

Meta AI Researchers Introduce Token-Level Detective Reward Model (TLDR) to Provide Fine-Grained Annotations for Large Vision Language Models
Vision Language Models (VLMs) have demonstrated remarkable capabilities in generating human-like text in response to images, with notable examples including GPT-4, Gemini, PaLiGemma, LLaVA, and Llama 3 Vision models. However, these models frequently generate hallucinated content that lacks proper grounding in the reference images, highlighting a critical flaw in their output reliability. The challenge of […] The post Meta AI Researchers Introduce Token-Level Detective Reward Model (TLDR) to Provide Fine-Grained Annotations for Large Vision Language Models appeared first on MarkTechPost.



Vision Language Models (VLMs) have demonstrated remarkable capabilities in generating human-like text in response to images, with notable examples including GPT-4, Gemini, PaLiGemma, LLaVA, and Llama 3 Vision models. However, these models frequently generate hallucinated content that lacks proper grounding in the reference images, highlighting a critical flaw in their output reliability. The challenge of detecting and preventing such hallucinations necessitates effective reward models (RMs) for evaluation and improvement. Current binary classification-based RMs provide only single-score evaluations for entire outputs, severely limiting their interpretability and granularity. This coarse evaluation approach masks the underlying decision-making process, making it difficult for developers to identify specific areas of improvement and implement targeted enhancements in VLM performance.
Previous attempts to improve VLM performance have primarily focused on Reinforcement Learning from Human Feedback (RLHF) techniques, which have successfully enhanced language models like ChatGPT and LLaMA 3. These approaches typically involve training reward models on human preference data and using algorithms like Proximal Policy Optimization (PPO) or Direct Policy Optimization (DPO) for policy learning. While some advancements have been made with process reward models and step-wise reward models, existing solutions for detecting hallucinations are predominantly limited to the language domain and operate at sentence-level granularity. Alternative approaches have explored synthetic data generation and hard negative mining through human annotation, heuristic-based methods, and hybrid approaches combining automatic generation with manual verification. However, these methods have not adequately addressed the core challenge of representing and evaluating visual features in VLMs, which remains a significant bottleneck in developing more reliable vision-language foundation models.
Researchers from Meta and the University of Southern California have introduced The Token-Level Detective Reward (TLDR) model, representing a breakthrough in evaluating VLM outputs by providing token-by-token assessment rather than single-score evaluations. This granular approach enables precise identification of hallucinations and errors within the generated text, making it particularly valuable for human annotators who can quickly identify and correct specific problematic segments. TLDR addresses the inherent bias of binary reward models, which tend to favor longer texts regardless of hallucination content, by incorporating robust visual grounding mechanisms. Through careful integration of multimodal cues and enhanced visual feature projection techniques, the model achieves significantly improved performance in detecting content misalignment. The system’s architecture facilitates seamless integration with existing model improvement methods like DPO and PPO, while simultaneously serving as a likelihood training objective that enhances the underlying vision language model’s performance.

