

GraphAide: Building and Utilizing Knowledge Graphs for Domain-Specific Digital Assistants
Large Language Models (LLMs) have revolutionized artificial intelligence applications across various fields, enabling domain experts to use pre-trained models for innovative solutions. While LLMs excel at tasks like summarization, correlation, and inference, developing LLM-based applications remains a dynamic area of research across various input sources. Knowledge Graphs (KGs) serve as powerful tools that can be […] The post GraphAide: Building and Utilizing Knowledge Graphs for Domain-Specific Digital Assistants appeared first on MarkTechPost.



Large Language Models (LLMs) have revolutionized artificial intelligence applications across various fields, enabling domain experts to use pre-trained models for innovative solutions. While LLMs excel at tasks like summarization, correlation, and inference, developing LLM-based applications remains a dynamic area of research across various input sources. Knowledge Graphs (KGs) serve as powerful tools that can be used in diverse user environments as foundational reference knowledge sources. However, their construction poses substantial challenges due to data scale, concept heterogeneity, and resource requirements. A critical challenge in LLM applications is hallucination, the generation of non-existent facts that arise from the models’ memorization of training data, and reliance on corpus-based heuristics.
Existing approaches mainly focus on specific applications, with Retrieval-Augmented Generation (RAG) as a baseline method. RAG transforms unstructured data into embedded chunks stored in vector databases, using semantic similarity matching to retrieve relevant context for LLM queries. While this approach addresses hallucination and outdated knowledge issues, its reliance on semantic similarity limits its effectiveness. Advanced methods like GraphRAG employ query-focused summarization and community detection for global answer generation, and other approaches focus on specialized tasks such as sustainability-related KG creation and causal graph extraction. However, these methods have limited extensibility and fail to leverage modern open-source development frameworks.
