

Deep Learning and Vocal Fold Analysis: The Role of the GIRAFE Dataset
Semantic segmentation of the glottal area from high-speed videoendoscopic (HSV) sequences presents a critical challenge in laryngeal imaging. The field faces a significant shortage of high-quality, annotated datasets for training robust segmentation models. Therefore, the development of automatic segmentation technologies is hindered by this limitation and the creation of diagnostic tools such as Facilitative Playbacks […] The post Deep Learning and Vocal Fold Analysis: The Role of the GIRAFE Dataset appeared first on MarkTechPost.



Semantic segmentation of the glottal area from high-speed videoendoscopic (HSV) sequences presents a critical challenge in laryngeal imaging. The field faces a significant shortage of high-quality, annotated datasets for training robust segmentation models. Therefore, the development of automatic segmentation technologies is hindered by this limitation and the creation of diagnostic tools such as Facilitative Playbacks (FPs) that are crucial in assessing vibratory dynamics in vocal folds. The limited availability of extensive datasets is a challenge to clinicians while trying to make an accurate diagnosis and proper treatment of voice disorders, generating a vast void in both research works and clinical practices.
Current techniques for glottal segmentation include the classical image processing techniques, which include active contours and watershed transformations. Most of these techniques generally require a considerable amount of manual input and cannot cope with varying illumination conditions or complex scenarios of glottis closure. On the other hand, deep learning models, although promising, are limited by the need for large and high-quality annotated datasets. Datasets like BAGLS, which are available publicly, provide grayscale recordings, but they are less diverse and granular, which in turn reduces their generalization ability for complex segmentation tasks. These factors underline the urgent need for a dataset that offers better versatility, more complex features, and broader clinical relevance.
Researchers from the University of Brest, University of Patras, and Universidad Politécnica de Madrid introduce the GIRAFE dataset to address the limitations of existing resources. GIRAFE is a robust and comprehensive repository comprising 65 HSV recordings from 50 patients, each meticulously annotated with segmentation masks. In contrast to other datasets, the advantage of GIRAFE is that it offers color HSV recordings, which makes subtle anatomical and pathological features visually detectable. This resource enables researchers to make high-resolution assessments involving classical segmentation approaches, such as InP and Loh, and the recent deep neural architectures, such as UNet and SwinUnetV2. Apart from high-resolution segmentation, this work also facilitates Facilitative Playbacks, including GAW, GVG, and PVG, which are the most important media through which vibratory modal patterns in the vocal fold could be visualized to learn more about vocal-fold phonatory dynamics.