The TLDR model operates on multimodal query-response instances consisting of an image, user text prompt, and text response. Unlike traditional reward models that produce binary classifications, TLDR evaluates each token in the response individually, generating a score between 0 and 1 based on a threshold θ (typically 0.5). The model’s performance is evaluated using three distinct accuracy metrics: token-level accuracy for individual token assessment, sentence-level accuracy for evaluating coherent text segments, and response-level accuracy for overall output evaluation. To address data scarcity and granularity issues, the system employs sophisticated synthetic data generation techniques, particularly focusing on dense captioning and visual question-answering tasks. The training data is enhanced through a systematic perturbation process using large language models, specifically targeting eight key taxonomies: spatial relationships, visual attributes, attribute binding, object identification, counting, small object detection, text OCR, and counterfactual scenarios. This comprehensive approach ensures robust evaluation across diverse visual-linguistic challenges.
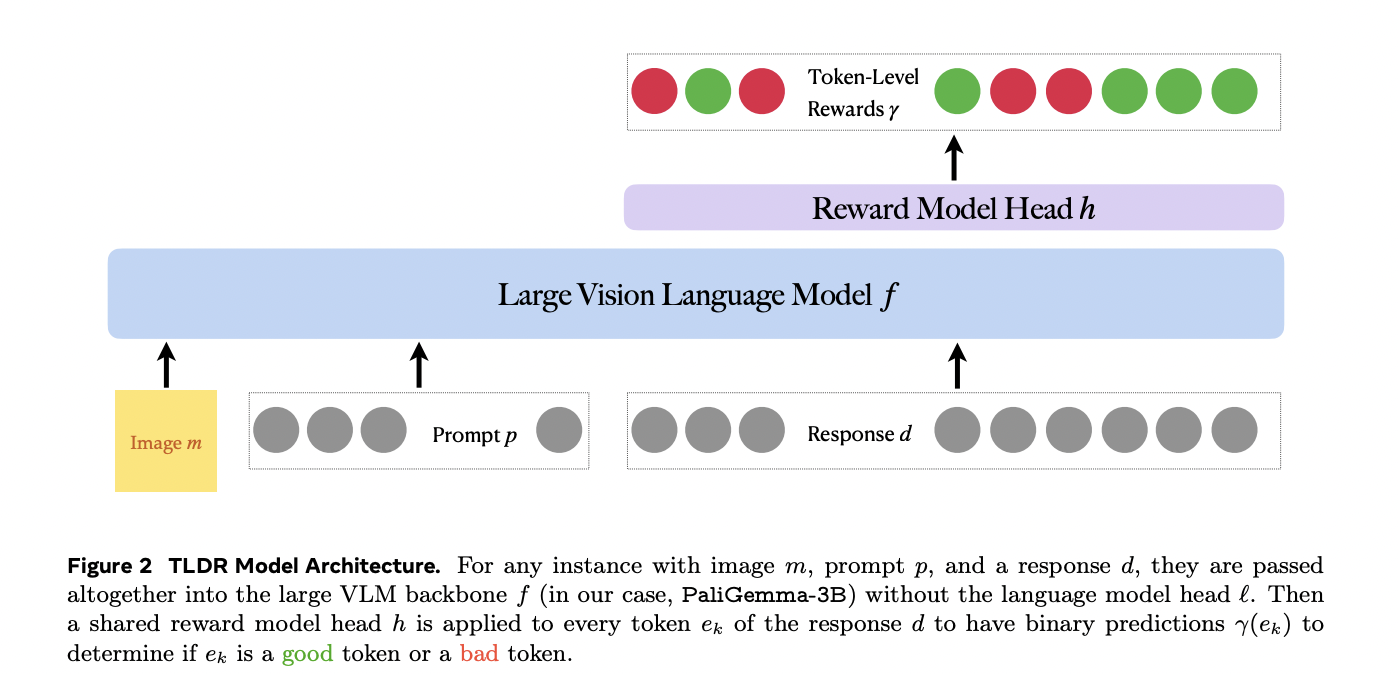
The TLDR model demonstrates robust performance across multiple evaluation metrics when tested on synthetic data from the DOCCI dataset. Performance analysis reveals slightly superior response-level accuracy compared to traditional binary reward models, achieving a notable 41.3 mAP(neg) score. Detailed taxonomy breakdown indicates particular challenges with spatial relationship assessments, aligning with known limitations in current VLM technologies. Human evaluation of token-level predictions on WinoGround images, focusing specifically on false negatives, shows a modest sentence-level false negative rate of 8.7%. In practical applications, TLDR’s effectiveness is demonstrated through comprehensive hallucination detection across various leading VLMs, including Llama-3.2-Vision, GPT-4 variants, MiniCPM, PaLiGemma, and Phi 3.5 Vision. GPT-4o emerges as the top performer with minimal hallucination rates across all granularity levels. The model’s utility extends to real-world applications, as evidenced by its analysis of PixelProse dataset, where it identified hallucinated tokens in 22.39% of captions, with token-level and sentence-level hallucination rates of 0.83% and 5.23% respectively.