Researchers from the Pacific Northwest National Laboratory have proposed GraphAide, an advanced LLM-based capability that offers insights into domain-specific data and allows users to ask natural language questions. GraphAide introduces a comprehensive methodology and reference architecture to integrate GenAI with semantic web technologies through a modular and extensible RAG approach. Moreover, it combines vector and graph databases to overcome the limitations of traditional LLM applications using ontology-guided knowledge graphs. GraphAide’s extensible agentic architecture ensures the reusability of components throughout the application lifecycle.
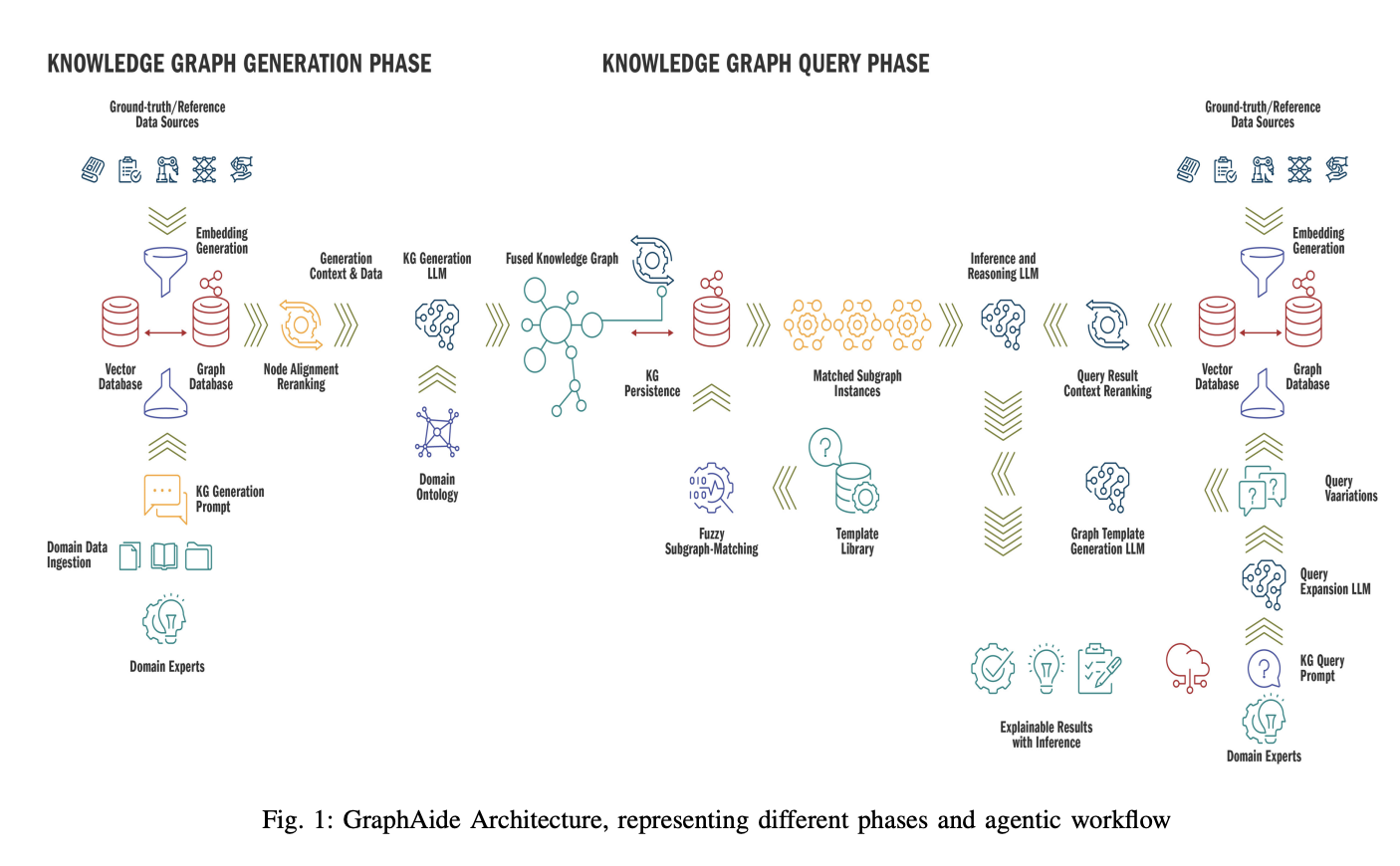
GraphAide’s architecture combines agentic and chain-based approaches to create a complex RAG system that utilizes multiple LLM instances for diverse tasks. Unlike traditional chain-based systems with hardcoded instructions, GraphAide’s agentic components can dynamically interpret LLM responses and construct subsequent queries. The system operates in distinct phases:
- A curation phase that integrates multi-source information to build a comprehensive Knowledge Graph alongside a vector database.
- An exploration phase that provides an interactive interface for knowledge querying.
This dual-phase architecture enables users to access information through natural language queries while receiving formatted responses with detailed explanations and reasoning paths.
GraphAide processes 1,846 news articles and generates a KG using an ontology-guided and WikiData-based disambiguation agent. This method shows superior results if compared to basic RAG approaches through its hybrid RAG methodology, offering enhanced specificity and cross-document inference capabilities. The generated KG shows improved Named Entity Recognition (NER) and relation extraction quality compared to baseline approaches. Moreover, GraphAide achieves a more balanced and diverse distribution of node types, overcoming the common issue of node type imbalance often seen in baseline KGs where “PER” (person) types typically dominate. It also excels in extracting event-based edge types, which are beneficial for temporal event representation in the input data.
