

Meet ONI: A Distributed Architecture for Simultaneous Reinforcement Learning Policy and Intrinsic Reward Learning with LLM Feedback
Reward functions play a crucial role in reinforcement learning (RL) systems, but their design presents significant challenges in balancing task definition simplicity with optimization effectiveness. The conventional approach of using binary rewards offers a straightforward task definition but creates optimization difficulties due to sparse learning signals. While intrinsic rewards have emerged as a solution to […] The post Meet ONI: A Distributed Architecture for Simultaneous Reinforcement Learning Policy and Intrinsic Reward Learning with LLM Feedback appeared first on MarkTechPost.



Reward functions play a crucial role in reinforcement learning (RL) systems, but their design presents significant challenges in balancing task definition simplicity with optimization effectiveness. The conventional approach of using binary rewards offers a straightforward task definition but creates optimization difficulties due to sparse learning signals. While intrinsic rewards have emerged as a solution to aid policy optimization, their crafting process requires extensive task-specific knowledge and expertise, placing substantial demands on human experts who must carefully balance multiple factors to create reward functions that accurately represent the desired task and enable efficient learning.
Recent approaches have utilized Large Language Models (LLMs) to automate reward design based on natural language task descriptions, following two main methodologies. The first approach focuses on generating reward function codes through LLMs, which has shown success in continuous control tasks. However, this method faces limitations as it requires access to environment source code or detailed parameter descriptions and struggles with processing high-dimensional state representations. The second approach involves generating reward values directly through LLMs, exemplified by methods like Motif, which ranks observation captions using LLM preferences. However, it requires pre-existing captioned observation datasets and involves a time-consuming three-stage process.
Researchers from Meta, the University of Texas Austin, and UCLA have proposed ONI, a novel distributed architecture that simultaneously learns RL policies and intrinsic reward functions using LLM feedback. The method uses an asynchronous LLM server to annotate the agent’s collected experiences, which are then transformed into an intrinsic reward model. The approach explores various algorithmic methods for reward modeling, including hashing, classification, and ranking models, to investigate their effectiveness in addressing sparse reward problems. This unified methodology achieves superior performance in challenging sparse reward tasks within the NetHack Learning Environment, operating solely on the agent’s gathered experience without requiring external datasets.
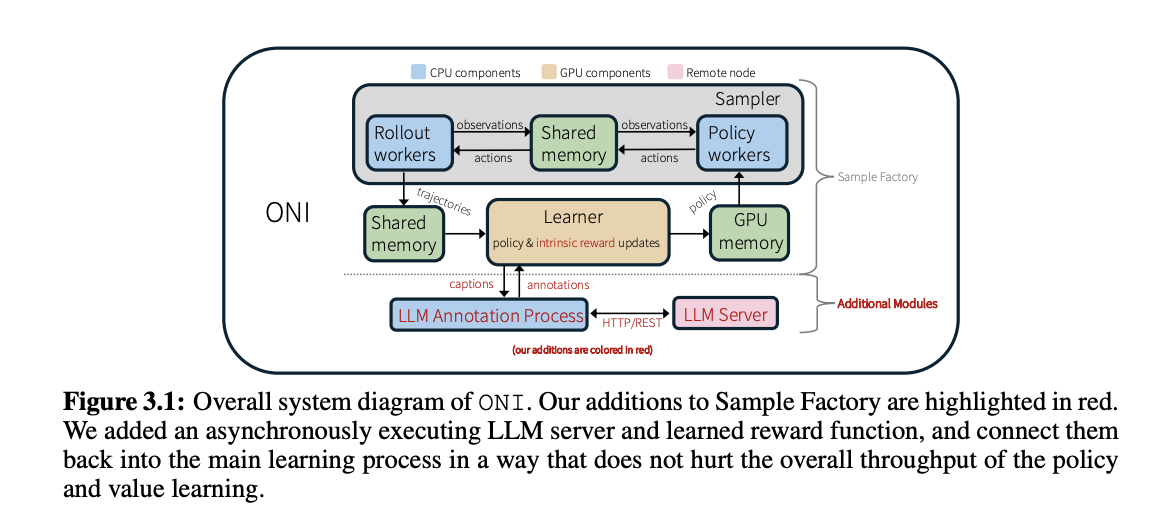
ONI uses several key components built upon the Sample Factory library and its asynchronous variant proximal policy optimization (APPO). The system operates with 480 concurrent environment instances on a Tesla A100-80GB GPU with 48 CPUs, achieving approximately 32k environment interactions per second. The architecture incorporates four crucial components: an LLM server on a separate node, an asynchronous process for transmitting observation captions to the LLM server via HTTP requests, a hash table for storing captions and LLM annotations, and a dynamic reward model learning code. This asynchronous design maintains 80-95% of the original system throughput, processing 30k environment interactions per second without reward model training and 26k interactions when training a classification-based reward model.
The experimental results demonstrate significant performance improvements across multiple tasks in the NetHack Learning Environment. While the extrinsic reward agent performs adequately on the dense Score task, it fails on sparse reward tasks. ‘ONI-classification’ matches or approaches the performance of existing methods like Motif across most tasks, achieving this without pre-collected data or additional dense reward functions. Among ONI variants, ‘ONI-retrieval’ shows strong performance, while ‘ONI-classification’ consistently improves through its ability to generalize to unseen messages. Moreover, the ‘ONI-ranking’ achieves the highest experience levels, while ‘ONI-classification’ leads in other performance metrics in reward-free settings.
In this paper, researchers introduced ONI which represents a significant advancement in RL by introducing a distributed system that simultaneously learns intrinsic rewards and agent behaviors online. It shows state-of-the-art performance across challenging sparse reward tasks in the NetHack Learning Environment while eliminating the need for pre-collected datasets or auxiliary dense reward functions that were previously essential. This work establishes a foundation for developing more autonomous intrinsic reward methods that can learn exclusively from agent experience, operate independently of external dataset constraints, and effectively integrate with high-performance reinforcement learning systems.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Meet ONI: A Distributed Architecture for Simultaneous Reinforcement Learning Policy and Intrinsic Reward Learning with LLM Feedback appeared first on MarkTechPost.