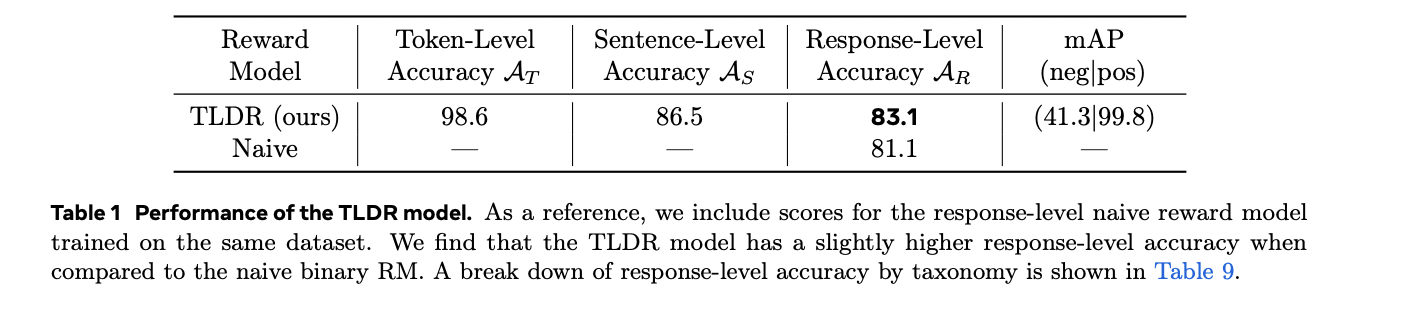
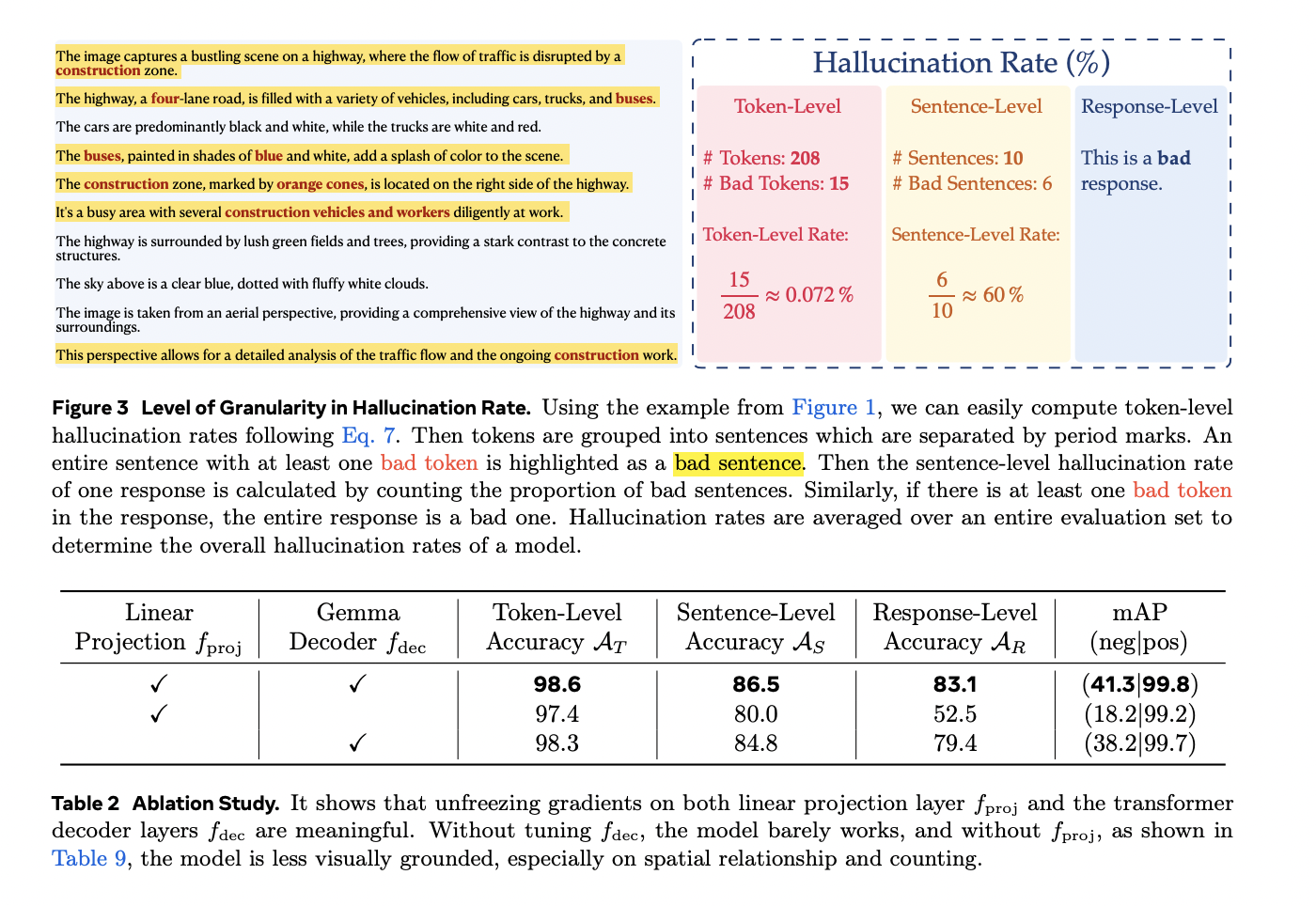

The Token-Level Detective Reward Model represents a significant advancement in evaluating and improving vision language models through its fine-grained token-level annotation capabilities. Beyond simply identifying errors, TLDR pinpoints specific problematic areas, enabling efficient self-correction and hallucination detection. The model’s effectiveness extends to practical applications, serving as a likelihood optimization method and facilitating faster human annotation processes. This innovative approach establishes a foundation for advanced token-level DPO and PPO post-training methodologies, marking a crucial step forward in VLM development.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Meta AI Researchers Introduce Token-Level Detective Reward Model (TLDR) to Provide Fine-Grained Annotations for Large Vision Language Models appeared first on MarkTechPost.










