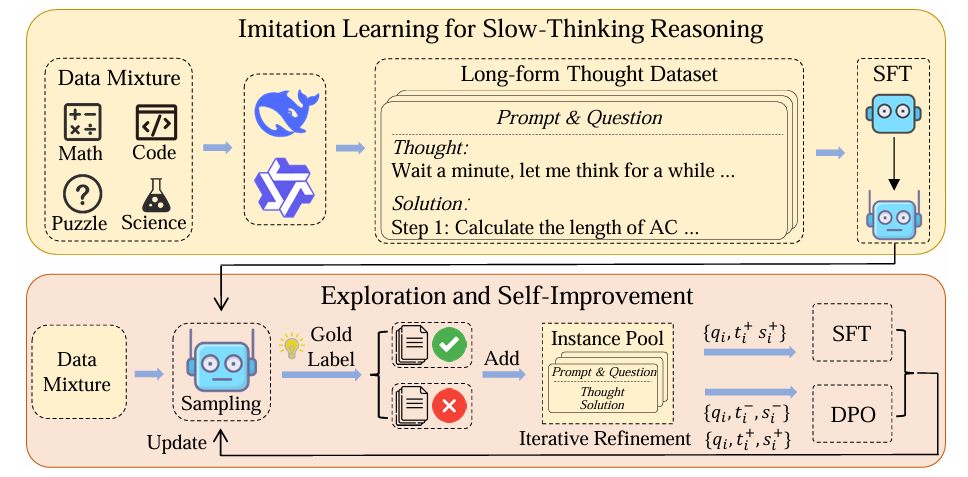
The model was trained to follow specific formats in the imitation phase, using minimal data to generate reasoning and solutions. During the exploration phase, the model focused on difficult problems, developing multiple solutions and improving them based on the correct answers, especially for tasks requiring slow thinking. In the self-improvement phase, high-quality data and techniques like supervised fine-tuning (SFT) and direct preference optimization (DPO) were used to boost the model’s reasoning skills. Metrics like length and perplexity helped filter out low-quality data. However, there weren’t enough challenging problems, and reinforcement learning wasn’t used due to limited resources. The approach focused on improving the model’s reasoning abilities through continuous refinement.
Researchers evaluated the framework using three challenging benchmarks: MATH-OAI, AIME2024, and GPQA. MATH-OAI included 500 competition mathematics problems, AIME2024 featured 30 issues for high school students, and GPQA had 198 multiple-choice questions in biology, physics, and chemistry. The focus was on mathematics, with Qwen2.5-32B-Instruct as the backbone model, compared to models like o1-preview, DeepSeek-R1-LitePreview, and QwQ-32B. The experiments used a greedy search with up to 32k tokens.
Results showed that slow-thinking systems like o1-preview performed well, particularly on AIME, while distillation and exploration-based training also yielded competitive outcomes. Models with 3.9k instances from distillation achieved 90.2% accuracy on MATH-OAI and 46.7% on AIME. Iterative SFT and exploration training improved performance on benchmarks like AIME and MATH-OAI, with variants trained on 1.1k instances showing consistent gains. However, performance fluctuated due to limited exploration capacity, especially on AIME, which had fewer test samples. The analysis indicated that excluding hard problems reduced performance while mixing mathematical and other domain data enhanced reasoning abilities. Further DPO analysis showed that aligning only the thought process with SFT led to stable optimization, although more experiments were needed to refine the strategies. This maintained a good balance of iterative training, distillation, and exploration strategies to support improvement across all the benchmarks.
In summary, the researchers presented a slow-thinking framework for enhancing reasoning systems, demonstrating its effectiveness in solving complex problems across domains. Based on training with high-quality, long-form thought data, the approach enables models to generalize and handle difficult tasks, particularly in mathematics. The system benefits from self-improvement through exploration and flexible thought processes. However, the research is still in its early stages, and there remains a gap in performance compared to industry-level systems. In the future, this domain can be developed, and this framework can act as a baseline for upcoming researchers!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Slow Thinking with LLMs: Lessons from Imitation, Exploration, and Self-Improvement appeared first on MarkTechPost.










