

What are Hallucinations in LLMs and 6 Effective Strategies to Prevent Them
In large language models (LLMs), “hallucination” refers to instances where models generate semantically or syntactically plausible outputs but are factually incorrect or nonsensical. For example, a hallucination occurs when a model provides erroneous information, such as stating that Addison’s disease causes “bright yellow skin” when, in fact, it causes fatigue and low blood pressure. This […] The post What are Hallucinations in LLMs and 6 Effective Strategies to Prevent Them appeared first on MarkTechPost.



In large language models (LLMs), “hallucination” refers to instances where models generate semantically or syntactically plausible outputs but are factually incorrect or nonsensical. For example, a hallucination occurs when a model provides erroneous information, such as stating that Addison’s disease causes “bright yellow skin” when, in fact, it causes fatigue and low blood pressure. This phenomenon is a significant concern in AI, as it can lead to the spread of false or misleading information. The issue of AI hallucinations has been explored in various research studies. A survey in “ACM Computing Surveys” describes hallucinations as “unreal perceptions that feel real.” Understanding and mitigating hallucinations in AI systems is crucial for their reliable deployment. Below are six ways discussed to prevent hallucinations in LLMs:
Use High-Quality Data
The use of high-quality data is one simple-to-do thing. The data that trains an LLM serves as its primary knowledge base, and any shortcomings in this dataset can directly lead to flawed outputs. For instance, when teaching a model to provide medical advice, a dataset that lacks comprehensive coverage of rare diseases might result in the model generating incorrect or incomplete responses to queries on these topics. By using datasets that are both broad in scope and precise in detail, developers can minimize the risks associated with missing or incorrect data. Structured data is important in this process, as it provides a clear and organized framework for the AI to learn from, unlike messy or unstructured data, which can lead to ambiguities.
Employ Data Templates
With data quality, implementing data templates offers another layer of control and precision. Data templates are predefined structures that specify the expected format and permissible range of responses for a given task. For example, in financial reporting, a template might define the fields required for a balance sheet, such as assets, liabilities, and net income. This approach ensures that the model adheres to domain-specific requirements and also helps maintain consistency across outputs. Templates safeguard against generating irrelevant or inaccurate responses by strictly adhering to predefined guidelines.
Parameter Tuning
Another effective method for reducing hallucinations is parameter tuning. By adjusting key inference parameters, developers can fine-tune the behavior of an LLM to better align with specific tasks. Parameters such as temperature, frequency, and presence penalty allow granular control over the model’s output characteristics. For creative applications like poetry or storytelling, a higher temperature setting might be used to introduce randomness and creativity. Conversely, a lower temperature for technical or factual outputs can help ensure accuracy and consistency. Fine-tuning these parameters enables the model to strike the right balance between creativity and reliability.
Practice Prompt Engineering
Prompt engineering is also a valuable tool for mitigating hallucinations. This method involves crafting well-thought-out prompts that guide the model to produce relevant outputs. Developers can improve the quality of their responses by providing clear instructions and sample questions and assigning specific roles to the AI. For instance, when querying the model about the economic impact of inflation, a prompt like “As a financial expert, explain how inflation affects interest rates” sets clear expectations for the type of response required.
