

MIRAGE-Bench: An Automatic Multilingual Benchmark for Retrieval-Augmented Generation Systems
Large Language Models (LLMs) have emerged as crucial tools for handling intricate information-seeking queries due to techniques that improve both retrieval and response generation. Retrieval-augmented generation (RAG) is a well-known framework in this area that has drawn a lot of interest since it can produce responses that are more accurate and pertinent to the context. […] The post MIRAGE-Bench: An Automatic Multilingual Benchmark for Retrieval-Augmented Generation Systems appeared first on MarkTechPost.


Large Language Models (LLMs) have emerged as crucial tools for handling intricate information-seeking queries due to techniques that improve both retrieval and response generation. Retrieval-augmented generation (RAG) is a well-known framework in this area that has drawn a lot of interest since it can produce responses that are more accurate and pertinent to the context. In RAG systems, an LLM creates a response based on the recovered content after a retrieval step in which pertinent information or passages are gathered. By connecting comments to particular passages, this arrangement enables LLMs to cite sources, which helps minimize false information or hallucinations and makes verification simpler and more trustworthy.
One well-known RAG system is Microsoft’s Bing Search, which improves response reliability to the referred content by incorporating retrieval and grounding techniques to cite sources. However, because of unequal access to high-quality training data in non-English languages, existing RAG models are mostly focused on English, which limits their usefulness in multilingual environments. The effectiveness of LLMs in multilingual RAG settings, where both the questions and the answers are in languages other than English, such as Hindi, is still unknown.
There are two primary types of benchmarks used to assess RAG systems. The initial, heuristic-based benchmarks evaluate models in a number of dimensions using a combination of computational measures. Despite being reasonably priced, these standards still rely on human tastes as a gold truth for comparison, and it might be difficult to determine a clear ranking between models.
The second kind, known as arena-based benchmarks, uses a high-performance LLM as a teacher to evaluate model outputs through direct model comparisons in a setting akin to a competition. However, this method can be costly and computationally demanding, especially when comparing a large number of models in-depth, as is the case when evaluating 19 models using OpenAI’s GPT-4o, which can be very costly.
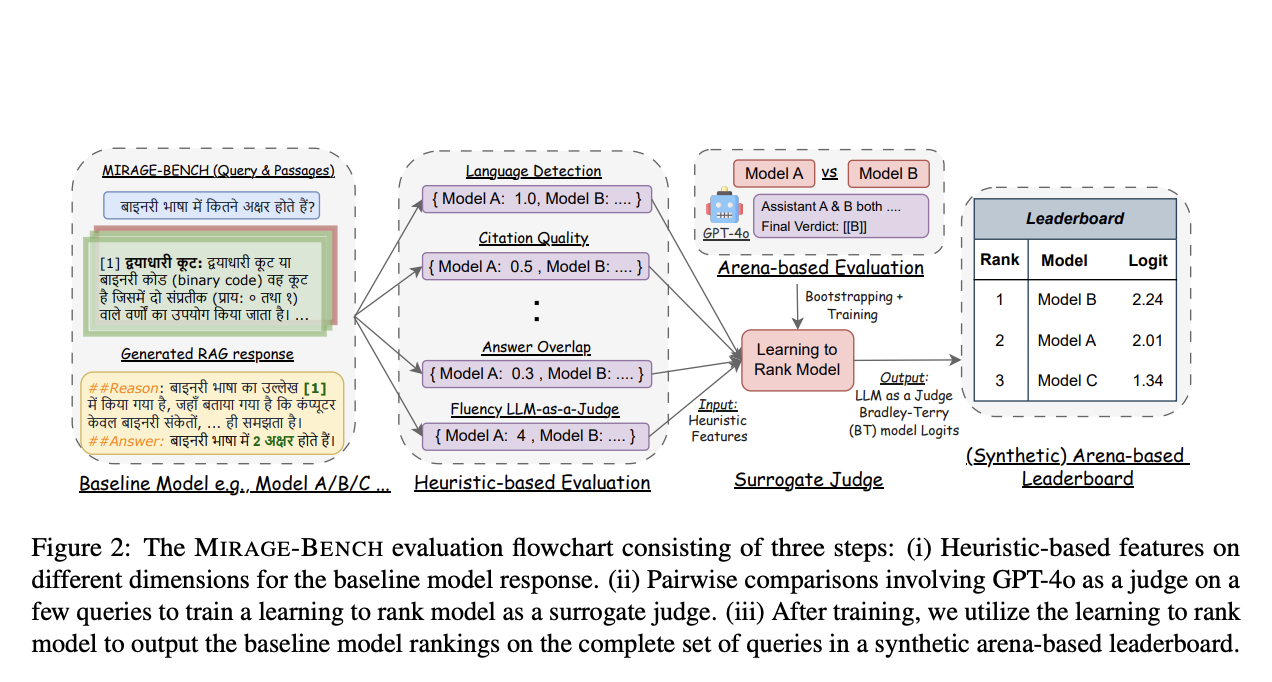
A team of researchers from the University of Waterloo and VECTARA propose a new framework called MIRAGE-BENCH to solve the limitations of both approaches. It uses a more economical method to analyze multilingual generation across 18 languages. This unique benchmark has been created by utilizing a retrieval dataset known as MIRACL, which includes pertinent Wikipedia sections for training as well as human-curated questions. MIRAGE-BENCH uses seven essential heuristic factors, including fluency, citation quality, and language detection, among others, to assess the caliber and applicability of responses produced by LLM. GPT-4o judges a smaller sample of multilingual inquiries in situations where more accurate assessments are required.
In order to function as a surrogate judge, MIRAGE-BENCH also incorporates Machine Learning techniques by building a random forest model. Heuristic characteristics and the Bradley-Terry model, a statistical technique frequently used in ranking, are used to train this learning-to-rank model. Without requiring a costly LLM judge each time, the trained machine can then produce a synthetic leaderboard for scoring multilingual LLMs. In addition to saving money, this procedure enables the leaderboard to adjust to new or altered evaluation standards. The team has shared that according to experimental data, MIRAGE-BENCH’s methodology regularly places large-scale models at the top and closely matches the pricey GPT-4o-based leaderboards, obtaining a high correlation score.
By using data generated under the direction of high-performing models like GPT-4o, MIRAGE-BENCH has been demonstrated to be advantageous for smaller LLMs, such as ones with 7-8 billion parameters. The efficiency and scalability of multilingual RAG benchmarks are eventually improved by this surrogate evaluation methodology, opening the door for more thorough and inclusive evaluations of LLMs in a variety of languages.
The team has shared their primary contributions as follows.
- The establishment of MIRAGE-BENCH, which is a benchmark created especially to promote multilingual RAG research and helps in multilingual development.
- A trainable learning-to-rank model has been used as a surrogate judge to combine heuristic-based measures with an arena-style leaderboard, successfully striking a balance between computing efficiency and accuracy.
- The advantages and disadvantages of 19 multilingual LLMs have been discussed in terms of their generation capacities in multilingual RAG.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post MIRAGE-Bench: An Automatic Multilingual Benchmark for Retrieval-Augmented Generation Systems appeared first on MarkTechPost.