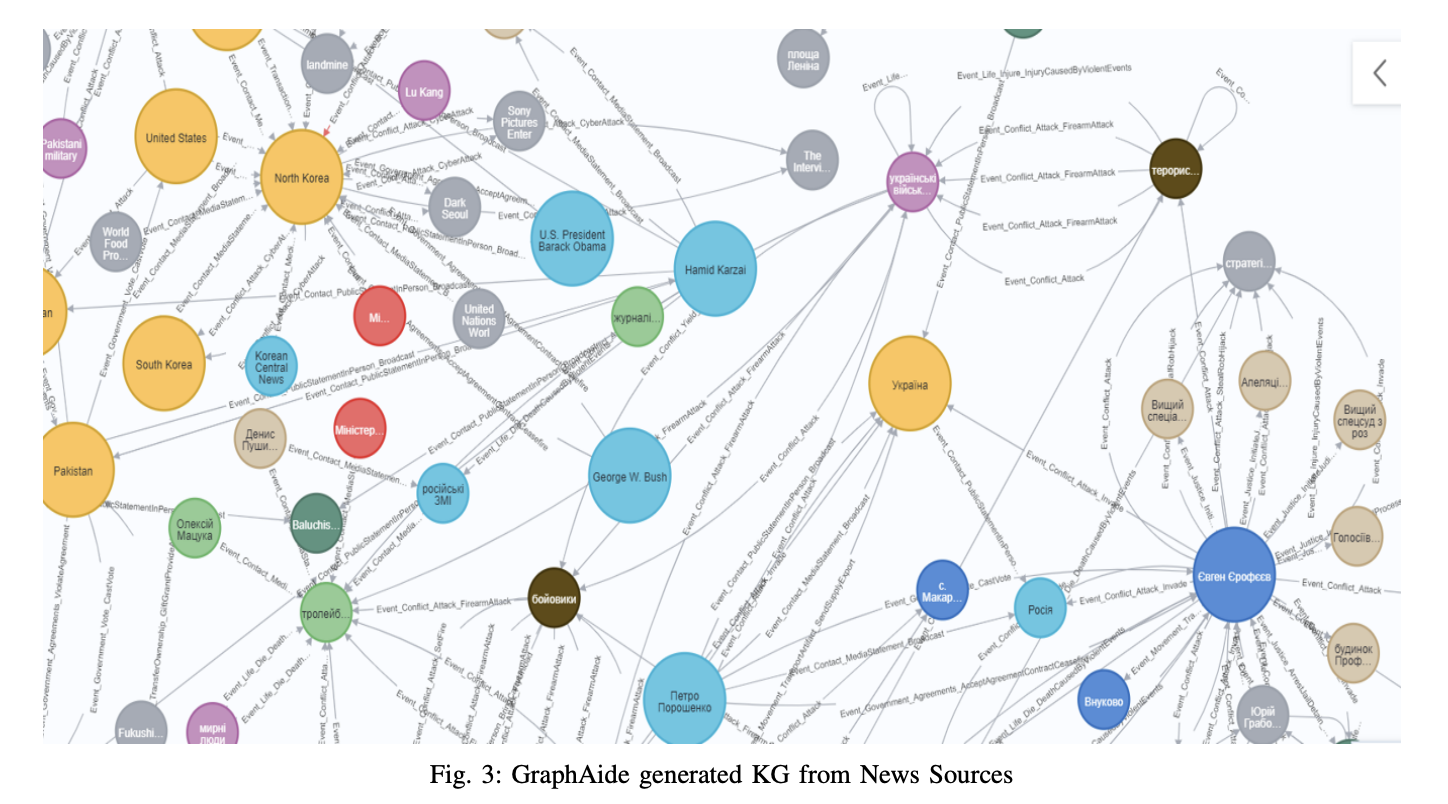
In conclusion, researchers introduced GraphAide, which represents a significant advancement in the utilization of LLMs for domain-specific digital assistants. Its innovative approach combines KG capabilities with advanced RAG techniques to enhance accuracy, explainability, and user confidence in LLM applications. GraphAide effectiveness is demonstrated through its application to the Ukraine-Russian political conflict scenario, where it successfully generated comprehensive KGs from news articles. While initial results are promising, future work will focus on formal quantitative evaluation metrics, particularly in accuracy and relevancy areas to further validate the system’s improvements over existing approaches.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
The post GraphAide: Building and Utilizing Knowledge Graphs for Domain-Specific Digital Assistants appeared first on MarkTechPost.