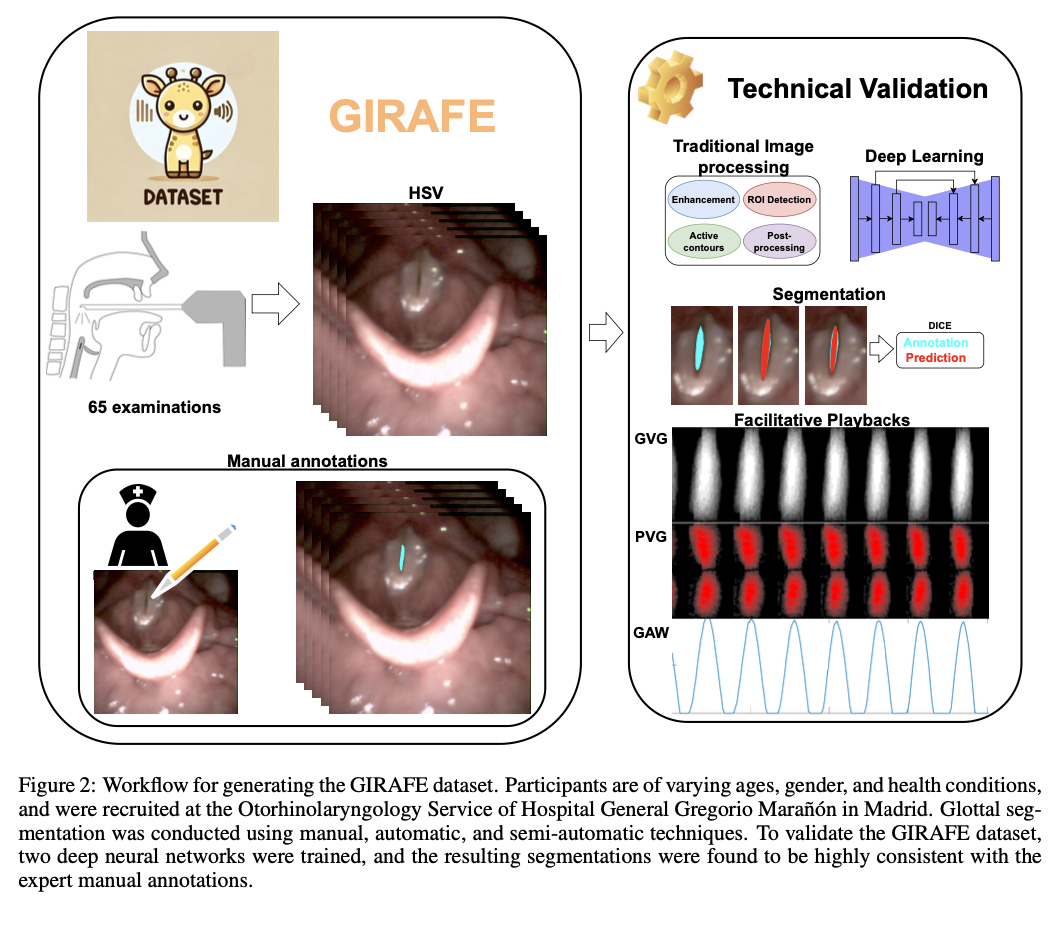
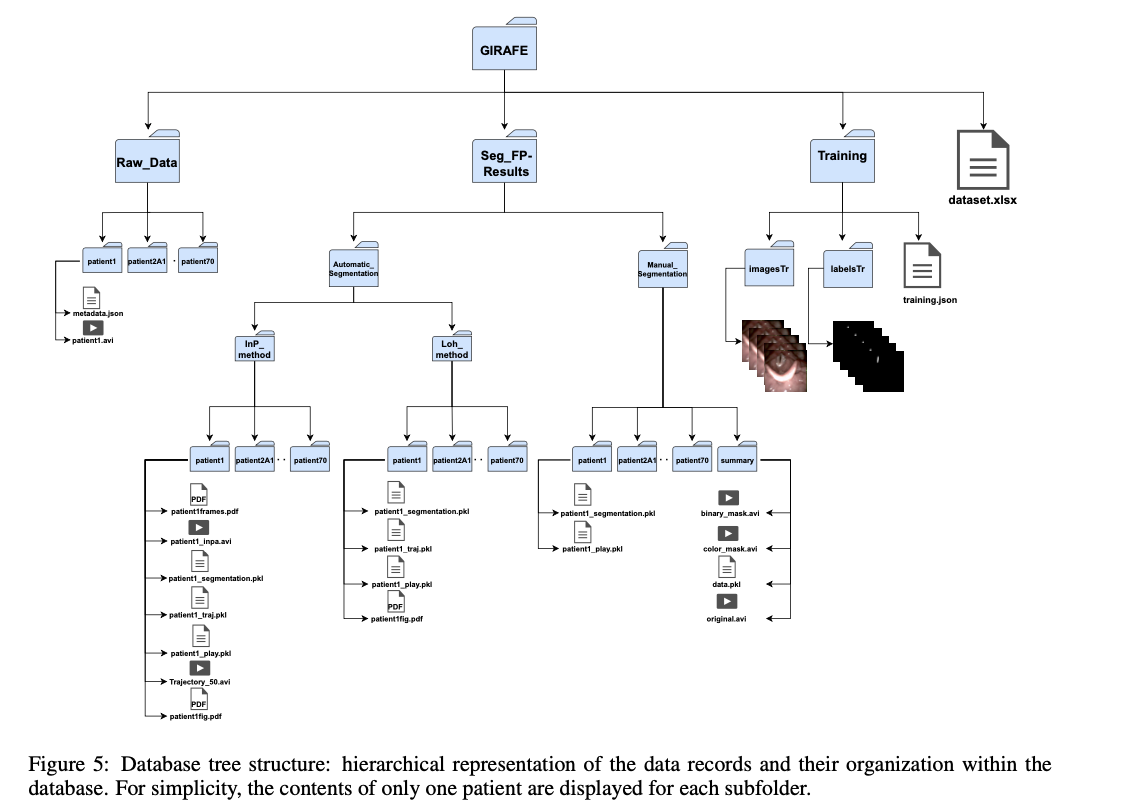
The GIRAFE dataset comprises highly extensive features suitable for a wide variety of research. It comprises 760 frames expert-validated and annotated; such a setup allows for proper training and evaluation using correct segmentation masks. This dataset incorporates both traditional image processing techniques such as InP and Loh and also advanced deep learning architectures. HSV recordings are captured at a high temporal resolution of 4000 frames per second with a spatial resolution of 256×256 pixels, ensuring detailed analysis of vocal fold dynamics. The dataset is organized into structured directories, including \\Raw_Data, \\Seg_FP-Results, and \\Training, facilitating ease of access and integration into research pipelines. This combination of systematic arrangement with color recordings makes it easier to view glottal characteristics and allows the exploration of complex vibratory patterns in a wide range of clinical conditions.
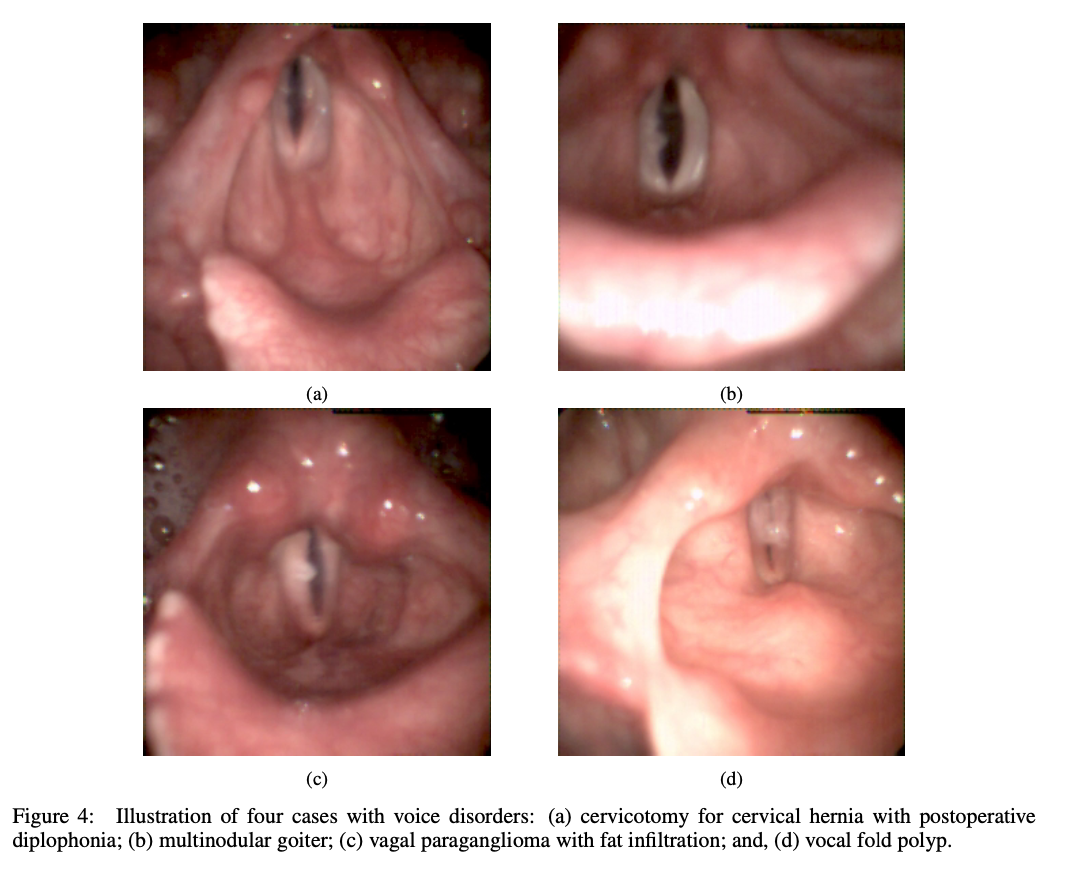
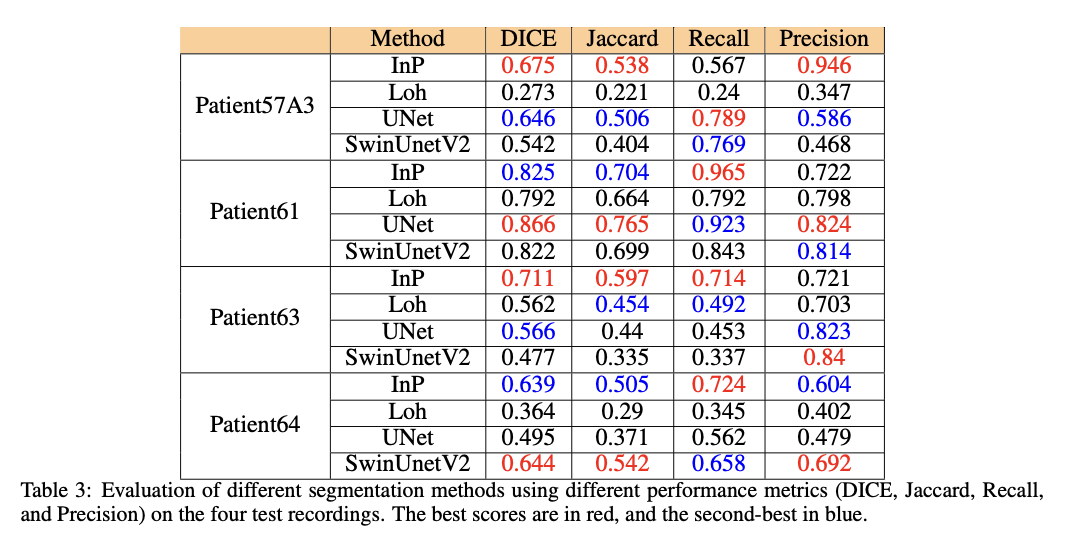
The GIRAFE dataset showed its efficiency in the further advancement of segmentation techniques with full validation using both traditional approaches and deep learning. Traditional segmentation techniques, such as the InP method, performed well across different challenging cases, indicating that they are robust and can handle complex cases. Deep learning models like UNet and SwinUnetV2 have also demonstrated good performance; however, UNet outperformed the others in segmentation accuracy in simpler conditions. The diversity of the dataset, containing various pathologies, illumination conditions, and anatomical variations, made it a benchmark resource. These results confirm that the dataset can contribute to improved development and assessment of segmentation methods and support innovation in clinical laryngeal imaging applications.
The GIRAFE dataset represents an important milestone in the landscape of laryngeal imaging research. With its inclusion of color HSV recordings, diverse annotations, and the integration of both traditional and deep learning methodologies, this dataset addresses the limitations inherent in the current datasets and sets a new benchmark within the domain. This dataset helps further bridge traditional and modern approaches while providing a dependable basis for the advancement of sophisticated segmentation methods and diagnostic instruments. Its contributions can potentially change the examination and management of voice disorders, and thus, it would be a great source for clinicians and researchers alike looking to advance the field of vocal fold dynamics and related diagnostics.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Deep Learning and Vocal Fold Analysis: The Role of the GIRAFE Dataset appeared first on MarkTechPost.