Retrieval-Augmented Generation (RAG)
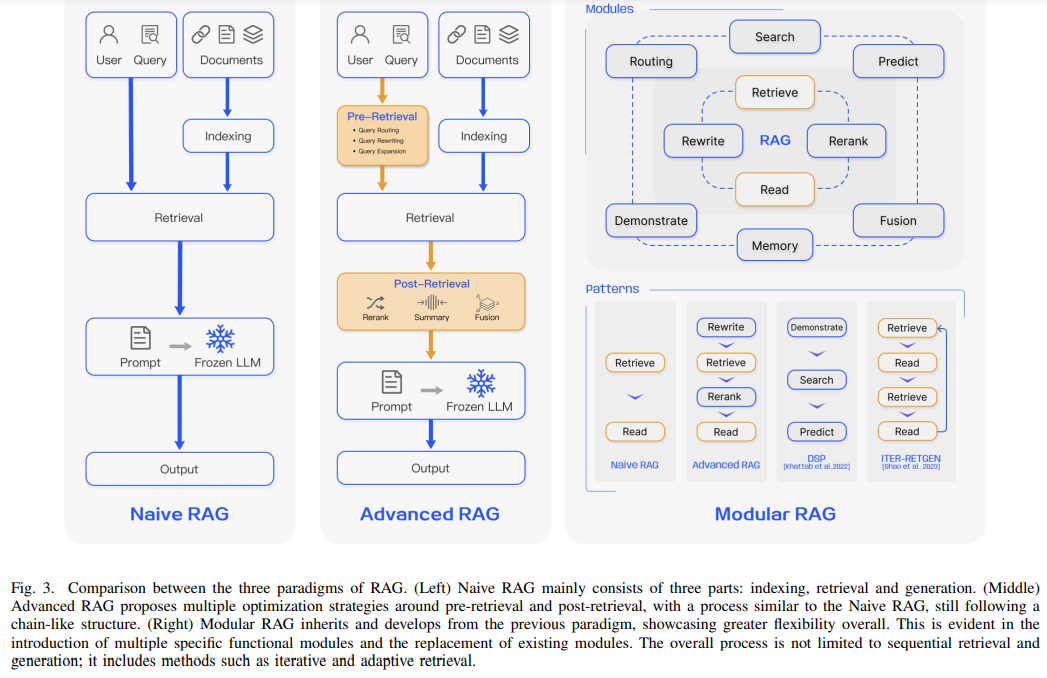
RAG represents a more advanced technique for ensuring the accuracy of LLM outputs. RAG combines the generative capabilities of an AI model with external knowledge sources, such as databases or curated documents. This integration allows the model to ground its responses in factual, domain-specific information rather than relying solely on its training data. For example, a customer support chatbot equipped with RAG can reference a product manual to answer user queries precisely. By incorporating external knowledge, RAG reduces the influence of training data biases and ensures that the model’s outputs are accurate and relevant to the context.
Human Fact Checking
Human oversight remains an indispensable part of preventing hallucinations in LLMs. Human fact-checkers play a critical role in reviewing AI-generated content to identify and correct inaccuracies that the model might miss. This layer of review is important in high-stakes scenarios, such as news generation or legal document drafting, where factual errors can have significant consequences. For example, in a news generation system, human editors can verify the facts presented by the AI before publication, thereby preventing the dissemination of false information. Also, the feedback provided by human reviewers can be used to refine the model’s training data, further improving its accuracy over time.
Hence, these are some of the benefits of reducing Hallucinations in LLMs:
- Minimizing hallucinations ensures that AI systems produce outputs that users can trust, increasing reliability across critical applications like healthcare and legal domains.
- Accurate and consistent outputs foster confidence among users, encouraging broader adoption of AI technologies.
- Reducing hallucinations prevents misinformation in domains such as finance or medicine, enabling professionals to make informed decisions based on accurate AI-generated insights.
- Reducing hallucinations aligns AI systems with ethical guidelines by preventing the spread of false or misleading information.
- Accurate AI responses reduce the need for human review and corrections, saving time and resources in operational workflows.
- Addressing hallucinations improves training data and model development, leading to AI research and technology advancements.
- Trustworthy AI systems can be deployed in more sensitive, high-stakes environments where accuracy is non-negotiable.
In conclusion, these six strategies address a specific aspect of the hallucination problem, offering a comprehensive framework for mitigating risks. High-quality data ensures that the model has a reliable foundation to build upon, while data templates provide a structured guide for consistent outputs. Parameter tuning allows for customized responses tailored to different applications, and prompt engineering enhances the clarity and relevance of queries. RAG introduces an additional layer of factual grounding by integrating external knowledge sources, and human oversight serves as the ultimate safeguard against errors.
Sources
Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post What are Hallucinations in LLMs and 6 Effective Strategies to Prevent Them appeared first on MarkTechPost.










